本系列计划分四大部分:
- kafka(一) 消息队列的本质
- kafka(二) 消息的生产
- kafka(三) 消息的消费
- kafka(四) 可靠性探讨
- kafka(五) 操作系统的大腿 (待)
- kafka(六) 王朝式微,Pulsar 的冲击 (待)
在 (一) 中简要探讨了消息队列的抽象模型,可分为两部分:
- 生产。生产 RPC + 存储
- 消费。读取 + 消费 RPC
上一篇 (二) 中,我们从 client 和 server 两个视角,梳理了消息生产的整个过程,涉及请求的处理过程,以及集群的一些方案和权衡。这其实是 kafka 对于消息队列在消息生产上的具体实现。
本文我们将再次回到消息队列本身属性,来看待 kafka 的消费过程。
消费的要素
消费消息是个很简单的概念,其实就是拿到生产者创建的数据,kafka 在生产者和消费者之间做了一次转手。我们从 kafka 的视角出发,如何把消息转给消费者,这个过程中有哪些基本诉求?可见的有:
- 简单、可靠、快
- 消费能力可扩展
- 基本的单播、广播能力 (基于消费者 Group)
我们先从消息存放开始。
消息存放
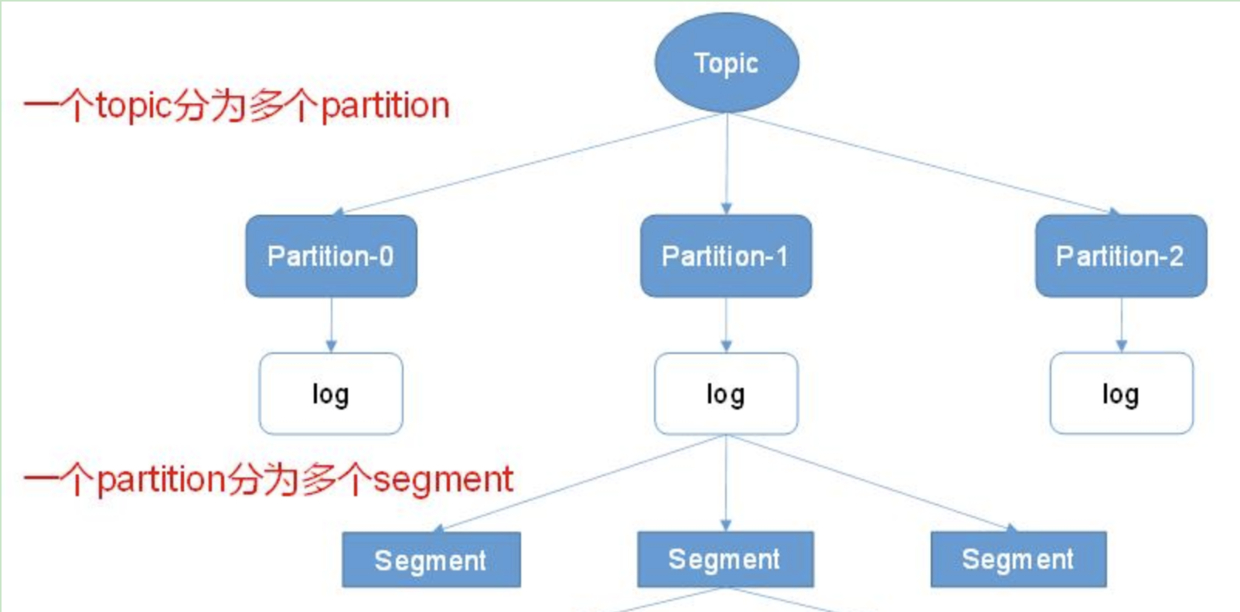
消息在逻辑上属于某个 Topic,每个 Topic 有多个 Partition。在物理形态上,Topic 和 Partition 都是以文件夹的形态存在,消息数据就存放于这些文件夹里面。
Segment 分而治之
逻辑上消息存放在对应 Partition 目录中的某个文件里,为了防止单个文件过大,在物理形态上,会分成多个数据分段 (Segment),每个分段存放的数据量大致固定,以追加的方式存于文件末尾,当文件体积到一定阈值,则创建新的分段 (消息只会写入最新分段中),Partition 的消息就分布在这些分段文件上。
类比数据库,当数据写入后可以得到一个 ID,通过 ID 可以找到数据。kafka 不需要这么复杂,每个消息写入文件时都是追加在文件末尾,追加时可以根据当前 Partition 的消息量 (N),得到当前消息的偏移量 (offset=N-1),并将改偏移量写入消息体中,消费者按照偏移量读取即可。
###查询必有索引 消息存放完毕后,问题来了,当消费者希望读取某个 offset 的消息时,如何快速地定位到数据?就像数据库中以 ID 来读取数据一样。
要快速查询,必然需要索引,否则可能涉及遍历整个 Segment,kafka 在存数据时,会维护 offset 对应的索引:【offset=>物理地址】,应对快速查询。每个 Segment 都有独立的索引文件。
索引很简单,其目的是为了快速找到对应 offset 的数据。只要维护一个 offset 和其存放物理地址的映射即可解决。
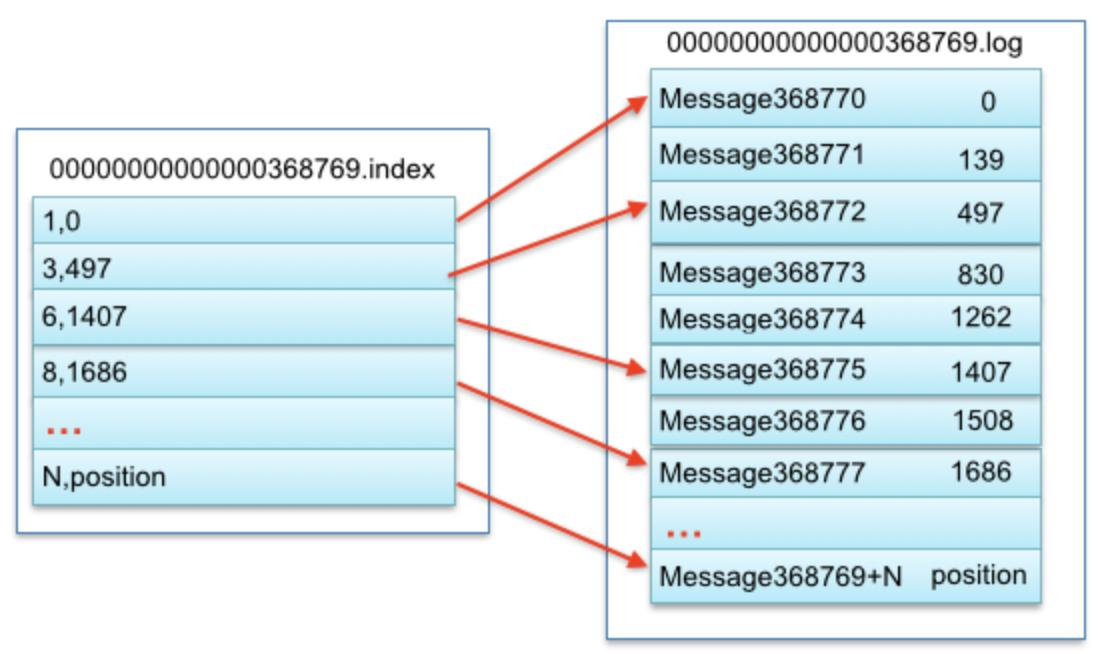
