-
圣诞快乐!Ruby 如何用一句循环实现多个循环? at December 26, 2018
来个 Pg 版
WITH rows(i) AS ( SELECT generate_series(0,5) UNION ALL SELECT generate_series(2,8) UNION ALL SELECT generate_series(3,12) UNION ALL SELECT unnest(array[2,2,2,2]) ) SELECT repeat(' ', (40- 2*i - i/2)) || repeat('*', (4*i + 1 + i)) AS tree FROM rows; -
拼写检查的四种实现 at December 23, 2018
和敏感词过滤差不多啊 不过敏感词过滤还需要去噪之类
-
Let's clone a Leancloud at December 21, 2018

-
It's never too late to learn Postgres at December 13, 2018
zombodb 不错
-
一招秒杀 N+1 agg 问题 at December 13, 2018
select 的时候 COALESCE 一下或自己判断都可以
-
It's never too late to learn Postgres at December 09, 2018
算 BaaS 了吧
-
It's never too late to learn Postgres at December 07, 2018
MySQL 是 web 2.0 时代的产物啊,LAMP 标配,不过新项目的话,pg 还是最佳选择。
-
图解 Unicorn 工作原理 at December 07, 2018
你说的是 mongrel 的作者吧
-
It's never too late to learn Postgres at December 07, 2018
最近在写,一个大概的提纲:
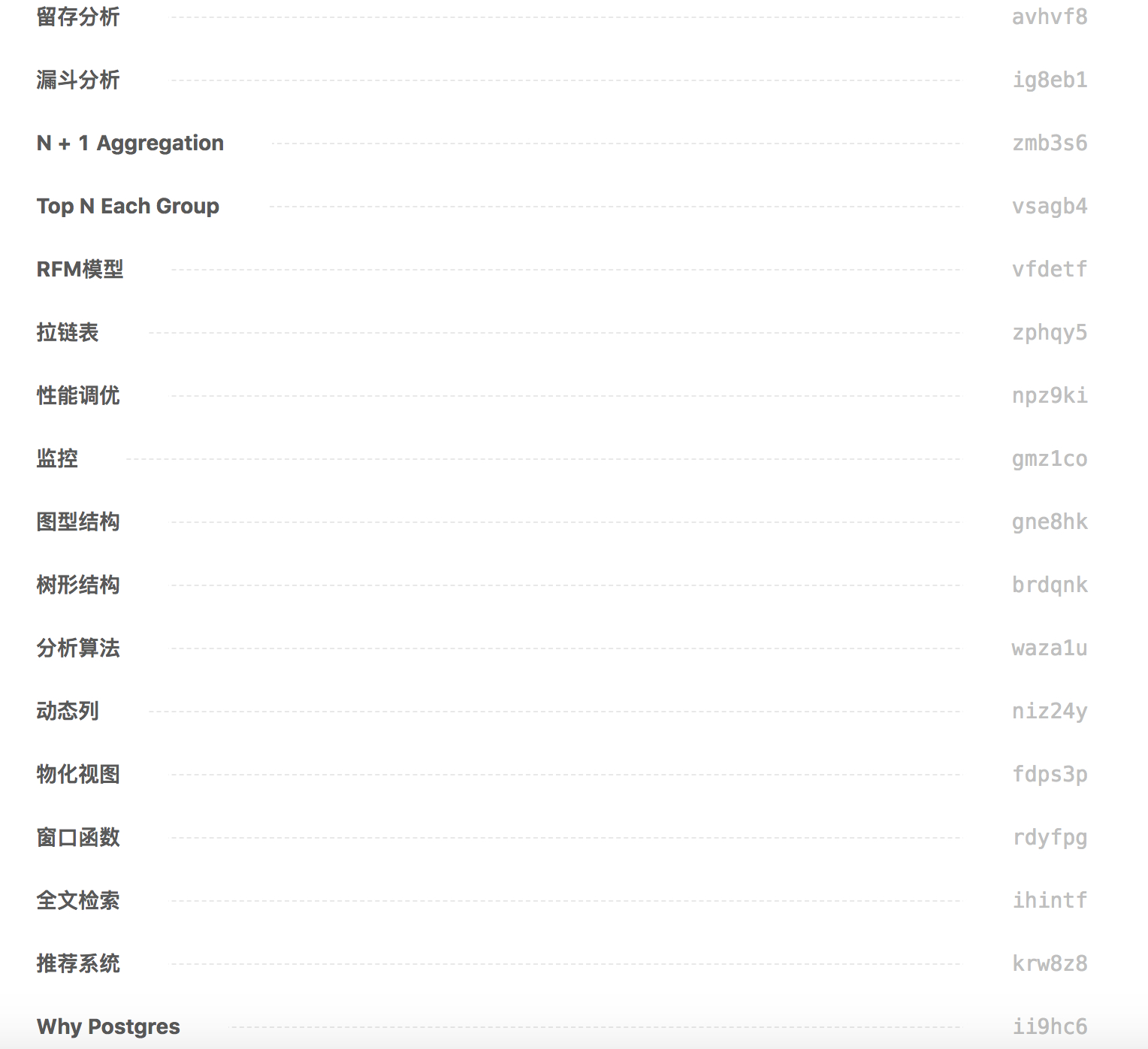
-
It's never too late to learn Postgres at December 04, 2018
买过,看你想入门还是已经有经验了,有经验了的话不建议买。
-
数据库中小数的字段类型慎用 float at November 28, 2018
protip: 存 decimal,app 端比较用 to_d
-
It's never too late to learn Postgres at November 27, 2018
aws 还有一个 aurora 看起来很厉害:https://aws.amazon.com/cn/rds/aurora/
-
It's never too late to learn Postgres at November 25, 2018
Managed DB 问题就是预装 extension 有限,这方面做的好的是阿里云 RDS,预装 extension 非常全,可能和他们自己也在使用有关吧
-
It's never too late to learn Postgres at November 25, 2018
牛油果对标的应该是芒果吧,对自己发明一套查询语法的 DB 没好感,要学的太多,记不住...
-
It's never too late to learn Postgres at November 25, 2018
-
It's never too late to learn Postgres at November 24, 2018
great

-
It's never too late to learn Postgres at November 24, 2018
不一定是 sql 写模型,可以 plpython plr 结合的,你可以参考下 madlib 的源码,但使用的时候少了导入导出和 ETL 部分,过滤的话 sql 本身就替代了 pandas
-
