-
[上海][2019年09月03日] Ruby 聚会召集 at 2019年09月02日
+1
-
大家的个人博客是定制开发还是开源系统 at 2019年07月15日
-
[上海][8-24,25] RubyConf China 2019 赞助召集 at 2019年05月15日
撒花
-
[上海] SAP 招聘 Ruby / 运维 / 测试 / Android / Java / 工程师 [Closed] at 2019年04月15日
有测试工程师的岗位么?
有,我已经更新了帖子。
-
[上海] SAP 招聘 Ruby / 运维 / 测试 / Android / Java / 工程师 [Closed] at 2019年04月15日
比如一个上午/下午 4 轮这种的吗?
你说的很对。我们的面试通常先是电话面试,然后再约一个上午/下午 3-4 轮面试。
-
[上海] SAP 招聘 Ruby / 运维 / 测试 / Android / Java / 工程师 [Closed] at 2019年04月15日
运维是没有 level 的吗?
运维两个岗位的 level:一个是 devops(T2),一个是 senior devops (T3)
-
[上海] SAP 招聘 Ruby / 运维 / 测试 / Android / Java / 工程师 [Closed] at 2019年04月11日
此贴顺便帮我们 SAP 的隔壁团队 successfactor 招聘 Java 工程师 以及 Java 专家。感兴趣的同学可以投递简历。
Java 工程师 (T2)
Duties and Responsibilities:
- Understand business requirement, design, implement and continuously improve complex SaaS system to support cloud customer
- Work closely with local and global engineering teams to develop/maintain SuccessFactors platform services, frameworks and applications
- Build scalable, stable and efficient platform fundamental services, frameworks and applications
- Write quality, testable, maintainable, and well-documented code
- Give support to support service employees on customer issue
Required Skills & Experience:
- BS/MS in Computer Science, Computer Engineering or related technical
- 2+ years of experience in software development and engineering
- Good knowledge of Java language, OOP concepts.
- Have a solid foundation with relational database and SQL
- Understand system architecture
- Basic knowledge of cloud native development, understanding of scalable micro-services, design pattern, CI/CD and DevOps is a plus
- Experience of Cache service (redis)/ELK/Messaging System(Kafka) is preferable
- Exposure to public clouds (i.e. Azure, AWS, GCP, Ali Cloud) is preferable
- Experience in Agile/Scrum, BDD, TDD, software refactoring and other engineering best practices is preferable
- A team player with good communication skills, speaking and writing fluent English
- Demonstrate technical curiosity and passion for exploring new technologies for future technical roadmap via continuous learning and self-development
- Understanding and hands on skills in docker, k8s, reverse proxy tuning will be a plus
- Familiarity of scripting language like shell, python, Lua will be a plus
Java 架构师 (T3)
Duties and Responsibilities:
- Understand company strategy and business, design, implement and continuously improve complex backend system to support huge volume SaaS system with complex business scenarios, with high security, performance, scalability and testability Liaison with Product Manager, Engineering Manager and other agile teams to align with the overall product vision and architecture design Lead best practice for clean and effective code, improve team technical level
- Lead and influence technical direction and roadmap
- Lead design reviews for engineers and provide feedback on architecture and open design questions
- Required Skills and Experience:
BS/MS in Computer Science, Computer Engineering or related technical
- 8+ years of experience in enterprise software architecture design, Java development and engineering
- Has experience on Java performance tuning / troubleshooting is a plus
- Have a solid foundation with relational database and SQL
- Experience in DB tuning experienced is a plus
- Good knowledge of cloud native development, understanding of scalable micro-services, design pattern, CI/CD and DevOps is a plus
- Exposure to public clouds (i.e. Azure, AWS, GCP, Ali Cloud) is preferable
- Experience in Agile/Scrum, BDD, TDD, software refactoring and other engineering best practices is preferable
- Capable of working in global engineering team across different time zones and locations
- Strong analytics skill and logical thinking
- Strong leadership for people and technical
- Skills to clean and refactor complex code
- Strong collaboration and communication skills and be fluent in English
- Strong sense for built-in quality
- Demonstrate technical curiosity and passion for exploring new technologies for future technical roadmap via continuous learning and self-development
- Experience for developing micro-service, familiar with spring cloud, Dubbo etc.
- Experience for middleware development will be preferable.