由于消息量巨大,不能每个 offset 都维护一个映射,kafka 选择了稀疏索引,即隔一段才存一个映射。根据二分查找可以找到小于等于目标 offset 的消息物理地址,再从分段文件中顺序读取即可。相应的逻辑,kafka 还会维护一个【时间戳=>偏移量】的索引,方便按照时间戳查询数据。
消费过程
消费过程,其实就是把上面 Segment 中的数据按某种策略提取出来。从消息队列的视角出发,这个过程有几个核心的方向:
- 框架:消息队列的推拉模型、消息队列的单播广播能力
- 记录:消费过程的记录,需要标记哪些消费过了哪些没有消费
- 扩展:消费能力的横向伸缩、负载均衡
接下来将从以上几个点展开,通过梳理消费过程,串起平时接触到的知识碎片。
推拉框架
消息队列的消费有着两个基础模型:
- 推:消息队列将消息推给消费者
- 拉:消费者自己从消息队列拉消息 (轮训)
这两者的核心差别在于: 谁驱动消费行为,谁为消费动作负主要责任。推模型将消息消费的主要责任放在了消息队列这一边,对应的职责则有:
- 新消息产生后,主动推给消费者,敦促其处理
- 对消费过程负责,将消息数据有章法地推给消费者,达到负载均衡效果
- 对消费结果负责,如果消费失败,涉及自动重试,消费成功则标记
而拉模型则是反过来,将以上职责主要推给了消费者。
我们都知道 kafka 选择的是拉模型,其目的也非常明确,在 (二) 中我们已经提到过,kafka 的定位在于超高量级的吞吐能力,如果以上几个职责需要消息队列负责,其实现复杂度会较高,吞吐能力很难上去。rabbitmq 和 kafka 的吞吐能力差别就是很好的例证。
推拉模型决定了消息队列的消费行为,推拉之间差别巨大。消费者的一切弯弯绕其实就是在完成上面的三个职责。
如何获取新产生的消息
当生产者创建了新消息时,kafka 会将其存放到对应的 Partition 分段文件中,按照先后顺序有序追加到文件末尾,每个消息都有一个偏移量,由生产的先后顺序决定。
拉模型决定了,kafka 把消息存放好后,就啥事也不干了。因为处理新消息是消费者自己的职责。消费者如何感知到新消息创建,并拉取到呢?理论上只能轮询。
实际上,消费者就是通过 kafka 提供的 FETCH 接口,不断地轮询,一批批地从 kafka 将消息拉下来,然后分发处理,处理完后继续拉下一批。
FETCH 接口的处理流程,和消息生产类似,本质都是接口,只是一个是读一个是写,详细过程在 (二) 中已经交代过,感兴趣可以回看。
可扩展的消费能力
当消息量级到一定程度时,可扩展的消费能力就极为重要,这本质是负载均衡策略。
kafka 在生产消息时,将写压力分散到 Patition 上,因为 Partition 数量可横向增加,生产能力便可以随之扩展。在消息的消费端,kafka 沿用了这种能力,消费者的负载均衡策略也是基于 Partition 展开。
消费能力基于 Partition 扩展
