本系列计划分四大部分:
- kafka(一) 消息队列的本质
- kafka(二) 消息的生产
- kafka(三) 消息的消费
- kafka(四) 可靠性探讨
- kafka(五) 操作系统的大腿 (待)
- kafka(六) 王朝式微,Pulsar 的冲击 (待)
本系列前三篇介绍了消息队列的要素,以及 kafka 的生产和消费过程,实现从抽象到实际的一次知识缝合。在串联知识点的过程中,跳过了一些关键点,缺了它们会有隔靴搔痒之感。
本文主要探讨可靠性方面的一些点,主要内容围绕:
- 在故障发生时,数据一致性靠谱吗?
- kafka 可以保证消息不丢失吗?
不变的阳谋
分布式系统可靠性的建设 (机器),和公司团队可靠性建设 (人),其底层逻辑是一致的。大道至简,大道相通。
一般情况是 20-%的人创造了 80+%的核心价值,但人一旦吃饱了就容易骄纵懈怠,战斗力就缩水了。想要搭建一个战斗力爆棚同时产出稳健的团队可以怎么做?在定制好良性竞争机制之后,核心点就是堆人 (才),在切割单点不可替代性后,还要建立纵向梯度。你虽然是首席,但二把手可以随时上,三把手也在等着。
分布式系统呢,如何稳健?实际上是一样的:
- 堆足够量的机器,>=50% 作为副本存在
- 将集群压力切割分散在众多机器上
- 设立 leader 节点 (Master),数据同步给副本(一致性)
- 副本可以随时替代 leader(可用性)
可用性的来源
当集群的压力分散隔离到多个机器上时,个别 broker 出现故障,并不会影响其他 Topic 的生产和消费 (broker 量较多)。因为数据同步给了副本,可以替代 leader 迅速恢复服务,以此便实现高可用。
聚焦到本文的主题,我们需要理清楚两个问题:
- 数据同步相关的细节
- 故障恢复时一致性问题
在此基础上,尝试探讨 kafka 是否能保证消息不丢失。
副本数据同步
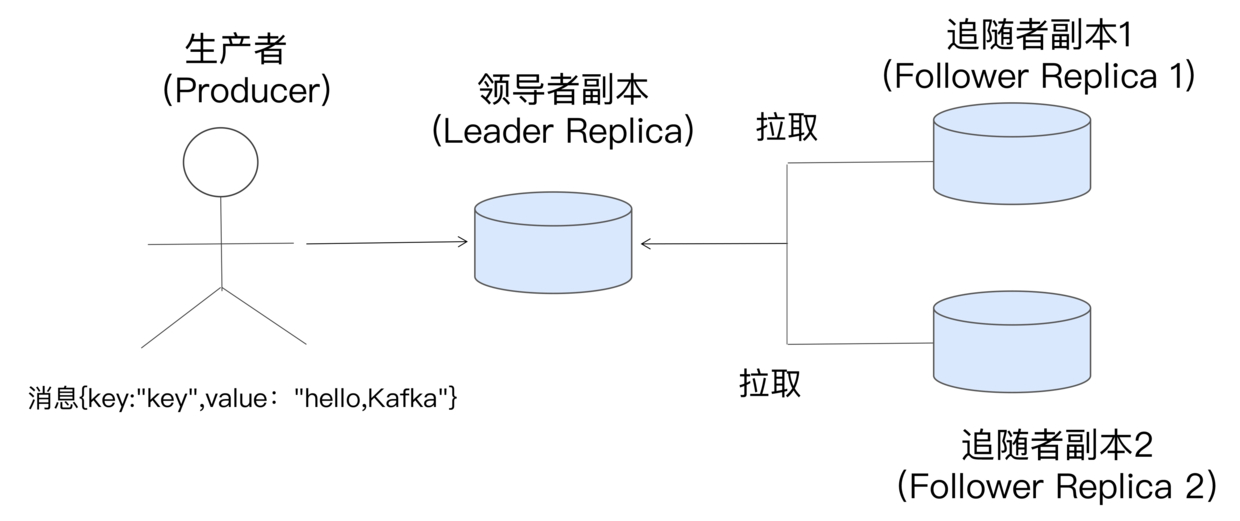
