本文由内部分享整理而成,如发现有错误的地方,请不吝指出
什么是 Unicorn
unicorn 是 Ruby Web 应用中的一款应用服务器,提供两个功能:
- 为 Rack 应用提供 HTTP 服务能力
- 为应用实现高并发能力
unicorn 工作在 Web 的应用层,直接调用后端 Handler 处理请求。
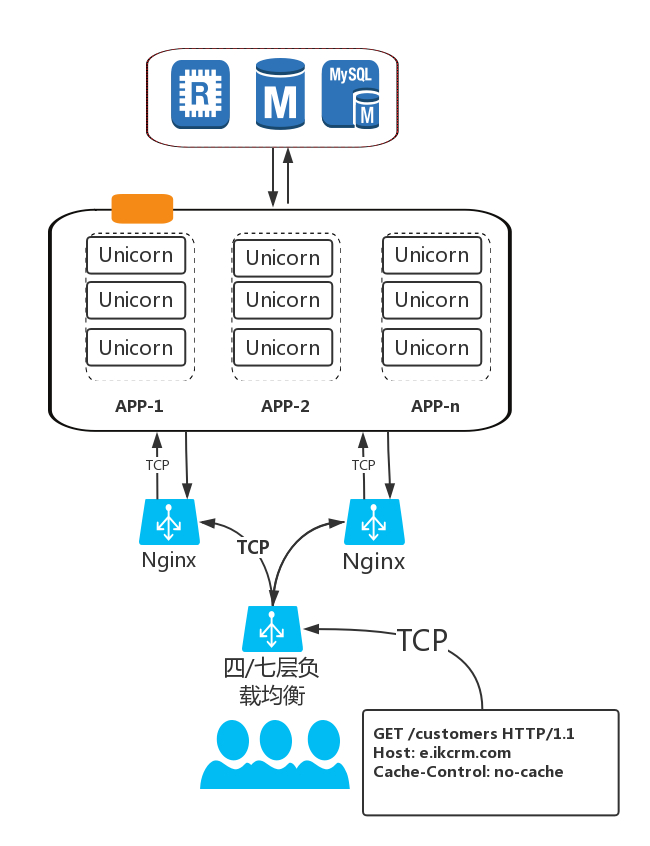
如何工作
提供 HTTP 服务功能:
- 监听端口/unix socket,接收 http 请求
- 解析 http 请求,调用应用处理请求
- 将处理结果返回
通过多进程提供高并发能力。由于 Ruby 全局解释锁阻碍的同一进程中的线程并行执行,Ruby 应用中的高并发必须通过多进程实现。
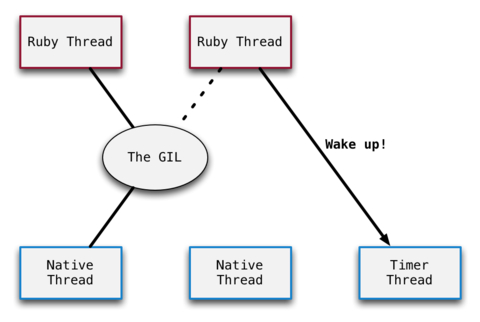
线程中如果有 IO 操作时,GIL 会自动释放,所以在线程中有 IO 操作的情况下,同一进程中的多个线程可以实现近似的并行执行。
通过 Master-Workers 进程结构提供服务:
- 一个 Master,管理 Worker 进程,处理外部信号,不处理请求
- 多个 Worker 进程,处理实际的请求,彼此独立
此结构和 Nginx 多进程模式一致。Master 作为劳心者,不处理实际的事务,只做顶层调度。Workers 作为劳力者,只处理实际的请求,受制于 Master。
请求处理过程
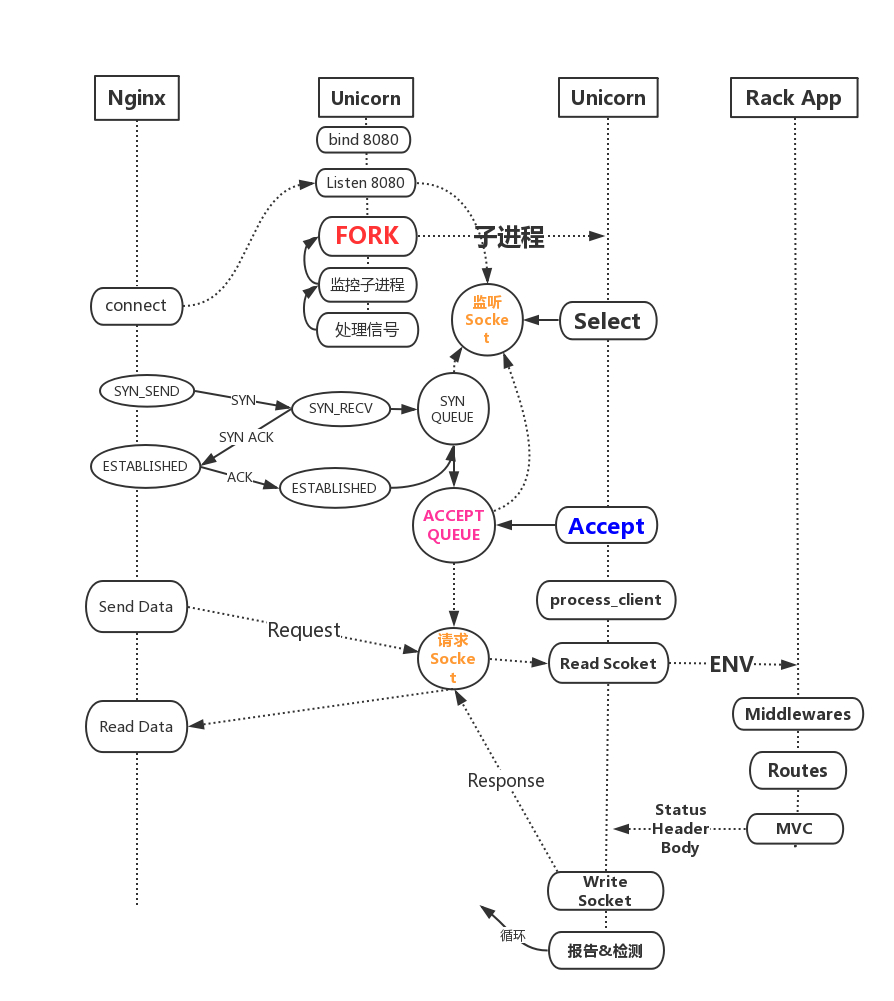
通过上图可总结如下:
- Master 监听端口,Fork 子进程 (也可以通过 sparn)
- 子进程通过 select && accept 调用获取连接
- 子进程读 socket 数据,调用 Rack App,再将结果回写 socket
另外:
IO 模型
