分享 Feed 流设计 (四):存储
Feed 后台设计文章索引
在前几篇文章中,我们讨论了用 event 来抽象动态流中的内容,用推模式来提高读的效率,用 policy 模式来控制分发逻辑。
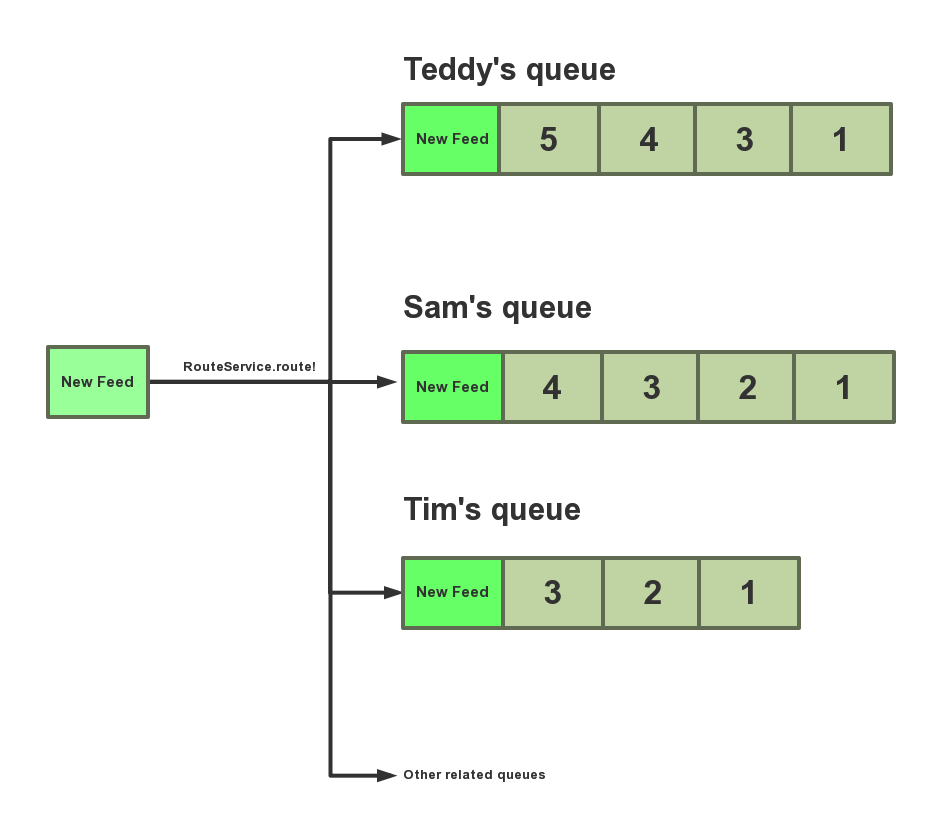
假如 Ryan 有 3 个 followers,Teddy,Sam 和 Tim。当 Ryan 发布一个新内容 (event) 时,该内容要推送到他 followers 的队列中。
这一篇文章,我们来讨论 feed 的存储。
1. Redis
Redis 是一个开源的 key-value,内存数据库,支持多种数据结构,如 strings,hashes,lists,sets,sorted sets。其中 List 是一个链表,可以非常方便操作在首尾部插入/删除元素。
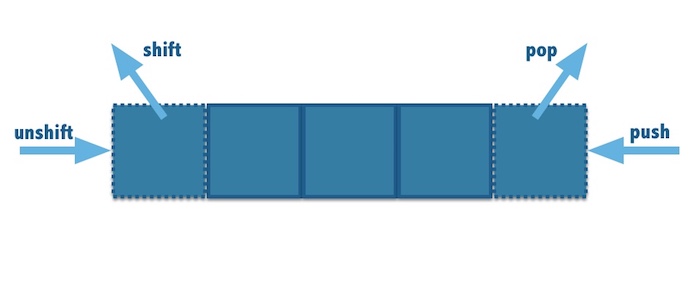
LPUSH: 在list 的左边插入一个元素。
LPOP: 在list的左边删除一个元素。
RPUSH: 在list的右边插入一个元素。
RPOP: 在list的右边删除一个元素。
LRANGE: 获取 list 一个范围内的元素, e.g. 'LRANGE key 0 99' 命令可以获取第1-100个元素。
1.1 如何使用 Redis 保存 feed 中的内容呢?
