-
有没有好的 report generate 解决方案 at April 23, 2020
我们公司用的 https://mode.com/ ,数据团队直接写 SQL 生成可视化报表。
备选:Periscope Data
-
请问如何生成形如 “V2UJY1FlBzdTbVI9” 这样的字符串来作为主键? at April 18, 2020
require 'securerandom' SecureRandom.hex #=> "eb693ec8252cd630102fd0d0fb7c3485"https://ruby-doc.org/stdlib-2.2.10/libdoc/securerandom/rdoc/SecureRandom.html#method-c-hex
-
[上海][2020 年 4 月 14 日] Ruby Tuesday 线上聚会召集 at April 14, 2020
默默会开始了
-
为了能够 “博客” 日更,我给自己开发了 fleself.com at April 09, 2020
我现在用的 DayOne,希望有朝一日能有开源的工具,开源的工具活的更久。
而且 git 让人更放心。
-
为了能够 “博客” 日更,我给自己开发了 fleself.com at April 09, 2020
数据存储是基于 git 吗?
-
有像 Rails Tutorial 类似的 Go 入门材料吗? at April 08, 2020
go by example +1
-
使用条件请求,服务器日志显示返回 200,但客户端接收为 304 at April 03, 2020
你可以试试这个命令,把 etag 改成乱七八糟不存在的值,看看返回的是不是 200
curl -i 'http://127.0.0.1:3000/' -H 'If-None-Match: not-exist-etag' -H 'If-Modified-Since: Thu, 02 Apr 2020 08:01:57 GMT' --compressed
-
使用条件请求,服务器日志显示返回 200,但客户端接收为 304 at April 03, 2020
我有两个怀疑的点
Rack
Rack::Etag 会自动帮 http code 为 200 的 response 计算 etag
Rack::ConditionalGet 会比较 etag 和 last_modifed. 如果 etag 和请求的
If-None-Match匹配的话,它会自动帮你改为 304
对应关系
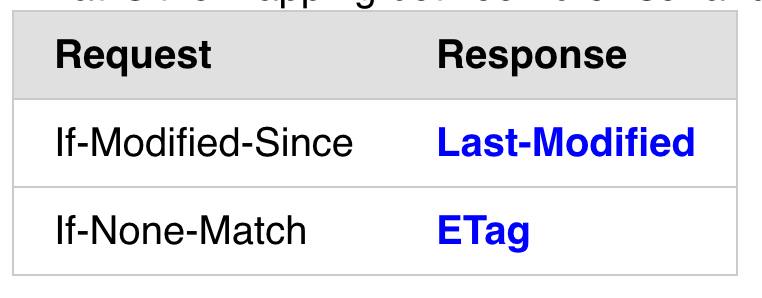
from RFC 7232:
A recipient must ignore If-Modified-Since if the request contains an If-None-Match header field; the condition in If-None-Match is considered to be a more accurate replacement for the condition in If-Modified-Since, and the two are only combined for the sake of interoperating with older intermediaries that might not implement If-None-Match.
etag 的优先级高于 last_modified, 当你的 response 含有 etag 时,浏览器可能会忽略掉 last_modified。
Ngninx
nginx 也会帮你重新计算了 etag,把你的 nginx 的这个选项关掉试试?