回顾kafka(二) 消息的生产中数据同步的部分,每个 Partition 有一个 leader,有 x 个副本,生产者直接向 leader 创建消息,副本通过接口向 leader 轮询获取最新消息,实现数据同步。
 涞源 1
涞源 1
当 ack=all 时,leader 会等所有 ISR 集合的节点拉到消息后才会返回成功,确保数据同步到了副本上。每次副本轮询时会带上想要的 offset(fetch_offset),这是副本上最新的消息偏移量,由此 leader 便可以知道每个副本现在同步到哪儿来了,意味着小于 fetch_offset 的消息都已经同步成功了。(类似 TCP 的 ack)
通过数据同步时延 (replica.lag.time.max.ms) 可以对 ISR 集合进行伸缩,将慢节点踢掉,如果速度恢复了会再加回来。其原理是,每当副本的 fetch_offset 等于 leader 的 LEO(下一条消息的偏移量),leader 会更新对应节点的 lastCaughtUpTimeMs 值 (完全追上后才会更新),kafka 通过定时任务扫每个节点的该值,如果 time.now-lastCaughtUpTimeMs > replica.lag.time.max.ms,则该副本落后了,会记录起来,通过另一定时任务将其踢掉。
ISR 本质上是个优质副本集合,也可能只有 leader 副本一个节点 (其他因为慢被踢掉了),这算是“少数服从多数的”一种实现 (PacificA)。类似 raft 的超过半数提交,实际上是通过最快的部分节点实现“少数服从多数”,从对比上看同等规模下 kafka 可以实现更少的副本节点 (副本越多生产越耗时),使用者也可以通过 min.insync.replicas 实现数量控制,这将灵活性交给了使用者。
消息可见性
kafka 消息的生产和消费都是围绕 leader 进行的,副本全程只是默默复制数据。那当消息写入 leader 时,哪些消息能被消费者看到?如果写入 leader 就被消费者看到,假设此时消息还未同步到副本,leader 节点又挂了,副本重新成为 leader 后,便会出现“幻读”,有些消费者消费到了该消息,有些则消费不到,因为新 leader 上没有。