当 Ryan 发布内容时,我可以非常方便的把内容 (event_id) 推送到他的三个 follower 的队列中。
step1: Ryan 发布内容「我今天感觉好极了」,插入到表 statuses 中,主键为 10001
// Ryan 的 id 为 1
// 内容储存在 statuses 表中
insert into statuses (body, user_id) values ("我今天感觉好极了", 1);
step2: 把这个「创建操作」抽象为事件,查入道 event 表中,主键为 333333。
events 表的结构如下:
CREATE TABLE `events` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`user_id` int(11) DEFAULT NULL,
`operation` varchar(255) DEFAULT NULL,
`table_name` varchar(255) DEFAULT NULL,
`table_id` bigint(20) DEFAULT NULL,
`column_name` varchar(255) DEFAULT NULL,
`old_state` varchar(255) DEFAULT NULL,
`new_state` varchar(255) DEFAULT NULL,
`type` varchar(255) DEFAULT NULL,
`is_deleted` tinyint(1) DEFAULT '0',
`created_at` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
insert into
events(user_id, operation, table_name, table_id, column_name, old_state, new_state, type)
values (1, 'insert', 'statuses', 10001, '', '', 'CreateStatus')
step3:把 event_id 分发到 Teddy(user_id: 113),Sam(user_id: 114),Tim(user_id: 115) 的队列中。
lpush 'user_id_113_follow_feed' 333333
lpush 'user_id_114_follow_feed' 333333
lpush 'user_id_115_follow_feed' 333333
step4: 当 Teddy 下次登录时,使用以下命令获取 Teddy feed 中要展示的 events,然后渲染出来即可。
LRANGE user_id_113_follow_feed 0 99
当 Teddy 翻页时,使用 LRANGE 选取下一个 range 即可。
LRANGE user_id_113_follow_feed 100 199
1.2 Redis 缺点
Feed 流中的内容时效性特别强,内容很快的生产,然后流行传播,然后很快消散。热门的数据红的发紫,所有人都在看,比如当前王宝强和马蓉的离婚事件,全民消费。一个月之后,没有人再去关注它,这些内容就沉寂下来。
Redis 是内存数据库,用来储存热数据非常棒,性能很高。但是 Feed 中大部分数据都会逐渐变冷,无人问津,如果一直保存在内存里,储存的成本非常高。
简言之,Redis 不适合储存冷热不均的数据。
2. MySQL
Redis,RabbitMQ 天然的有队列 (queue) 数据结构,然而 MySQL 并没有,我们只能模拟队列,其本质是一张关系表,建好索引,做好 partition,尽可能的提高读的速度。
2.1 用数据库中的表 follow_feeds 来储存「follower 订阅的 events」。
CREATE TABLE `follow_feeds` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL,
`event_id` int(11) NOT NULL,
`routed_at` datetime NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
如何把内容储存到订阅者的队列中?
- Ryan 发布了新的内容,产生新的 Event (event_id: 333333)。
- RouteService.route! 会检查隐私级别,屏蔽,关注,权限等各种复杂的规则。
- Teddy 满足条件
- Tim 满足条件
- Sam 权限不足,没有阅读该 event 的权限。
- 虽然有 3 个 follower,但 RouteService.route! 只会在
follow_feed插入 2 条记录,关联 event 与 follower。
// 分发给 Teddy (user_id: 113)
insert follow_feeds (user_id, event_id) values (333333, 113)
// 分发给 Tim(user_id: 115)
insert follow_feeds (user_id, event_id) values (333333, 115)
当 Teddy(user_id: 113) 登录时,他通过这个查询即可获得自己队列的内容,Ryan 的更新排在 Feed 第一的位置。
select * from follow_feeds
where user_id = 113
order by event_id desc
当 Tim Tim(user_id: 115) 登录时,他通过这个查询即可获得自己队列的内容,Ryan 的内容排在 Feed 第一的位置。
select * from follow_feeds
where user_id = 115
order by event_id desc
当 Sam (user_id: 114) 登录时,看不到 Ryan 的更新。
select * from follow_feeds
where user_id = 114
order by event_id desc
2.2 用表 tag_feeds 来储存「与某个 tag 有关的 events」。
CREATE TABLE `tag_feeds` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`tag_id` int(11) NOT NULL,
`event_id` int(11) NOT NULL,
`routed_at` datetime NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
如何把内容储存到队列中?