Syntax: etag on | off; Default: etag on; Context: http, server, location This directive appeared in version 1.3.3.参考资料
-
周末折腾了一个 landing page,一个 agile 项目管理工具,大家来敲个砖吧... at April 02, 2020
-
可能会影响程序员职业生涯的七本书 at March 26, 2020
都是好书。
不过居然漏了《颈椎病康复指南》😀
-
讨人厌的后缀表达式 at March 26, 2020
只要不超过 80 个 character,我就可以接受。
-
周末折腾了一个 landing page,一个 agile 项目管理工具,大家来敲个砖吧... at March 23, 2020
真是多产
-
远程办公:如何提高自制力? at February 11, 2020
[Remote] Looking for experienced remote Web/App engineers
-
远程办公:如何提高自制力? at February 09, 2020
给你看个魔鬼手机的短信截图
-
远程办公:如何提高自制力? at February 09, 2020
对于我来说最浪费时间(管不住自己)的就是微信。只要能管住微信,其他 App 对于我来说问题不大。
但是有些企业喜欢用微信来安排任务,就特别烦,我的方法对你们就不管用了。我有个朋友每次入职新公司,都会注册一个新的微信,离职时就删掉。
这或许也是个方法。
-
远程办公:如何提高自制力? at February 09, 2020
主号 (天使手机) 和小号 (魔鬼手机)
我每天都会用到魔鬼手机,它本身就是我的一个小号,注册网站留的号码都是它。
- 一兆韦德健身房
- 平安证券 / 富途证券 / 老虎证券 / 雪球
- 中国银行/招商银行的注册号码是小号,余额 短信提醒我设的是我的主号。
- 京东/拼多多/网易严选/淘宝的收货地址中的号码
- 优酷 / 爱奇艺
- 财新
- 等等
所以只要需要收验证码,我肯定要用到魔鬼手机。
时间
就让正文所说,我只有 16:00-20:00 才可以使用魔鬼手机。
(但是如果家里有特殊情况,我老婆也会给我解禁。比如现在我的英雄媳妇已经上抗疫一线,没有住在家里。我现在又当爹又当妈,照顾娃,外卖买菜,她就把密码去掉了)
我不理解你们俩的问题,所以只能按照自己的理解来回答了,希望能回答你们的问题。
-
远程办公:如何提高自制力? at February 05, 2020
-
远程办公:如何提高自制力? at January 30, 2020
使用两部手机还有个好处。天使手机的号码留给自己的家人和朋友,魔鬼号码留给销售/注册网站/收验证码。
一来可以保护自己的隐私,而来可以防止收到骚扰电话。
我的“魔鬼手机”里不放任何个人信息(比如通讯录)。所以即使安装了一堆没节操的软件,它们也偷不到什么个人信息,
出门在外,房产中介/销售/保险经纪人(所有不喜欢的人)如果和我要电话号码,我就留“魔鬼手机”的号码。响铃从来不接。
以恶制恶,落个清静。
-
远程办公:如何提高自制力? at January 30, 2020
做什么事会让你提上很高的兴趣呢?我想是这样:这件事不会特别难,如果太难,难到超出你的能力太多,你可能就提不起兴趣,二来,可能这件事会让你有趣,或进步,如果太无趣的工作,我也不太想干。
你说的点很好。有书专门描述这种状态,书名叫《创造力》《心流》
-
远程办公:如何提高自制力? at January 29, 2020
谢谢华顺。
-
远程办公:如何提高自制力? at January 29, 2020
宅在家里没事,我就写了篇文章,玩一下公众号。
真的只是顺便招聘,如果你们反感,我去掉就是了。😀
-
[过春节长知识] Rails log 的小知识 at January 29, 2020
当时没完全看明白,似乎是:
middleware 生成 request id 后,写到了 thread local variable 中的。
到了写 log 时,把 thread local variable 中的东西读出来。
我的理解对吗?
-
[上海][2020年1月21日] Ruby/Rails 聚会召集 at January 21, 2020
最近肺炎有疫情,不建议去人口密集的公共场所。
-
[上海][2020年1月21日] Ruby/Rails 聚会召集 at January 20, 2020
你的贴每次都发的有点突然啊。
-
RubyConf China 2020 先行调查表 at December 10, 2019
填好了
-
[深圳][已结束] 2019-12-07 Ruby 技术活动 at December 07, 2019
你去深圳啦?
-
[上海][2019年12月03日] Ruby/Rails 聚会召集 at December 02, 2019
我也参加,想拜读一下大家的 micro service 是怎么写的,比如:
- Golang 的 Service 是怎么单独部署的
- Ruby 和 Golang 的 service 通信
等等。
道理都懂,就是想看看真代码是如何组织的。
-
中文圈貌似写独立博客的人越来越少了,我按照订阅量大概排了个序 at November 01, 2019
-
[上海][2019年09月03日] Ruby 聚会召集 at September 03, 2019
作为一个老家伙,我觉得默默会挺好,老朋友见见面,随便聊聊天。