一个 Partition 最多被一个消费者同时消费 (同一个 Group),按照消息偏移量 offset 顺序 FETCH 即可,一个消费者可以同时消费多个 partition 上的数据。同一个消费者 Group 下消费者数量的最大值=对应 Topic 的 Partition 数量,理想情况下是一个消费者独立消费一个 Partition 的消息。(多出的消费者消费不到数据)
当消费能力出现瓶颈时,增加 Partition 的数量,就可以增加消费者的数量,消费能力便自然得到扩展。
基于此,kafka 可以实现消息的顺序消费,同一个 Partition 上的消息,可以被对应的消费者顺序读取处理 (生产时的顺序)。这是一个非常重要的能力,可以极大简化对消息顺序敏感的业务的技术实现,例如基于 binlog 消息的处理。
消费者和 Partition 的消费关系,有诸多疑问:
- 谁来决定某个 Consumer 消费哪个 Partition?
- 当有 Consumer 新增或退出后怎么办?
- 谁来负责管理 Consumer?如果其奔溃假死怎么办?
- 整个流程框架是什么?
消费核心流程
在拉模型下,一切都需要消费者自驱动,kafka 只提供能力和流程。
要实现上面提到的消费者和 Partition 的消费结构,必然需要有一个角色来掌控整个消费流程,就像生产流程中的 Leader 副本一样。
消费协调者
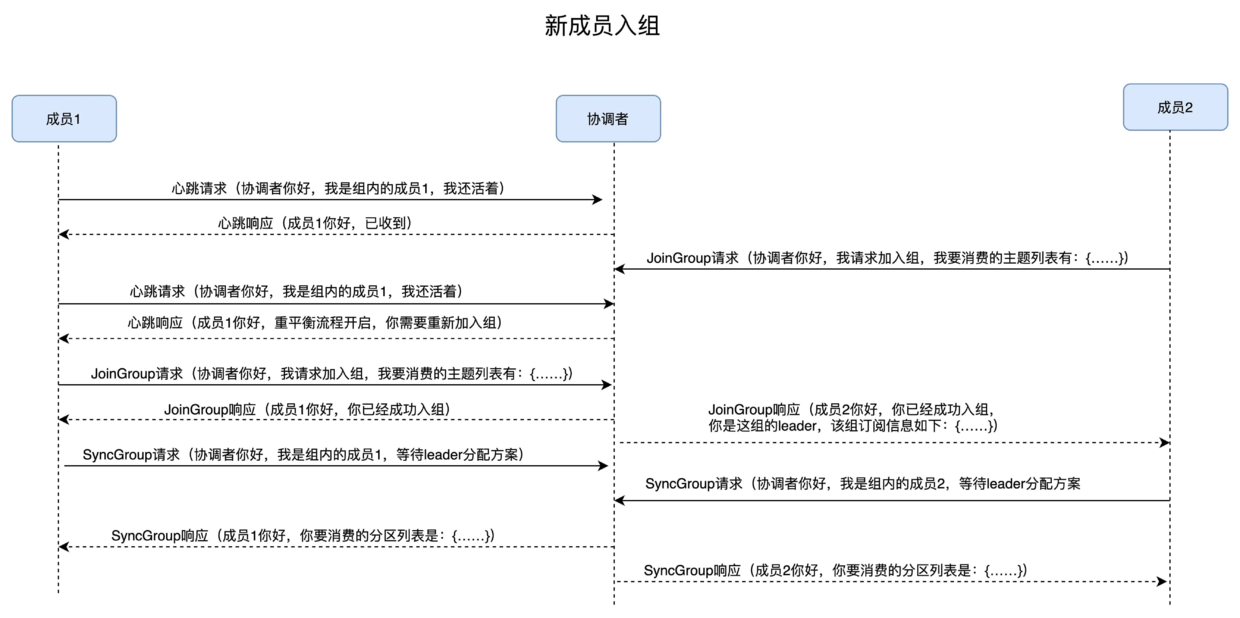
为此 kafka 设计了一个 Coordinator 组件来支撑消费过程,消费者想要消费某个 Topic 的数据:
- 需要先向 Coordinator 注册 (JoinGroup),Coordinator 是某一个 Broker(下文交待)
- Coordinator 会在消费者中选择一个作为 leader(一般是第一个 JoinGroup),Coordinator(kafka) 将所有注册的消费者发给 leader (每个 Group 一个 leader,从消费者中选出)
- 由该 leader 分配哪个 consumer 消费哪个 Partition,然后将分配结果发给 Coordinator
- Coordinator 再分别告诉消费者结果,消费者自行从目标 Partition 所在 Broker 拉消息
每个消费者需要定期向 Coordinator 发送心跳消息,表明自己还在正常消费数据。
当发现有 consumer 超过一定时间未发送心跳时,Coordinator 会认为他退出了,此时消费者会少一个,这个消费者对应的 Partition 便没人消费了,此时 Coordinator 会重新触发上面的流程,这就是大名鼎鼎的: Rebalance(重平衡)。
rebalance 的触发时机有:
- 组成员数量发生变化,Consumer 新增、推出、失联 (心跳停止),Coordinator 可以感知到
- 订阅主题数量发生变化
- 订阅主题的分区数发生变化