- Familiar with common design pattern and can use it in the real coding or technical discussion
- Familiar with UML diagram and use to express the design thinking or technical solution
-
[上海] SAP 招聘 Ruby / 运维 / 测试 / Android / Java / 工程师 [Closed] at 2019年04月02日
又加了一个职位:运维工程师。
感兴趣的同学,欢迎投递简历。
谢谢。
-
[上海] SAP 招聘 Ruby / 运维 / 测试 / Android / Java / 工程师 [Closed] at 2019年03月26日
可以申请的,稍微透露一下,我们对英文的要求降低了一些。 😀
-
Let's clone a Message Queue at 2019年03月26日
我们项目因为历史原因,在使用 delayed_job,db 做 Queue 系统,锁是个很大问题。
- 多个 worker 在拿任务时,会有互斥。
- 拿任务和写入任务会互斥
借用一篇文章的标题:《Databases suck for Messaging》
https://www.rabbitmq.com/resources/RabbitMQ_Oxford_Geek_Night.pdf
迫于无奈,我们最终把 delayed_job 的后端迁移到 RabbitMQ 上。
-
[上海] SAP 招聘 Ruby / 运维 / 测试 / Android / Java / 工程师 [Closed] at 2019年03月26日
薪资是在公司内部是保密的,我也不知道别人的薪水,需要和 HR 直接谈。你可以按行情价要。
有几点要说明:
- HR 和你谈的时候,是按照年薪和你谈的。所以最好你拿计算器先算好。
- 因为我们的工作强度不高,不加班,准点上下班,假期也很多,所以薪酬会比市面上略低。
- 公司有股票计划,你每月可以拿十分之一的薪水买 SAP 股票,公司补贴 40%。比如:你月薪 20000,那么可以每个月拿 2000 投资公司股票,SAP 补贴 800。
-
[上海] SAP 招聘 Ruby / 运维 / 测试 / Android / Java / 工程师 [Closed] at 2019年03月25日
我们的面试比较注重计算机基本功,英文沟通能力,项目经验。编程语言不是首要考量因素。如果你是 Java 程序员、Python 程序员,也可以申请。
我们的项目中有个组件是 Java 写的,还有 golang 写的项目,是个大杂烩。
-
[上海] SAP 招聘 Ruby / 运维 / 测试 / Android / Java / 工程师 [Closed] at 2019年03月25日
暂时没有内,还有一个 ops 的岗位,过几天会发出来。
-
[上海] SAP 招聘 Ruby / 运维 / 测试 / Android / Java / 工程师 [Closed] at 2019年03月21日
我们没有强制要求,你可以只写后端,也可以前后端通吃。写烦了后端,也可以写 mobile 客户端。
-
Feed 流设计 (四):存储 at 2018年09月28日
以上只是根据 O(log n) 进行估算,可能不准确。但我想表达的意思是,假如一张表的某个字段的值的 cardinality 很高,根据这个字段的索引进行查询,无论是 100 万的记录,还是 1000 亿条记录,IO 次数可能差不多。
100 万需要 3 次
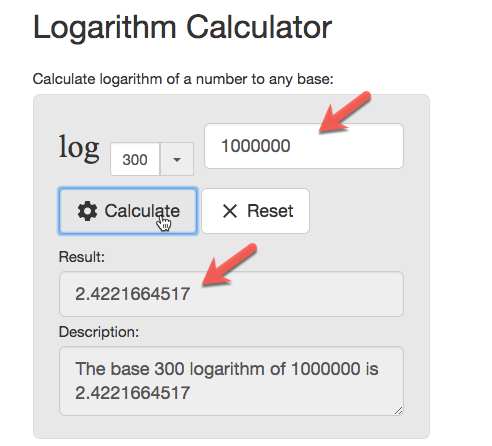
1000 亿需要 5 次
-
Feed 流设计 (四):存储 at 2018年09月28日
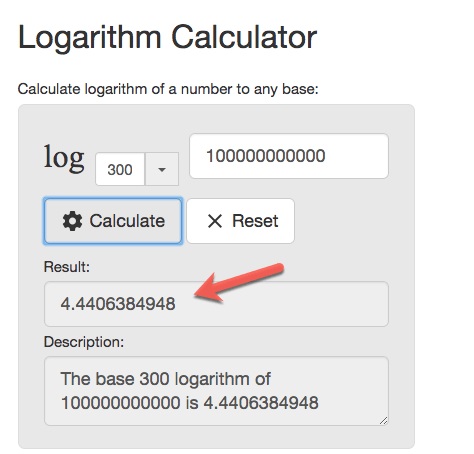
粗略估计一下,假如 B Plus tree 每个节点的大小为 4896 byte,用来存放 big integer (8 byte),大概可以存 300-600 个之间。[1]
假如我们取最小的数字 300 做 branching factor,那么在一张 1000 亿的表中读取一条记录需要几次 IO 呢?