It's never too late to learn Postgres at November 24, 2018
用了快两年了吧,主要自己看看文档和相关领域专家的 blog 吧
-
It's never too late to learn Postgres at November 24, 2018
那就 2019 咯
-
做个小小的调查,有多少用 Rails 做服务器后端 API 的? at November 21, 2018
最近在用,灰常棒,已经回不去 REST 了
-
mysql 为什么不走索引? at November 16, 2018
建议用 https://www.db-fiddle.com 把信息帖全
-
2O at November 16, 2018
each_with_index
-
一招秒杀 N+1 agg 问题 at November 11, 2018
因为你的条件有 deleted at,要加符合索引,我试过没问题的,你看我上一个回帖后面的结果。
-
一招秒杀 N+1 agg 问题 at November 10, 2018
可以试试 把 left join 改成 LEFT JOIN LATERAL,加个条件 OrderItem.where("orders.id = order_items.order_id").group
SELECT orders.*, aggs.* FROM "orders" LEFT JOIN LATERAL (SELECT order_id, COUNT(*) AS items_count FROM "order_items" WHERE "order_items"."deleted_at" IS NULL AND (orders.id = order_items.order_id) GROUP BY "order_items"."order_id") AS aggs ON aggs.order_id = orders.id ORDER BY id desc;Sort (cost=31853.46..31862.86 rows=3759 width=344) (actual time=26.134..26.694 rows=3759 loops=1) Sort Key: orders.id DESC Sort Method: quicksort Memory: 2035kB -> Nested Loop Left Join (cost=0.28..31630.25 rows=3759 width=344) (actual time=0.041..21.992 rows=3759 loops=1) -> Seq Scan on orders (cost=0.00..289.59 rows=3759 width=328) (actual time=0.014..0.904 rows=3759 loops=1) -> Subquery Scan on aggs (cost=0.28..8.33 rows=1 width=16) (actual time=0.004..0.005 rows=1 loops=3759) Filter: (aggs.order_id = orders.id) -> GroupAggregate (cost=0.28..8.31 rows=1 width=16) (actual time=0.004..0.004 rows=1 loops=3759) Group Key: order_items.order_id -> Index Scan using index_order_items_on_order_id on order_items (cost=0.28..8.30 rows=1 width=8) (actual time=0.002..0.003 rows=1 loops=3759) Index Cond: (orders.id = order_id) Filter: (deleted_at IS NULL) Rows Removed by Filter: 0 Planning time: 0.411 ms Execution time: 26.936 ms不用 lateral 的话,你要加索引 [order_id, deleted_at],我本地是没问题的,带 order by id desc:
