部署 Unicorn 与 Puma 的区别,nginx 与哪个搭配使用更好?
unicorn 与 puma 的区别,nginx 与哪个搭配使用更好?
现在流行 Puma 了,Puma 首先是 Rails 5 的默认 web 容器,其次如果你使用 ActionCable 或类似的 websocket 后端的话,Puma 不需要你单独再启动额外服务来运行了。
至于和 Nginx 搭配,两个在 Nginx 的配置方式是完全相同的
puma 在 MRI 上体现的优势并不明显,ActionCabel/Websocket 的直接支持倒是它的特性优势。在我们自己的应用上对比了 puma 和 unicorn,并发能力差别不是很大。
其并发优势需要在真正多线程环境上 (JRuby Rubinius) 上才能体现出来。
题外话:JRuby 作为 ruby 与 java 的胶水也是个不错的方式。我也很好奇有多少人在生产环境上使用 Rubinius.
在好网络并发看起来并无差别,如果网站移动终端用户多,差别就大了。
比如某些移动用户网络不稳定导致一个请求要 5 秒在请求完成。 在 unicorn 的 2 进程下,5 秒内只能两个并发(unicorn 一个进程同一只能处理一个请求)。而 2 进程 32 线程的 puma,却可以处理 64 个并发(puma 一个线程处理一个请求)。
unicorn 跑 MRI,puma 跑 JVM,因为前者多进程,后者是多线程(我看了源码,是客户端 waiting full 的 Thread_pool),多线程在 MRI 有 GIL,相当于没并行,加上 IO 会堵塞(除了 IO 会释放),所以(基本)是串行的,那样环境下的 PUMA 等于(不亚于)单进程单线程。
楼上说的代码线程安全,加锁就好,另外,多进程有缺陷:互相之间超难通信,过程复杂,而且传输的东西有时候不全(用 pipe + marshal)
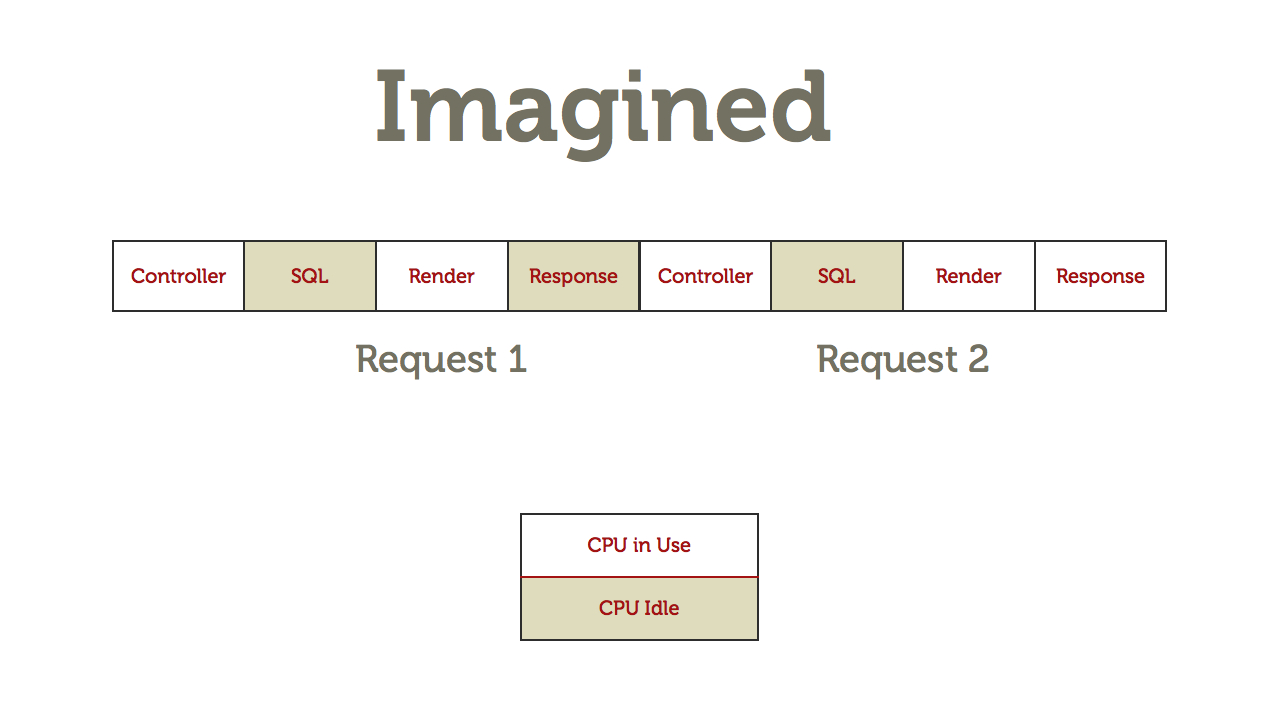
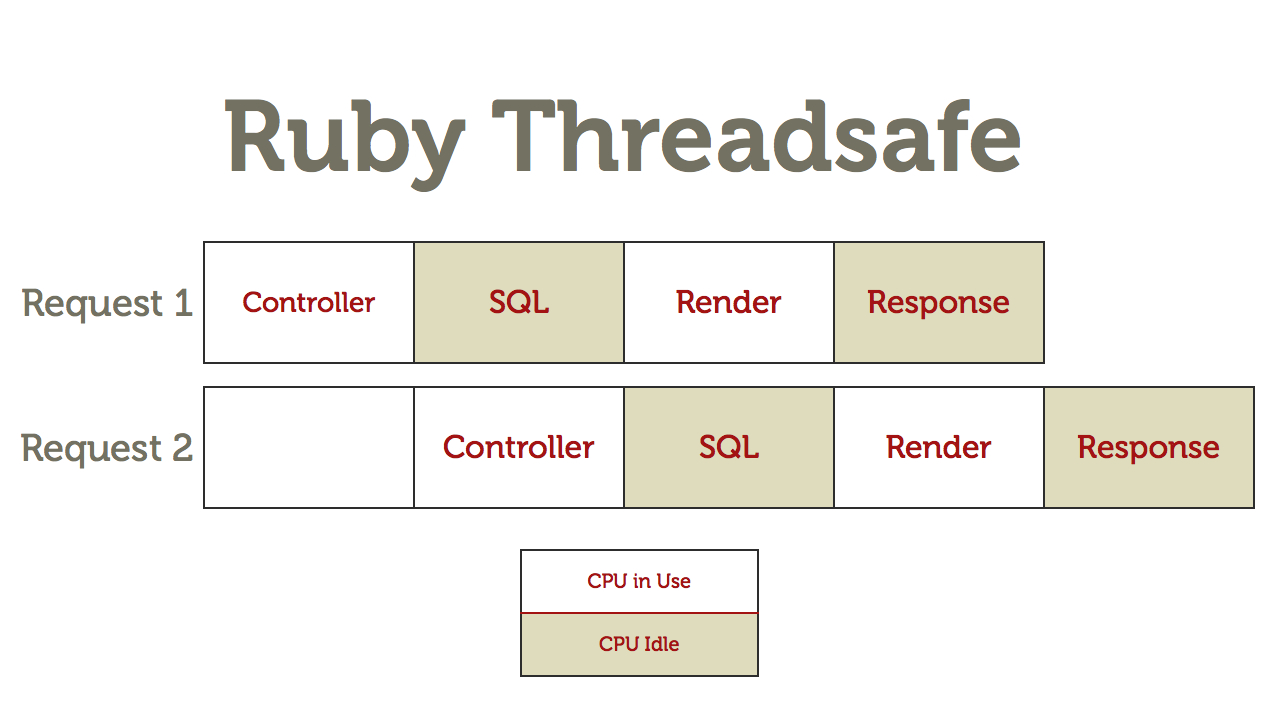
请求处理时间长的,即便通过线程方式,同一时间能接入更多请求,但也只能是接入,并不意味着能并发在处理这些请求,其结果是,请求接入数增加,请求处理的等待时间也在增加,超时数也在增加。
再次回复:
终于抽时间写了个 test
require "benchmark"
result = Benchmark.measure("normal") do
100.times do
f = File.open("/Users/***/Downloads/***.dmg", "r")
s = f.read