 涞源 1
涞源 1
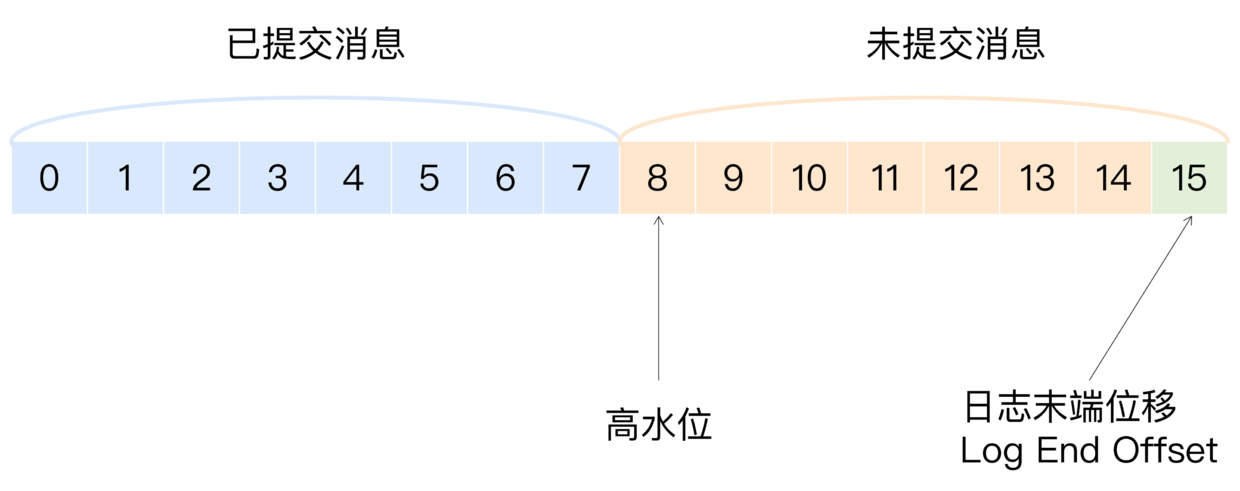
对于此,kafka 提供了分区高水位的概念,一方面定义消息的可见性,另一方面也辅助了消息同步到副本。其值计算逻辑很简单,HW = max(currentHW, min(副本 LEO))。也就是说分区高水位取决于最慢节点的最新一次 fetch_offset 值,这直接衡量了副本的同步情况。
比高水位大的消息对消费者不可见,也被称为未提交消息。副本在拉消息接口中,leader 也会将高水位值返回给副本,副本接着更新自己的高水位 (min(leader-HW, 自己 LEO))。但分区高水位是指 leader 高水位,副本高水位用于故障恢复时日志截断。
总结下两个概念:
- 分区高水位 HW,也是 leader 节点高水位值,控制消费者可见性,避免“幻读”,也直接记录副本同步情况。由节点列表中 (在 ISR 中且未同步延迟) 最慢的节点决定。leader 更新公式:max(currentHW, min(副本 LEO)),副本公式:min(leader-HW, 自己 LEO)
- LEO(Log End Offset),末端位移,下一条将要插入消息的 offset。
故障恢复
每个 broker 和 zookeeper 有心跳,当某个 leader 没响应了,controller 可以通过 watch 机制得知,并开启故障转移。(见kafka(二) 消息的生产)
当发生 leader 切换时,数据一致性便会经受考验。在 kafka0.11 之前,当 leader 发生切换时,副本会将自己本地的日志按照高水位 (副本自己的) 截断删除,然后将 fetch_offset 设置为高水位值向新 leader 发起同步请求,这里面可能会出现数据一致性问题。
高水位的缺陷
根源在于 leader 的 HW 更新和副本 HW 更新存在时间差。下面是几个回合 HW 的更新,右边是 leader,左边是某个副本:
 涞源 2
涞源 2
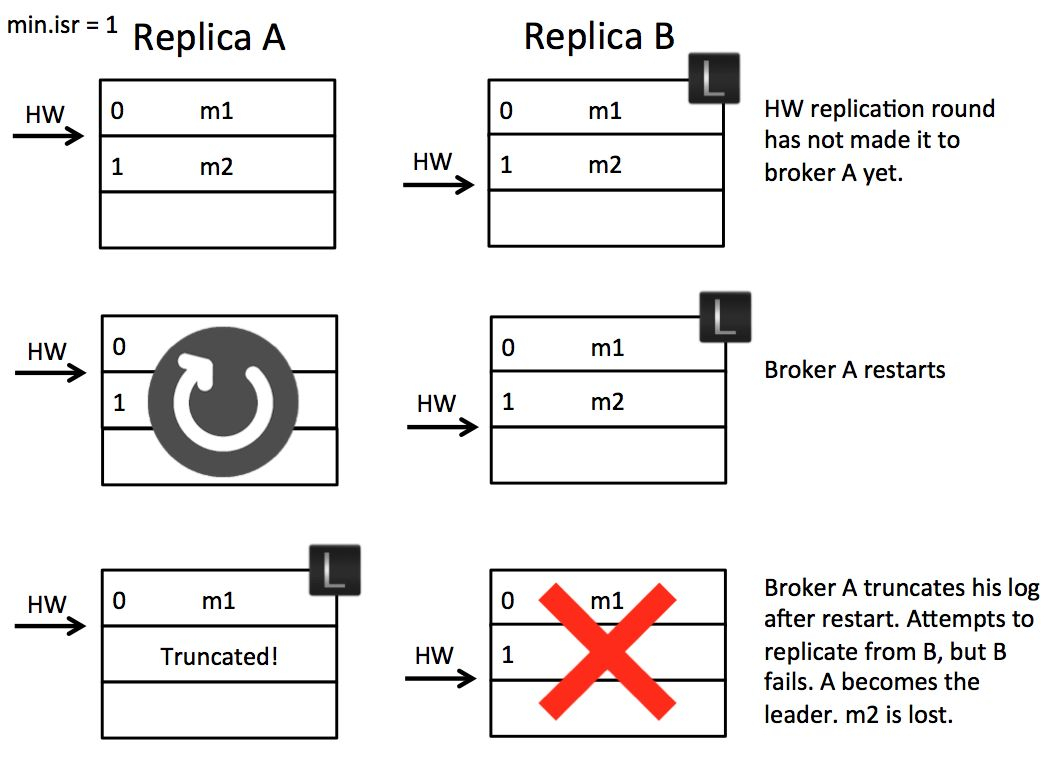