- 比如 Ryan 发布了一条动态「#RocksDB is Great」。
- RouteService.route! 在分发时发现含有 RocksDB 这个标签。
- 如果满足各种条件,就在 tag_feeds 里面创建一条记录,关联 tag 与 event。
如何在队列中读取数据?
当用户要查看 #RocksDB 的 feed,只需要 2 条 sql 简单查询既可以获取所有的 feed 内容。
select * from tag_feeds where tag_id = 标签的主键
order by event_id desc
2.3 用 object_feeds 来保存「与某个 object 有关的 events」。
object 可以是一本书,一只股票,一个工作机会。
CREATE TABLE `tag_feeds` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`object_id` int(11) NOT NULL,
`object_type` varchar(255) DEFAULT NULL,
`event_id` int(11) NOT NULL,
`routed_at` datetime NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
如何把内容储存到队列中?
- 吕小荣创建了一个新内容,产生一个 event。
- RouteService.route! 在分发时,发现与某个 object 相关。
- 如果满足各种条件,就在 object_feeds 里面创建一条记录,关联 object 与 event。
比如 Ryan 写了一篇书评 读《21 世纪的管理挑战》有感,那么就会有如下的关系被创建:
insert object_feeds (object_type, object_id, event_id) values ('Book', 1, 5)
如何从队列中读取数据?
当用户查看《21 世纪的管理挑战》的书评页面时,通过这个简单的查询即可获得所有的内容。( e.g. demo)
select * from object_feeds
where object_type = 'Book' and object_id = 1
order by event_id desc
2.4 用 profile_feeds 来保存「与个人页面相关的 events」
在 Facebook 每个人都有个人主页,在这个页面可以看到他说过的话,分享的视频和图片等等。e.g. 吕小荣的 facebook 主页
如何把内容储存到队列中?
- 吕小荣创建了一个新内容,产生新的 event。
- RouteService.route! 根据 Policy 决定是否在 profile_feeds 创建一条记录。
- 如果满足条件,则关联 event 与 作者。
如何从队列中读取数据?
当你访问吕小荣的个人主页时,通过这个简单的查询即可获得所有的内容。
select * from profile_feeds
where user_id = 1
order by event_id desc
2.4 用 mention_feeds 来保存「@某个人的 events」
我们经常会在社交工具上 @somebody,对方就会收到通知。
如何把内容储存到队列中?
- 阳治平创建了一个新内容,并且 @吕小荣,产生新的 event。
- RouteService.route! 在分发的时候发现里面 @吕小荣
- RouteService.route! 检查吕小荣没有屏蔽阳治平,吕小荣的设置也接受此类提醒。
- 在
mention_feeds中创建一条记录,关联 event 与 吕小荣。
如何从队列中读取数据?
当吕小荣下次登录时,通过这个简单的查询即可获得所有 @吕小荣 的内容。
select * from mention_feeds
where user_id = 1
order by event_id desc
2.5 对 MySQL 的总结
一个 event 可能会分发到多个表里。
MySQL 并没有队列 (queue),是用关系表在模拟 queue。
-
在各个关系表中读取 feed 内容时,按 event_id 逆序排序,所以不需要担心关系表的写入顺序。e.g.
select * from mention_feeds where user_id = 1 order by event_id desc 相对 Redis,MySQL 对冷数据和热数据的处理游刃有余。
很多人担心容量问题,我觉得是多虑。主键为 big integer 单张表的最大容量是 10 billion billion。大部分人的业务并没有到新浪微博/facebook 的体量,使用 MySQL 绰绰有余。如果确实体量很大,可以做单张表的 partition,使用 hash partition 预先分几十 partition 即可。
为了应对不同的业务场景,你可以创建各种各样的关系表,非常灵活。
MySQL 的写入效率是一个值得担心的事情。
每个关系表的索引要建好。
3. 行业内其他人的做法
我待过的公司,用户量最大的就 2000+ 万,所以并没有经历过 Facebook/微博/微信 那种体量。对于他们肯定有更高端的做法,已经超过我的想象力了。
阿里云介绍 TableStore 在 Feed 流系统中的使用,Pinterest 用了 HBase。不管采用哪种设计,通过推的方式冗余数据,提高读的效率都是很有必要的。