-
【翻译】Async Ruby(异步 Ruby) at 2023年10月27日
那怎么设置 Fiber current 变量呢?
-
【翻译】Async Ruby(异步 Ruby) at 2023年10月27日
Thread.current 有,Fiber.current 没有
-
【翻译】Async Ruby(异步 Ruby) at 2023年10月26日
大写的方法名,好奇怪。。 另外 ruby 有 contextvar 么,类似于 python 的 contextvar, 协程级别隔离的变量
-
如何进行测试驱动开发 at 2023年09月11日
也可以先写代码,然后让 chatgpt 补测试。
-
语法越复杂,越影响语言的发展 at 2023年08月17日
以后反正都用自然语言编程了。
-
[深圳] ShowMeBug 招聘 Ruby 中高级工程师 2-3 名 at 2023年08月15日
加好了
-
[深圳] ShowMeBug 招聘 Ruby 中高级工程师 2-3 名 at 2023年08月15日
@lyfi2003 加你微信没反应?有事想跟你探讨
-
好丑的 url
-
国内 Rails 的工作机会还有多少? at 2023年05月18日
cool,又多一个选择。像这种如果对方满意,那么一些细节, 比如支付怎么弄,缴税怎么弄?
-
有没有人有兴趣一起 fork 一个功能简单的 Homeland?使用 Crystal? at 2023年05月06日
这样啊,加油干啊。python 加速的也出来了,mojo 语言,比 python 快 35000 倍。 所以楼主玩 crystal,还是要顶一下,毕竟自己玩的是 ruby
-
在 Rails 中使用 SSE 来实现一个 ChatGPT 应用 at 2023年05月05日
我好奇你那里有 ai 算命怎么实现的?
-
搞了一个专门用来学习 Ruby 和 Rails 的 GPT: RubyChat at 2023年04月23日
嗯,其他一些 vector database, pinecone, redis vector,楼主比较过么? 还是说看见 weaviate 就用了?(weaviate 是开源免费可以装在本地么?还是 cloud 付费?)
-
"小贴士"功能可以考虑让大家可以参与添加内容 at 2023年04月15日
我首页能看到一个小贴士,但是这个小贴士不能点?
-
[支持远程][兼职] 背书推荐:奇绩创坛招聘兼职 Ruby on Rails 全栈工程师 at 2023年04月14日
 这个之前在 frontendmentor 做的作业,跟原有的 design 稍微有点差距,问在 frontendmentor 也没人回,
你觉得这种 slight off 的问题,去哪里问,找谁问比较好?
这个之前在 frontendmentor 做的作业,跟原有的 design 稍微有点差距,问在 frontendmentor 也没人回,
你觉得这种 slight off 的问题,去哪里问,找谁问比较好? -
[支持远程][兼职] 背书推荐:奇绩创坛招聘兼职 Ruby on Rails 全栈工程师 at 2023年04月12日
我不会,我只会 Ruby/Rails 后端

-
分词是什么原理?比较著名的是 jieba 分词,不过操作系统其实有内置分词功能 at 2023年04月01日
以上描述 bpe 算法漏了一点,你的句子,比如"张家口是 2022 年北京冬奥会的其中一个赛区", 那么一开始是拆分成“张,家,口,是,...", 然后合并"张 + 家"时候,出了向你词典添加"张家"以外,你的句子就变成"张家,口,是,"
-
分词是什么原理?比较著名的是 jieba 分词,不过操作系统其实有内置分词功能 at 2023年04月01日
byte pairing encoding,一种根据频率的算法。假设你的 corpus 有很多句子,先分割成每个单字,然后迭代 K 次 (你自己设定一个值), 每次都找出最大频率的连着的词,比如张 + 家连续出现,并且出现频率是 500 次,是当前迭代最多的频率,那么你把"张家"合并,并且 添加到你的词典中,然后继续接下来的合并,比如"张家"+"口" 100 次,是这次迭代的最高频率,那么合并成为"张家口",在你的词典中添加"张家口",这时候你的词典有"张","家","张家","张家口", 然后训练玩了拆分一个新的句子的时候,greedy 匹配就好。以上是根据词频的 byte pairing encoding 算法。但是我想了一下,如果已经有一个词典就有词的列表,比如我就拿新华字典所有的词作为我词典的词,也就可以了,根本用不到 bpe 算法。
-
分词是什么原理?比较著名的是 jieba 分词,不过操作系统其实有内置分词功能 at 2023年03月31日
英文有 byte pairing encoding 算法,中文可能也是类似算法吧
-
ChatGPT ReAct (Reason+Act) 模式实现 at 2023年03月30日
in-context learning 应该所有 llm 都有吧
-
Rei on Rails #6:用 Rails 开发 ChatGPT 聊天应用 at 2023年03月24日
666,OpenaiApiProxy::ChatClient 是啥么?没看到,是自己封装的库么?
