前言
上次在 40 天的时候介绍了一些人生的经验,做了些微小的贡献。一个人的命运啊,当然要靠自我奋斗,但是也要考虑到历史的进程,我绝对不知道我刚写了能跑 Hello World 的程序怎么把我选到 GitHub Trending 去了。这之后就莫名其妙上了 Ruby Weekly,还被 Matsumoto 桑给 retweet 了。然而上次那篇文章用的是中文写的,这直接导致一些不明真相的外国友人进行了迷之看空的讨论。
不过在之后 60 天里,这个项目的 API 逐渐完善,对于原先很多的问题逐渐都在修正。我已经开始使用 midori 开发逻辑复杂的业务的尝试,并且目前进展非常顺利。在这 100 天之际,将 midori 的设计思路更好得整理一下,来仔细说说 midori 在解决什么问题,以及怎么解决。
异步的思考
瘾君子 JavaScript
JavaScript 不是所有语言中最早做异步的,但却是近年来非常引人瞩目的一个。这是因为,在并不十分快的 V8 虚拟机上,JavaScript 在主流解释型动态类型语言网络后端对比中,达到了不俗的性能表现。一般认为这是由 Node 纯异步设计带来的性能优势,然而事实上真的如此吗?
随手拿一段 Node 的代码,比如 http-parser 的 JavaScript 示例代码:
connection.addListener("headers_complete", function (info) {
incoming.httpVersion = info.httpVersion;
if (info.method) {
// server only
incoming.method = info.method;
