关于 n+1 聚合函数问题的描述可以参考这个帖子:https://ruby-china.org/topics/26245
最近发现一个更简单灵活的解法,使用 Rails scope,无任何添加剂。
class Order < ApplicationRecord
scope :with_items_count, -> () {
aggs_sql = OrderItem.group(:order_id).select("order_id, COUNT(*) AS items_count").to_sql
select("orders.*, aggs.*").joins("LEFT JOIN (#{aggs_sql}) AS aggs ON aggs.order_id = orders.id")
}
end
使用方法:
Order.with_items_count.last(10).each do |x|
p x.items_count
p x.id
p x.no
end
生产 SQL:
SELECT orders.*, aggs.* FROM "orders" LEFT JOIN (SELECT order_id, COUNT(*) AS items_count FROM "order_items" WHERE "order_items"."deleted_at" IS NULL GROUP BY "order_items"."order_id") AS aggs ON aggs.order_id = orders.id LIMIT 10
从原来的 n+1 变成了一条带子查询的 SQL,比 eager load 还要高效。如果你用 Postgres 的话,结合Selective Aggregates,多个过滤条件和多个 agg 一起搞定,可以爽到飞...
关于是不是全表扫的问题,感觉好多人对这个有误解,可能是之前的“避免 subquery”之类文章看多了吧...
过程化语言,已经指定好了需要执行的每一个步骤。
但 SQL 是描述性语言,只指定了做什么,而没有指定怎么做。
至于如何做更有效率,这取决于优化器,所以有着更多的可能。
同一条 SQL 在不同 DB 上执行,由于优化器的实现、执行计划的不同、数据量和分布的不同、索引的不同、内存等资源的不同,产生的执行计划完全不一样。
所以不要轻易说一条 SQL 是不是全表扫描...
玩了下 Selective Aggregates,非常爽,学习了(为什么 pg 官方文档上找不到呢?)
你讲的无任何添加剂的秒杀 n+1 agg 的解法和 https://ruby-china.org/topics/26245的一楼那个物化视图方法貌似是一样的(都是你写的
 ),区别是,
),区别是,OrderItem.group(:order_id).select("order_id, COUNT(*) AS items_count")在那里变成了物化视图。感觉这种解法已经和写原生 SQL 差不多了,可能写原生 SQL 更加易读一些
1.这里有各个版本的特性支持:https://www.postgresql.org/about/featurematrix/
3.主要是可以利用其它 scope relation 等组合,raw SQL 复用困难。。

flyerhzm 已经把这个功能做成 gem 了, https://github.com/xinminlabs/eager_group,我用过,很不错。
eager_group 确实很好用,但存在一些问题:
- eager_group 好像不支持 Rails 5,好像也不维护了,这个帖子提的方案不依赖任何 gem,不存在维护问题
- 这个帖子的方案无论有多少个需要聚合的指标,都只产生一条 SQL,而 eager group 如果有 n 个指标,需要产生 n+1 个 SQL
- eager_group 只是 aggregate_function(aggregate_column),算是一种最经典的形式,但现实需求往往比这要复杂,很多 case 处理不来。
SELECT orders.*, aggs.* FROM "orders" LEFT JOIN (SELECT order_id, COUNT(*) AS items_count FROM "order_items" WHERE "order_items"."deleted_at" IS NULL GROUP BY "order_items"."order_id") AS aggs ON aggs.order_id = orders.id LIMIT 10
这个是正序的情况,是很快,但是 last 是带了 order by orders.id desc 的,好像速度不行~
SELECT orders.*, aggs.* FROM "orders" LEFT JOIN (SELECT order_id, COUNT(*) AS items_count FROM "order_items" WHERE "order_items"."deleted_at" IS NULL GROUP BY "order_items"."order_id") AS aggs ON aggs.order_id = orders.id ORDER BY orders.id DESC LIMIT 10