5 次。
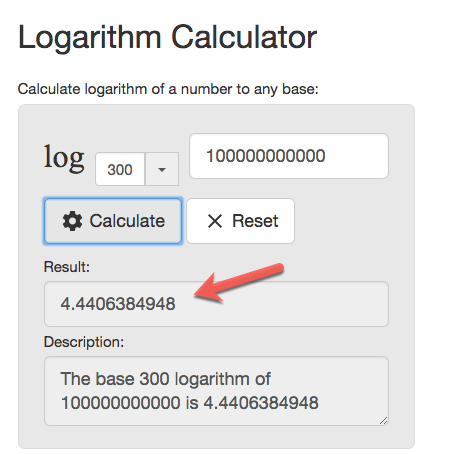
[1] 我不知道 block 的指针占多大,所以只能估算。假如 block 指针大小为 8 bype,则 branching factor 为 4896/(8+8) = 306。
-
Feed 流设计 (二):拉模式 Vs 推模式 at 2018年09月27日
对屏蔽的处理,我放到了 Part 3 中。
http://mednoter.com/design-of-feed-part-three.html
- xiaoronglv 和 quakewang 是好友关系。
- quakewang 屏蔽了 xiaoronglv
- 当小荣吕发言时,会产生一个 event
- RouteService.route! 在分发时,发现 quakewang 已经屏蔽 xiaoronglv 了,就不会分发给 quakewang 了。
-
反向索引,为什么称之为反向索引? at 2018年09月27日
多谢,已经修改。
-
Feed 流设计 (二):拉模式 Vs 推模式 at 2018年09月27日
很多人选择推拉结合。
一个例子就是「对僵尸用户的处理」
几年前我在薄荷网工作,那时有 2000 万用户,但日活只有 20+ 万。换句话说,存在大量的僵尸用户。如果为他们准备好队列,填满内容,其实是很不划算的,浪费了大量的存储空间。尤其是使用内存数据库时,简直是烧钱。当时采用的策略是:平时不管这些僵尸用户,他们的队列是空的,没有任何 feed,当他们登录时,临时去拉数据,把他们的队列填满。
但是企业市场不能这么考虑问题,SAP 的客户每年都在付费,人家买的就是服务。所以即使客户不登录,我们还是把每个客户队列中的内容准备好。
-
Feed 流设计 (二):拉模式 Vs 推模式 at 2018年09月26日
假如 Bell 取消了屏蔽,再次去拉 Ryan 的消息吗?
我的考虑:Feed 的内容大部分都有时效性,过了时间之后就没有什么价值了。取消屏蔽后,是不是可以不用拉数据啊。
-
Feed 流设计 (三):分发逻辑 at 2018年09月26日
Feed 流设计 (四):存储层
第四部分写数据库的选择,过几天再更新哈。
-
Feed 流设计 (一):如何对多态内容进行抽象? at 2018年09月26日
好主意!我把索引贴到文章底部了。
-
[上海] Clover 四叶新媒体招聘 Ruby 工程师 / 运维开发工程师 / 实习工程师 (15K-30K) at 2018年04月25日
过来点个赞
-
[上海] SuccessFactors (an SAP Company) 招聘 Ruby 工程师 at 2018年01月26日
欢迎广大已婚已育,追求家庭和工作平衡,熬不动夜的老司机加入 SAP.
-
[上海] SuccessFactors (an SAP Company) 招聘 Ruby 工程师 at 2018年01月26日
我记得你们没有用 NoSQL 吧?
Experience of NewSQL DB like TiDB.
😀
-
要挖坑搞个新的开源项目,了解一下大家目前在用的 bug 管理工具是什么? at 2017年12月06日
曾经 redmine
-
要挖坑搞个新的开源项目,了解一下大家目前在用的 bug 管理工具是什么? at 2017年12月06日
jira
-
[招生] 零基础 Ruby 入门班 at 2017年11月06日
我也在带没有编程基础的学生,都是熟识的朋友,所以没有压力。带不好他们不会骂我,哈哈。每次视频交流时,也从他们身上学到好多知识。
楼主先招几个知己、愿意学编程的朋友做小白鼠,收集反馈,然后再开班,会不会好一些?
-
[招生] 零基础 Ruby 入门班 at 2017年11月06日
有人喜欢师徒制的学习方式,有人喜欢看视频/Google 自学。大家没必要踢别人场子。(如果教的不好,自然会有他的学生踢场子)
支持一下楼主。