incoming.uri = node.http.parseUri(incoming.uri); // TODO parse the URI lazily?
} else {
// client only
incoming.statusCode = info.statusCode;
}
stream.emit("incoming", [incoming, info.should_keep_alive]);
});
connection.addListener("body", function (chunk) {
incoming.emit("body", [chunk]);
});
connection.addListener("message_complete", function () {
incoming.emit("complete");
});
通过三个 Listener 来完成的 http parse 工作显然是异步的,画成流程应该是这样的:

然而事实上这整个异步都是假的,是特技的魔法。因为它的执行只有一种可能:
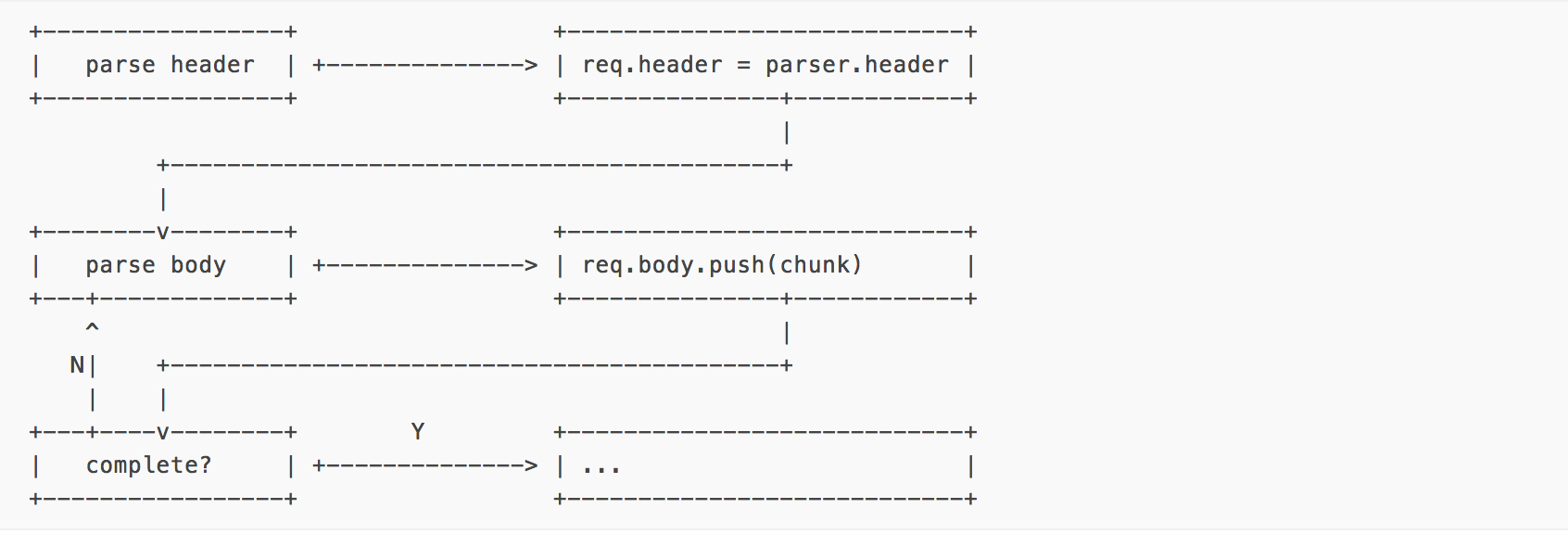
如果你觉得这图有点晕,不如我们换个方向来看这个图
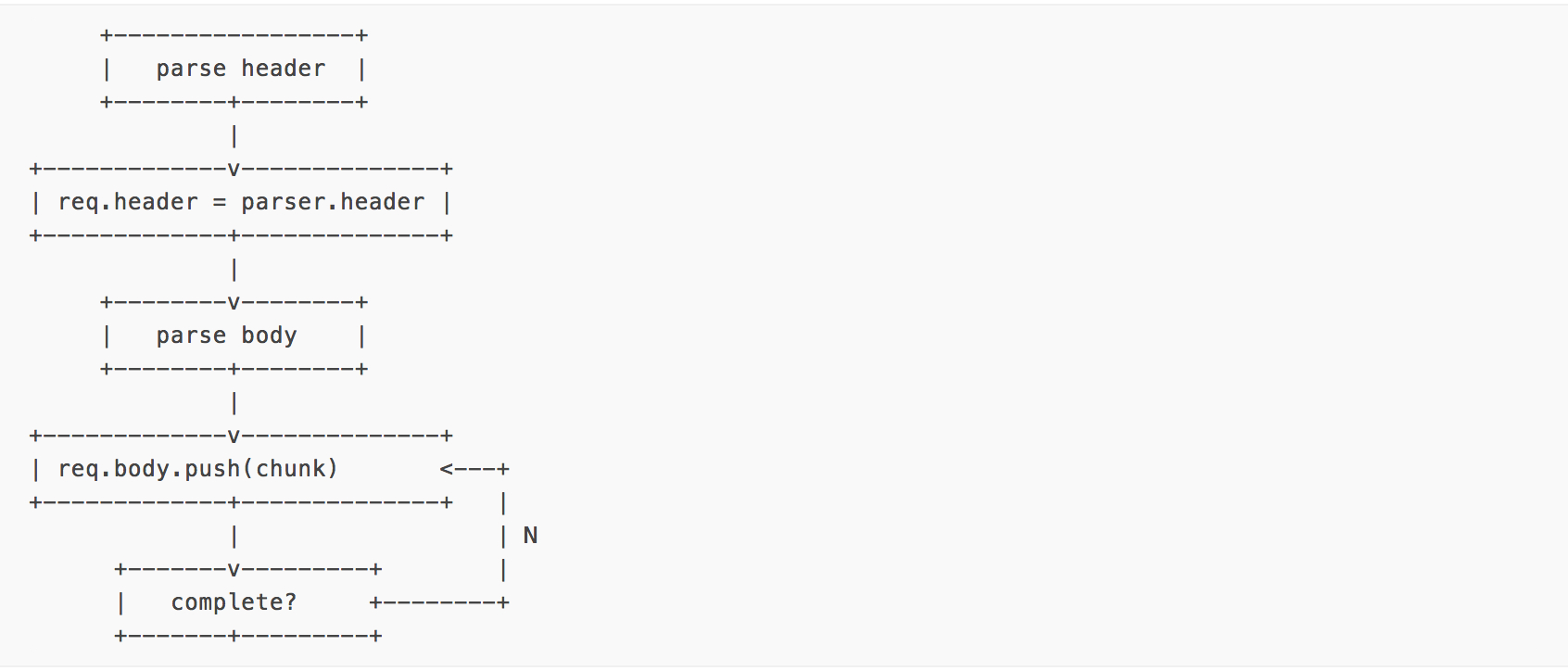
这就算现在找个没怎么学过编程的学生来,也看得出这东西就是个依次运行的同步流程了吧。因为这几步之间是有关系的。如果 header 没处理完,你连 body 在哪都还没找到,怎么可能能异步呢?Node 的许多地方都是 语义异步,运行同步 的。之所以要这么做很大程度上是为了贯彻 Node 纯异步的本身,希望编程者把思路完全变成异步的思路。如果说想上面这个例子中,同步和异步并不存在运行上的差异,那么影响运行效率的到底是什么呢?