图上共有三排,第一排时序:
- leader B 中有两条消息 m1 m2
- 副本 A 带上 fetch_offset=1 拉 m2 这条消息
- 此时 B、A 的 LEO 均为 2,HW 为 1
- 副本 A 带上 fetch_offset=2 继续拉消息
- B 将 HW 修改为 2,A 需要等接口返回后才能将 HW 修改为 2,此时会出现时间差。如果 B 中没有新消息则会延迟返回,时间差还会进一步拉大。
假设在这个时间差之间,A 崩溃了,时序如下:
- A 奔溃,此时其 HW 为 1(上图第二排)
- A 恢复后,则会将 m2 删除
- 以 fetch_offset=1 向 leader 拉消息。假设此时 B 也奔溃了
- A 会成为新 leader
- B 恢复后成为副本,其 HW 为 2,比 leader 高,会将 HW 改为 1 并截断 m2,fetch_offset=1 向 A 拉消息
- 最终结果是:m2 这条消息丢了
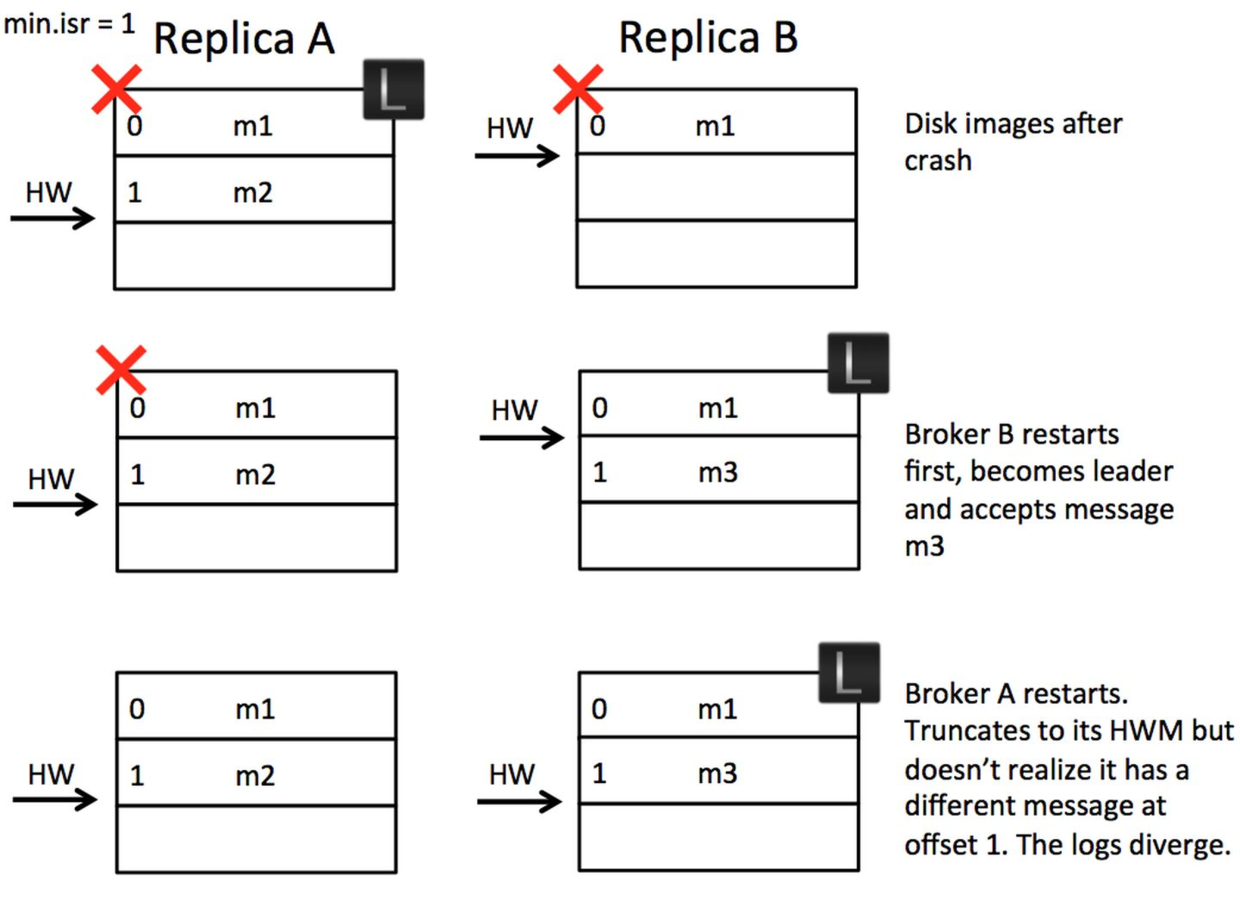
假设 leader 等副本更新完 HW 后,才更新自己的 HW,则可以避免上面的问题,但这需要多增加一轮数据同步请求。而且换一个时序,也会出现数据不一致问题。
 涞源 2
涞源 2
- A 为 leader,LEO=HW=1。B 为副本,LEO=HW=1
- 假设 A、B 同时挂掉
- B 先恢复,成为新 leader
- 生产者向 B 创建了一条新消息 m3,此时 HW=LEO=2
- A 恢复称为副本,HW 和 A 一样,不需要截断,fetch_offset=2 也拉不到新消息
- 最终结果是:A 和 B 之间数据不一致。
上面的问题会出现在 min.insync.replicas=1 的情况下,也就是某时刻 ISR 中只有 leader 节点,由于 min.insync.replicas=1,此时也可以生产消息,数据只提交到了 leader 节点,便返回成功给生产者。
假设 min.insync.replicas>1,上面问题理论上不会出现。(严肃性故障下文讨论)