f.close
# p "finish #{s.length}"
end
end
p result
result = Benchmark.measure("concurrent") do
threads = []
100.times do
t = Thread.new do
f = File.open("/Users/***/Downloads/***.dmg", "r")
# p f
s = f.read
f.close
# p "finish #{s.length}"
end
threads << t
end
threads.each do |t|
t.join
end
end
p result
while true
end
运行结果:
#<Benchmark::Tms:0x007fecde927d90 @label="normal", @real=0.2543760000007751, @cstime=0.0, @cutime=0.0, @stime=0.24, @utime=0.010000000000000002, @total=0.25>
#<Benchmark::Tms:0x007fecde917648 @label="concurrent", @real=0.1437469999982568, @cstime=0.0, @cutime=0.0, @stime=0.31000000000000005, @utime=0.020000000000000004, @total=0.33000000000000007>
证实以下结论:
IO 是不堵塞的
没什么太大的好处,但也并不是完全没有用,刚比较了一下,小并发,还是比较快的,但是数据量一大就不行了(因为 Ruby 都是把数据不管二进制还是字符流存在 String,数据大了很卡)。。。
另外,IO 密集的程序应该是做日志系统吧。。。但是日志系统一般都有逻辑,而不会直接就执行一行 read 和 write,所以还是没有优势。
不过如果是简单的日志系统,单线程的,那还是比较有价值的。
适用场景:个人博客(基本不涉及计算,而且偏向静态所以多数都是 IO 操作)、展示型网站、bug 追踪系统、工作流系统。
GIL 让密集计算串行起来其实让开发者更安心用多线程,其实“并行”还是有的,只是模拟(通过给定每个 Thread 执行时间作业),对于非高需求的开发者,实际上这样可以降低开发难度(满足简单软件开发)。所以也是满足了这门语言适合对 CS(Computer Science)不 Geek 的人群使用。