说到底是 阻塞 在作怪。
如果一个核心一个线程一次只能正在处理一个队列的任务,每个任务耗时需要 1s 完成:

那么这个任务必然需要 5s 才能完成,无论这其中这几个任务如何排列顺序。异步在这种情况下不会带来任何性能上的好处。真正的好处出现在下面的图里:

1 号任务处理了一半休眠了 1 秒,不处理任何东西,只是白白贡献了自己的 1 秒。如果我们的程序时异步的。那么 1 号任务可以让出处理权,先让 2 3 4 处理。而这种情况除非是有意的 sleep 操作,通常都是由于 I/O 阻塞 造成的,也就是处理了一半,正在等待一个网络请求或文件读写完成才能继续处理的这种情况。所以 Node 与其说是异步,不如说是由异步产生了一个无阻塞的网络框架产生的性能提升。
回调地狱
那么说清楚了上面这个问题,我们就来说说,我们都不想这么写的原因:回调地狱 (callback hell)。如果我们在网上搜索一下,我想可以看到无数有关的段子。

然而事实上,在 Node 自己的样例中我们很少看到这种糟糕的代码,这种代码更多的是出现在我们的业务中。因为业务的实现主要就是 CRUD,而这些操作的明显特点就是每个业务都存在其自己内在的逻辑关系,有其自己的执行顺序,即使抽象也很难复用。而业务 API 通常都有着及时的反馈,这使得我们一定是:
- 读入请求
- 解析请求
- 操作数据库
- 返回结果
这四个操作的顺序不能颠倒的,但问题在于读入请求、操作数据库、返回结果都涉及 I/O 操作,确实将这几步通过回调异步可以有效避免阻塞提高性能。如果你的数据库操作复杂,涉及多次数据库操作,那么这个回调地狱自然而然就产生了。伪代码如下:
connection.on('received', function(data){
DB.query('SELECT * FROM A WHERE x=' + data['test'], function(result){
DB.query('SELECT * FROM B WHERE x' + data['test2'], function(result2){
connection.response(result + result2, function(err){
// Response failed
})
}, function(err){
// DB query failed at query 2
}))
}, function(err){
// DB query failed at query 1
})
})
显然,这种混乱的代码是 Node 工程师的日常。但是,回调地狱真的是不可避免的吗?事实上,暴露在业务中的 I/O 大多是有逻辑关联的,一旦有回调,就会回调地狱。但只要我们能把 CPU idle 率降到 0,避免掉所有的阻塞,我们的目的就已经达成,回调并不是异步必须要有的。
为了更好地解决问题,我们现在不妨忽略所有的细节,忘记业务本身,就看看回调地狱的形状长得像啥?
