Ruby 更快的 Rails:如何检查记录是否存在, 你是否还在使用.present?
Ruby 和 Rails 很慢 - 这个论点通常被用来淡化语言和框架的价值。这种说法本身并不是假的。一般来说,Ruby 比其直接竞争对手如 Node.js 和 Python 慢。然而,从小型创业公司到拥有数百万用户的平台的许多企业都将其作为其运营的支柱。我们怎样才能解释这些矛盾呢?
是什么让你的程序变慢?
虽然使应用程序变慢的原因可能有很多,但数据库查询通常在应用程序的性能足迹中起着最大的作用。将过多的数据加载到内存中,N + 1 查询,缺少缓存值以及缺少正确的数据库索引是导致请求缓慢的最大罪魁祸首。
有一些解释是 Ruby 太慢了。但是,我们的应用程序中的大多数缓慢响应通常归结为未经优化的数据库调用和缺乏适当的缓存。
即使您的应用程序今天速度非常快,但仅仅几个月它就会变得更慢。工作正常的 API 调用可能会突然开始使用可怕的 HTTP 502 响应来终止服务。毕竟,使用具有数百条记录的数据库表与使用具有数百万条记录的表非常不同。
Rails 中的存在性检查
存在性检查可能是您发送到数据库的最常见的调用。应用程序中的每个请求处理程序都可能以查找开始,然后是在数据库中使用多个相关查找的策略检查。
但是,有多种方法可以检查 Rails 中是否存在数据库记录。present?, empty?, any?, exists?以及各种其他基于计数的方法,它们都有非常不同的性能影响。
一般来说,我总是喜欢使用.exists?。
我将使用我们的生产数据库来说明我更喜欢的原因.exists?替代方案。我们将尝试查看过去 7 天是否已通过构建。
让我们观察一下我们的调用产生的数据库调用。
Build.where(:created_at => 7.days.ago..1.day.ago).passed.present?
# SELECT "builds".* FROM "builds" WHERE ("builds"."created_at" BETWEEN
# '2017-02-22 21:22:27.133402' AND '2017-02-28 21:22:27.133529') AND
# "builds"."result" = $1 [["result", "passed"]]
Build.where(:created_at => 7.days.ago..1.day.ago).passed.any?
# SELECT COUNT(*) FROM "builds" WHERE ("builds"."created_at" BETWEEN
# '2017-02-22 21:22:16.885942' AND '2017-02-28 21:22:16.886077') AND
# "builds"."result" = $1 [["result", "passed"]]
Build.where(:created_at => 7.days.ago..1.day.ago).passed.empty?
# SELECT COUNT(*) FROM "builds" WHERE ("builds"."created_at" BETWEEN
# '2017-02-22 21:22:16.885942' AND '2017-02-28 21:22:16.886077') AND
# "builds"."result" = $1 [["result", "passed"]]
Build.where(:created_at => 7.days.ago..1.day.ago).passed.exists?
# SELECT 1 AS one FROM "builds" WHERE ("builds"."created_at" BETWEEN
# '2017-02-22 21:23:04.066301' AND '2017-02-28 21:23:04.066443') AND
# "builds"."result" = $1 LIMIT 1 [["result", "passed"]]
第一个使用.present?是非常低效的。它将数据库中的所有记录加载到内存中,构造 Active Record 对象,然后查明数组是否为空。在庞大的数据库表中,这可能会造成严重破坏并可能加载数百万条记录,甚至可能导致服务停机。
第二种和第三种方法,any? 和 empty?,在 Rails 中进行了优化,只将 COUNT()加载到内存中。COUNT()查询通常是高效的,您甚至可以在半大型表上使用它们而不会产生任何危险的副作用。
第三种方法,exists?,甚至更优化,在检查记录的存在时它应该是你的第一选择。它使用 SELECT 1 ... LIMIT 1 方法,非常快。
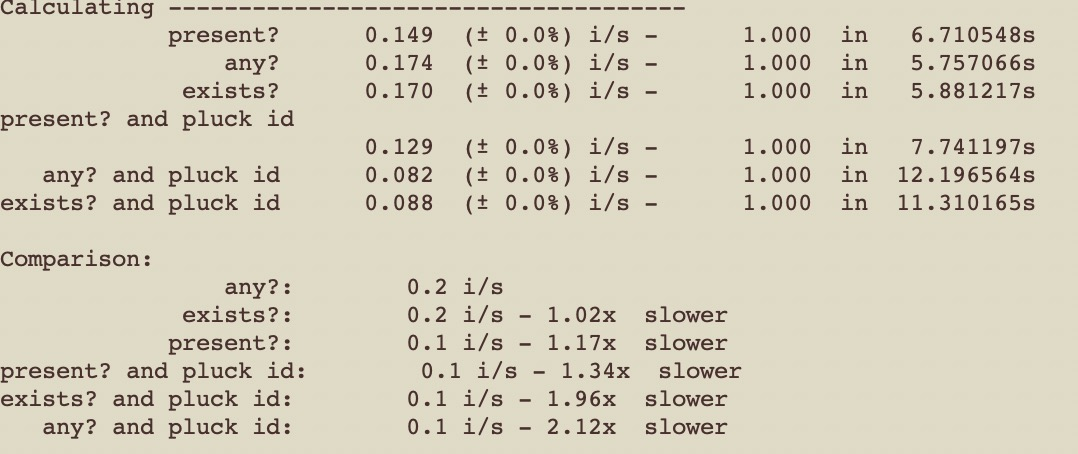
以下是我们的生产数据库中针对上述查询的一些数字:
present? => 2892.7 ms
any? => 400.9 ms
empty? => 403.9 ms
exists => 1.1 ms
这种小调整可以使您的代码在某些情况下的速度提高 400 倍。
如果你考虑到 200 毫秒被认为是可接受的响应时间的上限,你会发现这个调整可以解释良好,缓慢和糟糕的用户体验之间的差异。
我应该一直使用 exists? 吗?
我认为 exists?一个良好的理智默认值,通常具有最佳的性能足迹。但是,也有一些例外。
例如,如果我们检查是否存在没有任何范围 (scope) 的关联记录,any? empty? 还将生成一个使用 SELECT 1 FROM ... LIMIT 1 的非常优化的查询,但是 any? 如果记录已加载到内存中,则填充不会再次命中数据库。
当记录已经加载到内存中时,这使得整个数据库调用的 any?更快:
project = Project.find_by_name("semaphore")
project.builds.load # eager loads all the builds into the association cache
project.builds.any? # no database hit
project.builds.exists? # hits the database
# if we bust the association cache
project.builds(true).any? # hits the database
project.builds(true).exists? # hits the database
作为结论,我的一般建议是始终使用 exists? 并根据指标改进代码。
原文:- 更快的 Rails:如何检查记录是否存在