本系列计划分四大部分:
- kafka(一) 消息队列的本质
- kafka(二) 消息的生产
- kafka(三) 消息的消费
- kafka(四) 可靠性探讨
- kafka(五) 操作系统的大腿 (待)
- kafka(六) 王朝式微,Pulsar 的冲击 (待)
引
在 Apach Kafka 眼里,自己不仅仅是消息队列,还是一个数据储存系统,同时是一个流处理利器。但不管是数据存储能力,还是流处理能力,其实都可以算消息队列的加分项,它依然是一个消息队列,不过有更强大的适应能力。
其实 MySQL 也可以实现消息队列,一头写,另一头读,Redis 更加容易实现这个。很多最终一致性的方案,就是落一条 DB 流水,然后再异步处理。这看起来也是一个消息队列,和基于 kafka 的不尽相似,又有明显不同。
我们需要有更透彻的视角来剖析消息队列,不管是 kafka,还是上面提到 MySQL/Redis 案例,它们都是消息队列的一种实现而已。基于某种本质的需求,提供出或简单或专业的解决方案。这是本文着重想要探讨的点。
消息队列的本质
有一种声音说 [1],消息队列的本质是:两次 RPC+ 一次转储。这种提法很好,是从流程上对消息队列进行了一次透视。这给了我们一个切入点。
其内在含义是:
- 第一次 RPC,将消息投放给了暂存点(生产者)
- 暂存点将消息储存起来(消息队列)
- 第二次 RPC,需要消息的一方从暂存点读取消息,或推或拉(消费者)
不可否认,上面简练地概括了基于消息队列的消息流转过程。接下来我们要问两个问题:
- 为什么能这样?
- 这样达到了什么效果?
第一个问题。为什么消息队列能表现成两次 RPC+ 一次转存呢?其最核心的根基就是,消息生产者只关系消息是否成功传递给了消息队列,而并不关心消息被谁处理,也不即时依赖消息处理的结果。这是消息队列的客观存在条件,如果没有这个前提,消息队列没有存在空间。这和同步的 RPC 请求形成了鲜明对比。
第二个问题。这能达到什么结果?基于上面的前提,消息生产者不关心谁处理,也不即时依赖处理结果,这样直接达到了两个结果:
- 解耦。
- 异步。
什么叫解耦呢?两个有联系的模块间解耦,大白话讲结果就是,一方发生变化 (发布、改代码、迭代等非协议性变化),另一方不需要跟着变化,或者对变化无感知。
例如分布式系统中,A 服务调用 B 服务,此时 A 需要知道 B 的地址,如果 A 服务将 B 的地址写死,当 B 服务发生迁移、故障等变化时,A 就要跟着修改 B 的地址,我发生了变化,你需要跟着变化。接入服务发现中心可以实现解耦,B 迁移时,A 可以通过服务发现自动适应。
对于消息系统而言,消息的生产方和消费方,虽然都和消息本身强相关,但只要消息 (流程/事件) 本身不变 (协议),双方对彼此的变化完全无感知。这是系统设计中的重中之重。
而异步更多是一种结果,由于实现了解耦合 + 转存,消息本身的处理过程天然是异步进行的。而异步本身直接带来了缓冲、削峰、最终一致性等等能力,也可更专注地实现复杂的消息转发逻辑 (广播 + 单播等)。
到此,我们简单进行了一次消息队列的透视,基于上面的推导,我们可以给消息队列下一个更深刻的定义,消息队列是:
- 处理一种特定消息的系统,这种消息的处理结果不需要被即时依赖
- 作为一个传递消息的中间角色,提供左右两端系统间解耦合的能力
- 为消息提供异步处理的能力
这便是我眼中消息队列的本质。至于广播/单播、消息重放、流处理、推拉模型、可靠投递等等都只是对消息队列本质的实现落地,而缓冲、削峰、最终一致性等是异步能力带来的结果。
实现落地
梳理完本质,我们立足于 kafka,看其是如何落地的。接下来我们对这部分做简单概述,从宏观上做一次鸟瞰,在本系列后续的内容中才逐步深入细节。
角色化