另外,一开始是我用 C 多线程来改写了 amber-kit 项目部分的代码,后来发现把 Ruby 的 VM 弄死了(回去再补图)。所以才在 5 楼回复了一下,结果被楼上楼下的各种误会(其实没有人知道我做了什么)。
在 C 多线程 pthread 下,MRI 或无法回收 pthread 里面执行的堆栈的 VALUE,混编需要注意这点。
然后跑了 1000 个并发(其实没到 1000,大概在 200 - 400 左右)就挂了,然后报错 segment fault,一堆 ruby gc 相关的错误 trace 就出现了。
其实我只是想绕开 GIL,但是还是失败了
因为 Ruby 都是把数据不管二进制还是字符流存在 String,数据大了很卡
没有任何因果关系....
MRI 或无法回收 pthread 里面执行的堆栈的 VALUE
可以的,你 segment fault 的原因可能是没有把 thread 注册进去 Ruby VM, 导致 GC mark 不到各个 thread 的 stack, mark 不到就会回收掉。不是无法回收而是过早回收了...
如何让 GC 知道所有 thread 呢?
VM 对所有在 Ruby 中创建的线程有跟踪,rb_vm_t 有个列表字段叫 living_threads, 其中的每个元素的类型是 rb_thread_t.
rb_thread_t 结构体有个 machine 字段,它里面有 stack_start/stack_end/register_stack_start/register_stack_end 字段。
所以在 GC 的时候 living_threads 的所有 stack 的 VALUE 都可以 mark 到。
简单的办法就是:你直接用 Ruby 的 thread API 去创建线程就好了。如果你还是坚持自己用 pthread 或者 win_thread 去创建,你可以把创建后的 thread 包装成 Ruby thread 然后注册到 GC 的 root set 中去。
@jakit 你说的多线程编程问题在所有 GC 里都有,如果你在 GC 体系外自己创建了新线程,而新线程里带有待 GC 对象,你就得向 GC 注册你自己创建的线程。例如 Boehm GC 就得调用:
GC_register_my_thread / GC_unregister_my_thread 去处理
Geek 人群是可以关闭 GVL 的 -- 首先你得知道你在干啥,会不会有影响。对应的 API 是 rb_thread_call_without_gvl
谢谢,我看这些在很多网站都找不到资源,也不知道怎么解决,不过你倒是帮我解决了这个问题,再次谢谢~
其实当时我已经意识到没有 mark 那个变量,然后尝试各种手动删除,但是翻了半天没找到方案。