-
Rei on Rails #6:用 Rails 开发 ChatGPT 聊天应用 at 2023年03月24日
-
Rei on Rails #6:用 Rails 开发 ChatGPT 聊天应用 at 2023年03月24日
plugin 一出,创业公司没得玩了
-
Ruby 的发展思路有问题 at 2023年03月24日
一旦生态形成,后来者就很难打破。因为意味着以后迁移就需要学习和新的使用习惯。
-
斜视 chatgpt 崇拜 at 2023年03月21日
兄弟,有空去看看 wolfram physics 把,早就对意识进行探讨了,https://writings.stephenwolfram.com/2021/03/what-is-consciousness-some-new-perspectives-from-our-physics-project 几个重点,宇宙是台图灵机,还有计算等价性原理。What is life generally? And I’ll argue that it’s really just computational sophistication.We know the case of human intelligence. But if we generalize, it’s just computational sophistication—and it’s ubiquitous. And so it’s perfectly reasonable to say that“the weather has a mind of its own”; it just happens to be a mind whose details and“purposes”aren’t aligned with our existing human experience。所以人脑只不过是一种 computational sophistication,当然可以用其他图灵机模拟。
-
解决搜索问题就一定要上 ElasticSearch 吗? at 2023年03月14日
自己搜了一下: Meilisearch 和 Elasticsearch 都是基于 JSON 的全文搜索引擎,但它们有一些不同的特点和适用场景。根据搜索结果 123,我总结了以下几点:
Meilisearch 是一个轻量级的搜索引擎,使用 Rust 语言编写,不依赖 JVM 或其他运行时环境。Elasticsearch 是一个复杂的搜索引擎,使用 Java 语言编写,基于 Lucene 库,需要 JVM 运行。 Meilisearch 提供了开箱即用的功能,如错字容忍、过滤器和同义词。Elasticsearch 需要更多的配置和训练才能实现这些功能。 Meilisearch 更适合中小型数据集(少于五百万条记录)和简单的搜索需求。Elasticsearch 更适合大型数据集(达到 PB 级别)和复杂的搜索和聚合需求。 Meilisearch 只支持单节点部署,不具备高可用性和容错性。Elasticsearch 支持多节点集群部署,具备水平扩展和分布式处理能力。 Meilisearch 是完全开源的软件,可以自由使用和修改。Elasticsearch 是源可见的软件,遵循 SSPL 协议,在某些情况下需要付费使用。
-
解决搜索问题就一定要上 ElasticSearch 吗? at 2023年03月14日
meilisearch 跟 elasticsearch 相比起来有什么优缺点么?
-
程序员的悲哀是什么?(怎么看?) at 2023年01月08日
chatGPT 中国不可用
-
MIT 6.824 Distributed Systems Reading Notes at 2022年09月18日
pass 3A 了。但是有个问题,我在 kv 层维护了 responses map[string]string, 从 client 的 requestId 映射到 responses(防止 client 发重复的 requestid),但是随着 client 不断发 request, 这个 map 会不断增长。实际应用肯定是有问题的。
-
MIT 6.824 Distributed Systems Reading Notes at 2022年09月16日
另外一个问题是写 goroutine 中发现的,goroutine 好像允许一个 goroutine 锁 lock,然后另一个 goroutine unlock, 简单说明代码如下:
var mu sync.Mutex mu.Lock() var wg sync.WaitGroup wg.Add(1) go func() { mu.Unlock() wg.Done() }() wg.Wait() fmt.Println("locking again") mu.Lock() mu.Unlock()也就是对于 go 的 mutex 的实现来说,只管 lock/unlock,而不管是在那个 goroutine unlock? (通常我们是同一个 goroutine lock/unlock)
主要问题是因为调试 raft 代码中一大堆 goroutine 和一堆 lock, 当 hold lock 的时候,起 goroutine,这些 goroutine 相当于是看到这个锁 lock 的? 代码如下:
rf.mu.Lock() go func() { rf.applyCh <- ApplyMsg{SnapshotValid: true, Snapshot: args.Data, SnapshotTerm: args.LastIncludedTerm, SnapshotIndex: args.LastIncludedIndex} }() rf.mu.Unlock()), 在实现 snapshot 的时候,这个 goroutine 会有一段时间看见这个锁 lock?
所以感觉这里锁的语义不是很明确
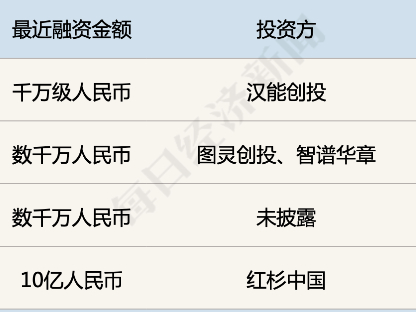 就不具体透露是做什么行业的了,加了具体聊?
就不具体透露是做什么行业的了,加了具体聊?