消息队列作为一个解耦合的中间商,必然有上下游对接方,这一部分早已深入人心。消息队列有三大角色:
- 消息生产者。产生消息者,它不关系消息的处理结果
- 消息队列。Broker,集群模式下,会有多个 broker
- 消息消费者。消息处理者,它不感知生产者,且可以存在任意数量,可以彼此完全独立。
参与交互的系统、组件等都可以被划分为以上三者之一。角色化为系统的划分,消息的传递处理等提供了便捷的沟通语言。
三大角色 来源 [2]:
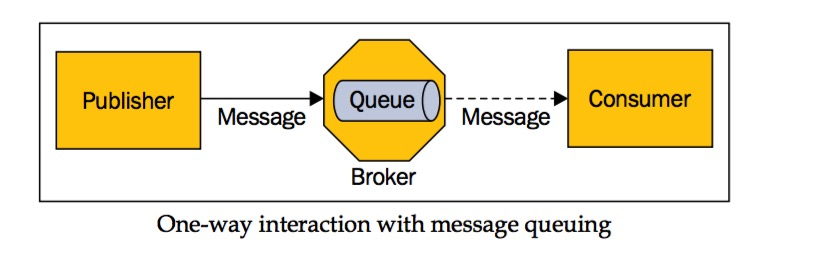
消息队列 (broker) 接收来自生产者的消息,存放到自己磁盘上,等消费者自己来拉数据。同一条消息可以被多种消费者消费,消费者直接可以不相关。
每一条消息在逻辑上只属于某个 Topic,实际上 Broker 对于不同的 Topic 消息是已单独的文件存放,而消费者拉取时,也要明确指定拉哪个 Topic 的消息。生产和消费过程中,涉及 Topic、Partition、Group 等概念或角色,此处不再赘述这些深入人心的概念。
专注核心
在众多消息队列的落地实现中,kafka 算是一个极为专注核心的角色,它将很多东西都外放给生产者和消费者自己实现,自己则解决核心的消息存放、集群管理等。换成批评的角度来将,kafka 将生产和消费过程中的复杂度抛给了生产者和消费者,这使得 kafka 生产者和消费者的实现复杂度很高,使用成本也随之上涨。
一、消息生产
假设生产者往一个有多 broker 的 kafka 集群投递消息,某条消息到底该投递给哪个 broker?策略怎么定?
这些 kafka 自己是不管的,它将某个 Topic 的 partition 分布完全暴露给生产者,生产者自己定时来拉这些元信息 (通过任意 broker)。由生产者自己连对应的 broker,消息要发到哪个 broker 由生产者自己决定,是通过 key 做 hash,还是随机遍历投,由生产者自己定。(自己计算出 partition,并发到对应的 leader 节点)
这完全不像有些消息队列,暴露代理节点出来,消息到底去哪儿对生产者透明,生产者只管无脑将消息发给代理进行,不需要关系集群的信息。
二、消息消费
消费模型有推拉两种之分。推就是消息队列自己主动将消息推给订阅者。例如 rabbitmq,会将消息推给订阅者,并提供 ack 机制,如果失败了还可以自动重试。消费者只需要连 rabbitmq 告诉它要订阅什么消息即可,实现相对简单。
而 kafka 则选择的拉模式,消费者自己来 broker 拉消息,具体处理到什么位置了,可以告诉 broker,帮你记录下。至于消息消费到后怎么处理处理失败等情况由消费者自己解决,没有像 rabbitmq 那样可以自动触发重试。
消费过程相对复杂,在负载均衡上还涉及复杂的 rebalence 等。
通过将生产和消费两端的策略外放,kafka 将自己本身的复杂度收拢到消息转存本身上,虽然使得使用方需要实现复杂的生产/消费程序,使用成本较高。但可以换来 kafka 本身的简洁,这背后的结果是技术透明、可扩展、高性能、灵活性等等好处。
极致特性
通过外放策略得到灵活和性能的同时,kafka 也利用了不少操作系统的 feature,例如顺序日志、异步刷盘、内存映射等。还有特有的文件存放策略,实现高效的消息定位等。这些使得 kafka 能轻松跑出百万级 tps,在性能上秒杀了众多消息队列。
总结
本文作为本系列的开端,着重从抽象的视觉来探讨消息队列的本质。与同步的 RPC 不同,消息队列处理那些不被即时关心处理结果的消息,并在过程中提供解耦 + 异步化的能力。
这为后续的内容展开提供了宏观的知识框架,关于生产、消费、关键技术特性等将会在接下来的内容中逐步展开。