由上图可以看出 unicorn 的 IO 模型有如下特点:
- IO 低效,阻塞(宏观视角,本身使用非阻塞调用)
- 一个进程同时只能处理一个请求,吞吐量低下
- 在 Socket 读写或数据库查询等等 IO 操作时,进程空闲,资源浪费
- 无法处理慢 IO,需要前置 Nginx
与 Puma 的 IO 对比
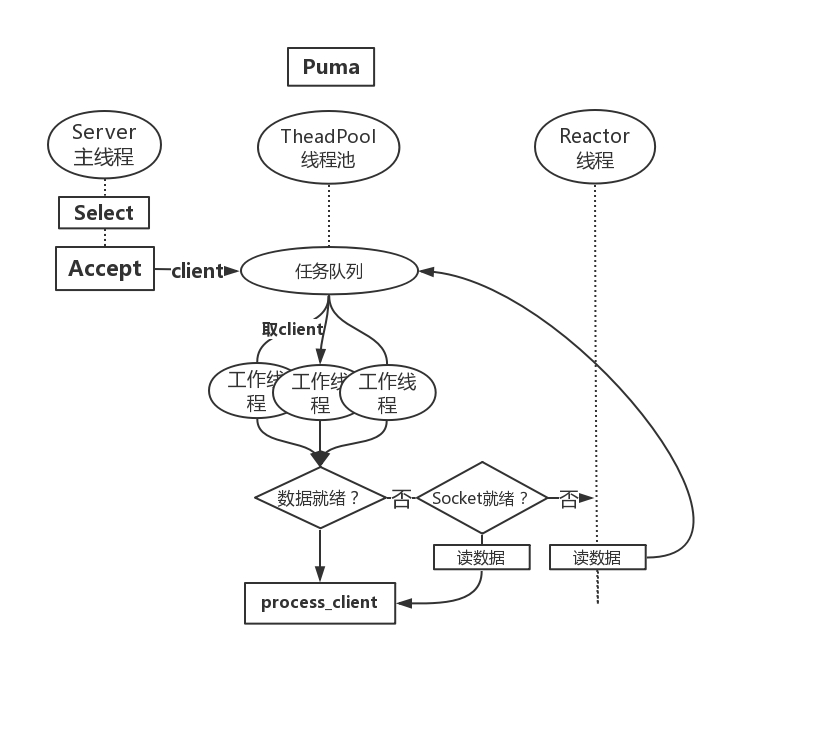
Puma 实现了 Reactor 模型,所谓 Reactor 模型就是将Socket的操作和实际的请求处理用不同的角色来做,不像 unicorn 那样用同一个角色 (线程) 来处理。避开了 Socket 操作时阻塞导致的进程资源浪费,实现了高效、分工、低耦合等。
同时引入多个工作线程来处理实际的请求。这样在某个线程调用外部接口或者查询数据库等 IO 操作时,其他工作线程可以并发执行,避免进程空闲。
整理特点如下:
- IO 相对高效,进程不容易空闲
- 一个进程可以同时处理多个请求,吞吐量高
如何管理进程
Master
Worker
- 检测 Master,同生共死,代码
- 接收 Master 的指令
通信方式:
- pipe
- raindrops (共享数据)
如何平滑重启
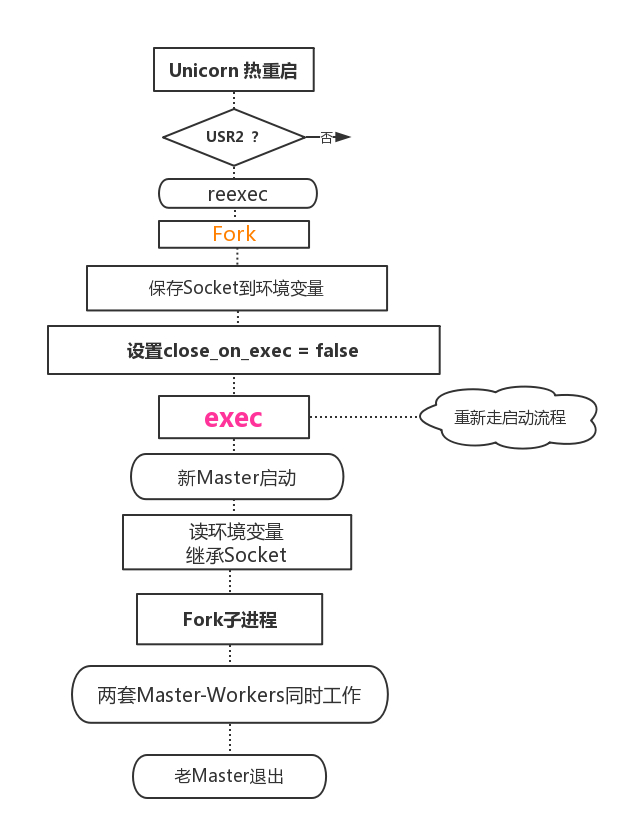
平滑关键点在于:
- 通过环境变量传递监听的 socket
- 设置监听 socket close_on_exec,让操作系统保留监听 socket
详细信息可以参考: Unicorn 进程如何保证平滑重启?
unicorn-killer
def process_client(client)
super(client) # Unicorn::HttpServer#process_client
return if @_worker_memory_limit_min == 0 && @_worker_memory_limit_max == 0
@_worker_process_start ||= Time.now
@_worker_memory_limit ||= @_worker_memory_limit_min + randomize(@_worker_memory_limit_max - @_worker_memory_limit_min + 1)
@_worker_check_count += 1
if @_worker_check_count % @_worker_check_cycle == 0
rss = GetProcessMem.new.bytes
logger.info "#{self}: worker (pid: #{Process.pid}) using #{rss} bytes." if @_verbose
if rss > @_worker_memory_limit
logger.warn "#{self}: worker (pid: #{Process.pid}) exceeds memory limit (#{rss} bytes > #{@_worker_memory_limit} bytes)"
Unicorn::WorkerKiller.kill_self(logger, @_worker_process_start) # 关键点
end
@_worker_check_count = 0
end
end
通过 hack process_client方法,在请求处理完后,检测进程内存消耗等参数,操作阈值,则将自己干掉,Master 会自动起新的 Worker 进程。
有关 unicorn 中 fork,exec,preload 等更细节的描述,可以参考 Unicorn 进程如何保证平滑重启?
 挺好的帖子,学到了很多
挺好的帖子,学到了很多