- 如果 ISR 中只有 leader 副本,此时 kafka 会返回错误,告诉生产者现在不能生产,这样不会有数据问题。
- 如果 ISR 中有其他副本,leader 会等其他节点 fetch_offset>[消息的 offset] 时,才会返回成功给生产者,此时 HW 均已经更新了。 ## Leader Epoch 上面数据问题的根源在于,故障恢复后 HW 被新 leader 更新,但副本的 HW 还是原来的,一旦同步便会产生问题。如果能将 HW 按照变更前的状态返回给副本,则可以避免问题。
Leader Epoch 便是起这样的作用:
- Epoch。一个单调增加的版本号。每当副本领导权发生变更时,都会增加该版本号。小版本号的 Leader 被认为是过期 Leader,不能再行使 Leader 权力。
- 起始位移(Start Offset)。Leader 副本在该 Epoch 值上写入的首条消息的位移。
- 组合起来 Leader Epoch 便类似于: 。epoch 为当前版本,leader 变更后会 +1,startOffset 是当前新 leader 第一条消息的 offset。
- broker 会在内存和磁盘中存放 leader 的 Epoch 值。
当有副本重启后归来,带上自己保存的 leader epoch 值,先向 leader 发起一轮请求,获取当前 leader 的 epoch 值。
- 如果两者 epoch 值一样,则 leader 返回当前自己的 LEO 给副本。此时副本 LEO 理论上<=leader LEO,不需要截断,正常同步数据。
- 如果两个 epoch 不一样,说明副本持有的 epoch 是上一轮老 leader 的 (可能落后多轮),此时新 leader 根据老 epoch 返回 [老 epoch+1] 记录的 startOffset 给副本。(假设只差一轮的话,则返回当前 epoch 的 startOffset)