当上面任一个时机触发,Coordinator 会在心跳请求 response 中告诉所有消费者,所以 Consumer 最快会在一个心跳周期中,知道要 rebalance,然后重新发起消费请求,等待分配结果,然后连上目标 Partition 重新开始消费。
Consumer 得知开始 rebalance 后,会停止从当前的 Partition 拉消息,等待新的分配结果。新结果很可能不是当前的 Partition,因此 rebalance 时,整个 Group 的消费行为会停止,直到整个过程完毕。
 涞源 1
涞源 1
rebalance 是为了保证整个消费结构平衡,实现消费者顺序消费 Partition 的消息。这也导致了非常非常多的问题,最最常见的之一,就是有些消费者有 bug,不断地在断开重连 (或心跳超时),使得 Coordinator 始终在做 rebalance 的调度,消费行为一直停滞不前。
消费位移记录
每个消费者 Group 可以独立消费 Partition 上的数据,他们必须要记录自己消费到什么地方了 (offeset),以免 rebalance 或重启后,不知道该从什么地方开始消费。
最早 kafka 是依赖 zookerper 保存,由于其写性能差,现在 kafka 创建了一个内部的 Topic 来保存 Group 针对 Partition 的消费位移记录,这算是某种意义上的“自举”了。(__consumer_offsets)
Consumer 可以通过在处理完消息后,向 kafka 提交自己处理的 offeset,由 kafka 帮忙保存这个值,需要时从 kafka 读取即可.kafka 只提供保存能力,行为由 Consumer 自行负责。
对应消费者 Group 的 Coodinator,就是通过这个 Topic 来决定的,其 Partition 分布到 kafka 的众多 Broker 上。通过:partitionId=Math.abs(groupId.hashCode() % offsetsTopicPartitionCount) 算出一个 PartitionId,位移数据就提交给这个 Partition,这个 Partition 的 Leader 副本所在 Broker 即为对应的 Coodinator。
消费者的坑
除了上面提到的一直重平衡导致消费行为停滞,消费过程中还有一个典型的巨坑:
- Consumer 拉到一批消息
- 假设 offset 为 A 的处理失败,offset 为 B 的处理成功。B > A
- A 消息未提交位移,B 消息提交了位移
- 此时发生重平衡,消费者拉到最新消费位移为 B,从 B 开始消费
- A 消息不能被重新消费到,导致 A 消息未被成功处理 (不重平衡也会这样)
这是一个蛋疼的点,要避开上面的问题,需要顺序处理消息,如果处理失败不能直接跳过,否则 offset 较大的消息处理成功并提交后,失败消息可能就丢失了,但这会严重拖慢消费速度。
所以一般消费者程序要根据实际场景,考虑是否增加失败队列来应对这种情况。