感觉在中间的子查询中还要再嵌套一层过滤 order_id 的,根据外层的条件来
不带 ORDER BY
Limit (cost=0.71..6.73 rows=10 width=359) (actual time=0.072..0.127 rows=10 loops=1)
-> Merge Left Join (cost=0.71..40027.18 rows=66537 width=359) (actual time=0.071..0.125 rows=10 loops=1)
Merge Cond: (orders.id = order_items.order_id)
-> Index Scan using orders_pkey on orders (cost=0.29..9346.63 rows=66537 width=347) (actual time=0.028..0.054 rows=10 loops=1)
-> GroupAggregate (cost=0.42..29731.93 rows=34768 width=12) (actual time=0.039..0.057 rows=5 loops=1)
Group Key: order_items.order_id
-> Index Only Scan using index_order_items_on_order_id on order_items (cost=0.42..28311.68 rows=214514 width=4) (actual time=0.029..0.044 rows=21 loops=1)
Heap Fetches: 21
Planning time: 0.640 ms
Execution time: 0.244 ms
带了 ORDER BY
Limit (cost=12230.82..12232.33 rows=10 width=359) (actual time=254.210..254.258 rows=10 loops=1)
-> Merge Left Join (cost=12230.82..22265.03 rows=66537 width=359) (actual time=254.208..254.253 rows=10 loops=1)
Merge Cond: (orders.id = order_items.order_id)
-> Index Scan Backward using orders_pkey on orders (cost=0.29..9346.63 rows=66537 width=347) (actual time=0.025..0.059 rows=10 loops=1)
-> Sort (cost=12230.53..12317.45 rows=34768 width=12) (actual time=254.177..254.179 rows=5 loops=1)
Sort Key: order_items.order_id DESC
Sort Method: quicksort Memory: 3857kB
-> HashAggregate (cost=8912.71..9260.39 rows=34768 width=12) (actual time=202.281..223.324 rows=53143 loops=1)
Group Key: order_items.order_id
-> Seq Scan on order_items (cost=0.00..7840.14 rows=214514 width=4) (actual time=0.014..87.574 rows=214514 loops=1)
Planning time: 0.660 ms
Execution time: 255.422 ms
如果在中间那个 group by 的子查询中再嵌套一个子查询带外层的条件,又感觉比较丑
可以试试 把 left join 改成 LEFT JOIN LATERAL,加个条件 OrderItem.where("orders.id = order_items.order_id").group
SELECT orders.*, aggs.* FROM "orders" LEFT JOIN LATERAL (SELECT order_id, COUNT(*) AS items_count FROM "order_items" WHERE "order_items"."deleted_at" IS NULL AND (orders.id = order_items.order_id) GROUP BY "order_items"."order_id") AS aggs ON aggs.order_id = orders.id ORDER BY id desc;
Sort (cost=31853.46..31862.86 rows=3759 width=344) (actual time=26.134..26.694 rows=3759 loops=1)
Sort Key: orders.id DESC