- 副本根据 startOffset 进行截断逻辑。如果返回的 startOffset 大于等于自己的 HW,则不会删除消息,原消息得到保留。否则截断从 leader 重新拉取,这避免了不一致。
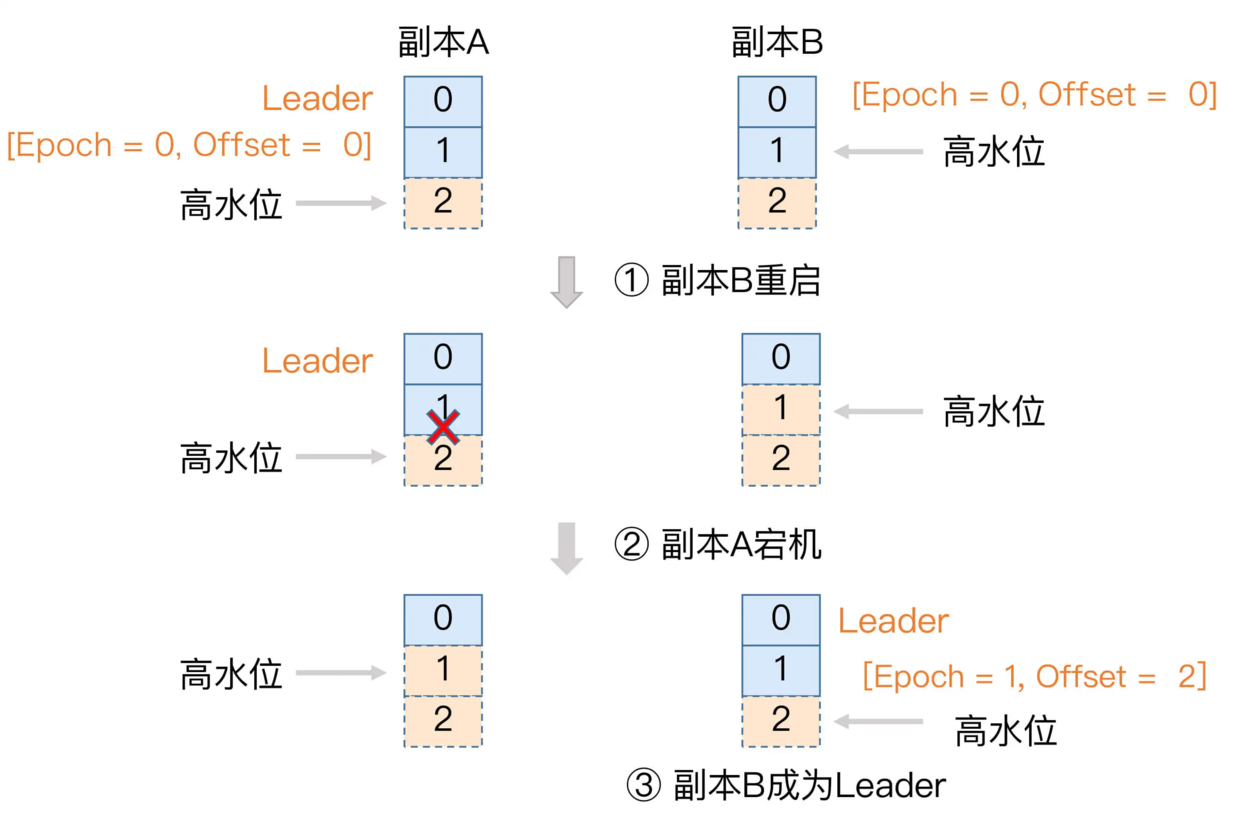 涞源 2
涞源 2
消息能不丢么
上文大致梳理了数据同步,以及故障恢复的一些细节。现在我们需要问一个更大的问题:
kafka 能保证消息不丢么,或者说要做到消息不丢失,该如何配置 kafka? 前文提到了,当:
- 生产者得到 kafka 生产成功回复时,才认为成功,否则重试
- ack=all,消息同步到 ISR 中时,才返回成功。
- replication.factor >= 3,副本数量多一些
- min.insync.replicas > 1, ISR 数量超过 1 个才提供服务。
- replication.factor > min.insync.replicas,如果相等只要一个节点挂了,便会拒绝服务
- unclean.leader.election.enable=false,必须要 ISR 的成员才能称为新 leader
上面几个条件同时生效时,kafka 的明确告知生产成功的消息是有保障的,至少落到了某个 ISR 节点中,等待重启完毕便可以恢复数据。
但这是有前提的,因为 kafka 的消息是写入内存便认为提交,副本同步也是一样:
- 副本告诉 leader 消息已经同步成功,实际上可能还在内存中没有刷盘,奔溃后数据丢失
- 副本告诉 leader 消息同步成功,此时已经刷盘,但这个副本磁盘故障,数据会丢失
当出现了上面的情况时,kafka 依然会丢失消息,只不过副本数量越多,上面参数配置的越苛刻,丢失数据的概率会减小,毕竟没有向 MySQL 那样同步刷 redolog 到磁盘。
这个问题的答案是,当上面的一系列参数都配置正确,kafka 对"已提交"的消息,可以在一定程度上保证数据不丢失:
- 已提交。上面 ack=all 等参数配置,且 kafka 明确返回成功
- 一定程度。kafka 的多个副本至少有一个没出问题 (刷盘前 crash 或磁盘故障等)