Limit (cost=495.12..498.33 rows=10 width=344) (actual time=16.001..16.218 rows=10 loops=1) -> Merge Left Join (cost=495.12..1702.50 rows=3759 width=344) (actual time=16.001..16.217 rows=10 loops=1) Merge Cond: (orders.id = order_items.order_id) -> Index Scan Backward using orders_pkey on orders (cost=0.28..1144.43 rows=3759 width=328) (actual time=0.105..0.283 rows=10 loops=1) -> Sort (cost=494.84..503.81 rows=3589 width=16) (actual time=15.886..15.889 rows=10 loops=1) Sort Key: order_items.order_id DESC Sort Method: quicksort Memory: 249kB -> GroupAggregate (cost=0.28..247.03 rows=3589 width=16) (actual time=1.900..14.025 rows=3257 loops=1) Group Key: order_items.order_id -> Index Only Scan using tindex on order_items (cost=0.28..187.50 rows=4727 width=8) (actual time=1.887..11.415 rows=4727 loops=1) Index Cond: (deleted_at IS NULL) Heap Fetches: 32 Planning time: 0.716 ms Execution time: 16.316 ms -
Friends don't let real friends use INT as a primary key? at November 09, 2018
uuid 更浪费,主键不止要存在一张表里,还要在其他表作为外键,还要加索引,所以内存和磁盘空间都带来没有必要的增长,云服务商应该是最希望看到 uuid 主键了。
-
Rails job 默认的 Active Job 如何不并发调同一方法 顺序执行方法 at November 09, 2018
- flock or redis lock
- k8s job 可以配置
-
求指教,关于冷热数据分离,各位大神们是如何在 Rails 中处理的? at November 08, 2018
为何要 mix oltp olap 呢?聚合查询在 slave 做或 etl 到一个 analytics db 这是很容易的。oltp olap 混用可能 500 万一张表会出问题,但这是架构问题…
-
求指教,关于冷热数据分离,各位大神们是如何在 Rails 中处理的? at November 08, 2018
冷热分两种 db?真是 no zuo no die…要么老老实实做 sharding 要么换个可以 auto sharding 的库,要么搞 proxy…
你上面的流程能 work 的前提是你的系统只存在简单的 select 查询…
你们是啥系统,都达到这种规模,但还搞出这种过家家一样的方案,交易所吗
-
一招秒杀 N+1 agg 问题 at November 04, 2018
最近发现 mv refresh 之后还要手动 vacuum,要不空间一直涨。
-
一招秒杀 N+1 agg 问题 at November 04, 2018
没需求啊