Sort Method: quicksort Memory: 2035kB
-> Nested Loop Left Join (cost=0.28..31630.25 rows=3759 width=344) (actual time=0.041..21.992 rows=3759 loops=1)
-> Seq Scan on orders (cost=0.00..289.59 rows=3759 width=328) (actual time=0.014..0.904 rows=3759 loops=1)
-> Subquery Scan on aggs (cost=0.28..8.33 rows=1 width=16) (actual time=0.004..0.005 rows=1 loops=3759)
Filter: (aggs.order_id = orders.id)
-> GroupAggregate (cost=0.28..8.31 rows=1 width=16) (actual time=0.004..0.004 rows=1 loops=3759)
Group Key: order_items.order_id
-> Index Scan using index_order_items_on_order_id on order_items (cost=0.28..8.30 rows=1 width=8) (actual time=0.002..0.003 rows=1 loops=3759)
Index Cond: (orders.id = order_id)
Filter: (deleted_at IS NULL)
Rows Removed by Filter: 0
Planning time: 0.411 ms
Execution time: 26.936 ms
不用 lateral 的话,你要加索引 [order_id, deleted_at],我本地是没问题的,带 order by id desc:
Limit (cost=495.12..498.33 rows=10 width=344) (actual time=16.001..16.218 rows=10 loops=1)
-> Merge Left Join (cost=495.12..1702.50 rows=3759 width=344) (actual time=16.001..16.217 rows=10 loops=1)
Merge Cond: (orders.id = order_items.order_id)
-> Index Scan Backward using orders_pkey on orders (cost=0.28..1144.43 rows=3759 width=328) (actual time=0.105..0.283 rows=10 loops=1)
-> Sort (cost=494.84..503.81 rows=3589 width=16) (actual time=15.886..15.889 rows=10 loops=1)
Sort Key: order_items.order_id DESC
Sort Method: quicksort Memory: 249kB
-> GroupAggregate (cost=0.28..247.03 rows=3589 width=16) (actual time=1.900..14.025 rows=3257 loops=1)
Group Key: order_items.order_id
-> Index Only Scan using tindex on order_items (cost=0.28..187.50 rows=4727 width=8) (actual time=1.887..11.415 rows=4727 loops=1)
Index Cond: (deleted_at IS NULL)
Heap Fetches: 32
Planning time: 0.716 ms
Execution time: 16.316 ms
和索引无关,本地索引是对的
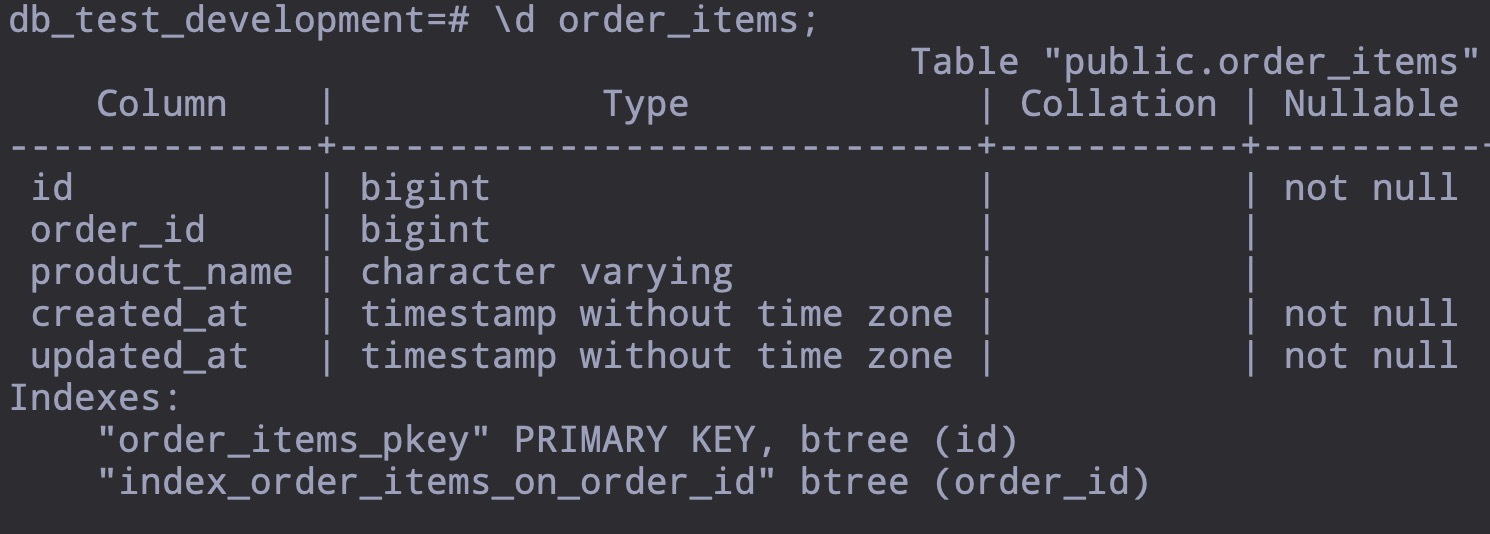
order_items 的数据量为 20W+ orders 为 5W+
使用 LEFT JOIN LATERAL 在子查询里面多加 where 条件后好。感觉还是里面的查询不知道要使用 order_id 的索引来过滤数据,需要强制指定。如果没有这种用法,是不是就只能用子查询了?第一次见到这种写法  又学了一招
又学了一招
嗯,我忘了,我没有 deleted_at 字段,#21 的那里语句写的是按例子来的,实际的是下面这个
SELECT orders.*, aggs.* FROM "orders" LEFT JOIN (SELECT order_id, COUNT(*) AS items_count FROM "order_items" GROUP BY "order_items"."order_id") AS aggs ON aggs.order_id = orders.id ORDER BY orders.id DESC LIMIT 10;