(
(
(
()
)
)
)
这种括号组成的语法关系是不是让人有一种:
(on connection 'received (lambda (data)
(query DB (format nil "SELECT * FROM A WHERE x=~A" (data 'test)) (lambda (result)
(query DB (format nil "SELECT * FROM B WHERE x=~A" (data 'test2)) (lambda (result2)
(response connection (+ result result2))
) (lambda (err2) ())
)) (lambda (err) ())
)))
的错觉。这个错觉并没有错,JavaScript 可以说就是披着 C 语言外衣的 Lisp。它除了长得像 C 语法以外都和 Lisp 比较像。那么 Lisp 的括号嵌套是什么关系?本质上是栈的关系。所以一系列的回调本质是栈吗?稍有一些区别。回调被调用之时就是入栈之时,然而回调执行完并不是出栈之时,因为栈底的东西已经被执行完了。但如果我们更近一步,假设栈底什么都没有的话,那么我们就已经找到了一种非常基础的数据结构来描述这一行为的本质,这东西更像是一个 队列,每次回调只是在告诉队列,你可以处理下一项了。
也就是说,每个请求的处理都是一个队列,每个 I/O 操作都是队列中的一项,当这个队列被运行完了,这个请求就被处理完了。它和原先同步的代码比起来的唯一区别是,同步代码可以被认为这个队列是依次接连执行的,而现在队列中的每一项只在它可以执行的时候再执行,否则,我可以去执行其他队列里的东西,把 CPU 的 Idle 吃完,就能达到很好的性能。
已有的尝试
事实上在比如 Thin 或者 Puma 之类的 Web 服务器中都已经使用 EventMachine 实现了一部分的异步,也就是将网络的 I/O,读取请求和写回返回部分写了非阻塞的写法。所以如果你跑一个 Hello World 服务器,那么其实性能并不太差。
比如最简单的 sinatra 例子
require 'sinatra'
get '/' do
'Hello World'
end
如果用 Thin 来跑的话,一个核心大概有 2500+ req/s 的性能,如果再拿掉一些中间件,还能更快。即使和 Node 有一些差距,但是这种差距是线性的,并不是什么显著的问题。
只不过阻塞问题有个巨大的特点,那就是一处阻塞,处处阻塞。Ruby 中常用的数据库连接、文件 IO 都是一些阻塞模型。一旦涉及数据库,Sinatra on Thin 的性能就会显著下滑。本质上来说,这件事情毫无道理,因为数据库的运算和 Web 框架无关,之和数据库程序有关。但由于 Web 程序一直在等待数据库返回而不去处理手上的事物了,这才导致了性能上的下滑。
要想彻底解决阻塞的问题,要把每一个 I/O 操作都变成非阻塞的才行。
小绿的异步
em-midori 与其说是一个异步的 Web 框架,不如说是提供了一系列无回调非阻塞 I/O 的工具集合。em-midori 利用 Fiber 存储当前作用域和让步/恢复的特性来处理刚刚我们所说的 队列 的特征。每个 I/O 操作都会被看作队列的一项,一旦被执行,它就会保存自己当前作用域下变量,然后让出自己的处理权让系统处理其它任务,而等 I/O 完毕后再恢复这个代码的继续运行。比如:
require 'em-midori'
require 'json'
require 'em-midori/extension/file'
class Route < Midori::API
get '/' do
file = Midori::File.read('./hello.txt')
{text: file}.to_json
end
end
Midori::Runner.new(Route).start
当请求进来后,运行到
Midori::File.read('./hello.txt')
这里时,程序就会让出自己的处理权,直到文件读取完,它会继续完成赋值
file = ...
然后把整个 API 的接下来内容跑完。在业务代码中不会出现一行回调,但已经完成了所有的非阻塞的封装。
API 设计
为什么不 await?
事实上,虽然出发点不同,但是从语义上看,这和 C# 中 await 的语义是非常接近的。意识到问题的 ECMAScript 7 标准中,也加入了类似的 await 语义。我非常支持 await 语义,并且 em-midori 内也提供了 await 语法的封装,但是我并不打算将其作为一个可以直接使用的 API 来看,而是各个驱动程序封装的工具。
因为当我们在使用 Web 框架 而不是在 造轮子 的时候,我们更关心的其实是业务。而一个业务处理的逻辑本身就是耦合的,是最小不可分的。使用 await 应该是默认的,而不是需要手动加入的。否则充斥 await 的语法并不是一个 Web DSL 该有的东西。
异常处理
上述设计在实现时有个非常 tricky 的一点,就是异常处理。由于启动 Fiber 来处理异步的程序,在里面抛出的异常无法被外面的 begin end 语法捕获。而这一语法又恰恰只实现了程序的正确回调,却没有实现异常回调。为了弥补这一问题,em-midori 会自动捕获 Fiber 代码块中的一切异常,并遇到后在异常回调中抛出。开发者就可以正常使用 begin end 语法来捕获异常了。
同时,em-midori 还支持通过 capture 语法来定义全局错误处理,以更好处理一些常规错误例如 404, 500 等的通用处理返回。形如:
require 'em-midori'
require 'json'
require 'em-midori/extension/file'
class Route < Midori::API
get '/' do
begin
file = Midori::File.read('./hello.txt')
{text: file}.to_json
rescue Errno::ENOENT => _e
Midori::Response(404,
{},
{err: 'File not found'}.to_json)
rescue => e
Midori::Response(500,
{},
{err: 'Internal Server Error', detail: e.traceback}.to_json)
end
end
end
Midori::Runner.new(Route).start
或者
require 'em-midori'
require 'json'
require 'em-midori/extension/file'
class Route < Midori::API
capture StandardError do |e|
Midori::Response(500,
{},
{err: 'Internal Server Error', detail: e.traceback}.to_json)
end
capture Errno::ENOENT do
Midori::Response(404,
{},
{err: 'File not found'}.to_json)
end
get '/' do
file = Midori::File.read('./hello.txt')
{text: file}.to_json
end
end
Midori::Runner.new(Route).start
路由挂载
em-midori 被设计成一个面向实际 Web 业务开发的框架,自然不是一个简单的轮子游戏,它为工程化的抽象做了不少考虑。比如支持 mount 来将一整个路由定义挂载到主路由上。
语法:
class A < Midori::API
get '/' do
'Hello'
end
end
class B < Midori::API
get '/' do
'World'
end
mount '/a', A
end
Midori::Runner.new(B).start
# / => 'World'
# /a/ => 'Hello'
事实上,这个路由挂载并不是一个栈递归调用,而是在初始化时通过一个深度优先搜索算法遍历,建立出整个中间件调用链。尽可能减少运行时的性能消耗,是个非常实用的设计。
现有进度和未来路线
em-midori 现在已经是一个勉强可用的状态。除了框架本身,简易的文件 I/O、Postgres 驱动、Sequel ORM 都已经被实现好。我已经开始着手使用这一框架用于生产,并已经有一些好的结果。并通过实际项目的建设也修复了不少不易察觉的 bug。
就目前的版本来说 em-midori 虽然较上次增加了很多功能,但性能和仍然能比 sinatra 快一倍以上,比 rails 5 api mode 快大约 6 倍。和 Node.js 上的 express 框架比较,性能不分上下,取决于具体运行机器。
不过,这个版本距离生产就绪的版本还有不少距离。从可用角度上来说,项目的测试覆盖率已达到 100%,但很多边缘情况都没有得到妥善的测试。在接下来的几个月需要更好的测试这一框架。
从学习角度来说,em-midori 还需要完善各方面的文档,补充 Tutorial 和 Guidelines 才能被其他人使用。并不可能让大家边读源代码边写业务。
在样例上,我选择了论坛项目作为一个官方 example,项目将作为 Tutorial 的一部分,给大家演示实际使用框架用于业务开发的各种细节。这些内容也会在 v1.0 版本前就绪。
从功能上来说,em-midori 抛弃了 Rack 作为 Web 接口,很大程度是我希望在接下来版本中加入完整的 HTTP/2 支持。但这也导致了需要重复造很多轮子,比如 rack-test 之类的配套功能。
时间上,我希望生产版本能在明年 3 月前发布。考虑到目前路线图的进度,开发进度仍领先于设定好的时间,所以我还是有不少把我做好这件事的。
最后祝大家写 Ruby 都能写得开心,写得愉快!
Ruby is designed to make programmers happy.
–Yukihiro Matsumoto

项目地址:em-midori
