运维 Puppet Hacking Guide —— Puppet 的启动:子命令
“知己知彼,百战不殆。——《孙子·谋攻篇》”
在阿里巴巴实习期间,由于各种机缘巧合,我开始专注于研读配置自动化管理软件 Puppet。这项工作持续了两个月,期间我在内网发布过多篇技术文章,详细地剖析 Puppet 的运行原理。业已实习完毕,所有的技术文档、演示幻灯以及部分实例源码,均已通过阿里巴巴对外数据披露备案,被允许向开源社区分享这些技术文档。社区曾给了我很多帮助,我想,现在是时候我向社区尽一些绵薄之力了。
虽然没有把 Puppet 多达 10 万行的源码彻底地分析清楚,但大致的脉络已经理清。整个系列文集将会以《Puppet Hacking Guide》为总标题(致敬《Ruby Hacking Guide》),解释 Puppet 3.X 版本的内部运行原理,为用户定制 Puppet 提供指导。整个系列以我在阿里巴巴内部发表的文章为草稿,重新组织整理,以期能以一种清晰的思路引导读者理解 Puppet 源码。
尽管本文几经修改,但笔者才疏学浅,难免有所纰漏,欢迎各位指正!另外,出于职业道德,我不能向各位透露以下信息,也请各位不要打听,见谅:
- Puppet 在阿里巴巴内部的使用场景;
- 阿里巴巴所使用的 Puppet 具体版本号;
- 阿里巴巴所采用的 Puppet 体系架构;
另外,如果读者所在公司有定制 Puppet 的需求,可以联系我,我可以在研究需求后,给出一些可行的方案。
Acknowledgment
本系列文集是在我受雇于阿里巴巴期间撰写的一系列技术文档重新整理而成,其版权属于阿里巴巴公司以及我本人。经雇主同意,现特许以技术交流为目的,在开源技术社区分享此文集。
因此您可以:在保留原作者 DeathKing 以及阿里巴巴 - 技术保障部署名的情况下,以学习交流为目的,以非盈的形式将本文以电子版或印刷版的形式分发给您的朋友,或者转载到任何一个开源社区;
以下行为是禁止的:
- 以盈利为目的,将文章转载到微信公众号等媒体平台;
- 去掉原作者 DeathKing 以及阿里巴巴 - 技术保障部的署名,以自己的名义发布本文集;
请在转载时,保留以下署名:
- 本系列文章作者 DeathKing
- 阿里巴巴技术保障部

Puppet 的启动:子命令
Puppet 的启动方式
Puppet Agent 通常通过命令行触发,而 Puppet Master 即可以通过命令行方式触发,以 WEBrick 服务器模式运行,也可以通过设置 config.ru 文件,以 Rack 中间件的形式运行。
下面的命令可以让 Puppet Master 以 WEBrick 服务器的模式启动,选项 --no-daemonize 可以阻止 Master 的后台化,在测试的时候,我们通常添加一个 --debug 选项用以设置日志等级,让 Puppet 显示更多有用的信息方便系统管理员进行调试:
$ puppet master --no-daemonize --debug
下面的命令可以启动 Agent 使之与 Master 进行通信并完成一次完整的工作流。与默认的 Agent 与 Master 每 30 分钟同步一次不同,选项 --onetime 使得 Agent 与 Master 只进行一次同步,完成后立即退出。
$ puppet agent --no-daemonize --debug --onetime
要了解 Master 和 Agent 的启动过程,就需要先知道 Puppet 中子命令的概念,使用 puppet help 可以查看 Puppet 的使用帮助:
$ puppet help
Usage: puppet <subcommand> [options] <action> [options]
Available subcommands:
agent The puppet agent daemon
apply Apply Puppet manifests locally
ca Local Puppet Certificate Authority management.
# 有意省略了整个列表。
从使用帮助中,我们不难看出,跟在 puppet 命令后的参数被称作子命令(subcommand)。子命令通常对应了一个 Ruby 脚本文件或外部可执行文件。事实上,不单 agent 和 master 分别是一个 Puppet 子命令,连 help 也是 Puppet 的一个子命令,对应的是 lib/puppet/application/help.rb 文件。Puppet 将不同的功能模块抽象为子命令,并将这些子命令实现为不同的文件,这样实现和管理起来更为方便。
子命令分类
Puppet 子命令可以分为四类:
- 空子命令:调用 Puppet 时,如果没有指定任何子命令,Puppet 则认为调用的是空子命令;
-
应用子命令:存放在
puppet/application文件夹中的脚本所对应的命令。需要注意的是,这是一个相对路径,Puppet 会在多个路径中搜索该相对路径下的文件。这类子命令的典型的代表是agent、master和config等; -
外部子命令:存放在环境变量
PATH所指示的文件夹中、以puppet-开头的文件所对应的命令。例如,命令行调用puppet foo会使 Puppet 在环境变量PATH所指示的文件夹中搜寻名为puppet-foo的可执行文件; - 未知子命令:不是上述命令的其他子命令,Puppet 都将其视作未知子命令;
子命令的查找与加载
以命令行调用 Puppet 时,实际执行的是 bin\puppet 。作为整个系统的入口,这个文件却只有简单的几句代码:
- 文件:
bin\puppet
#!/usr/bin/env ruby
# For security reasons, ensure that '.' is not on the load path
# This is primarily for 1.8.7 since 1.9.2+ doesn't put '.' on the load path
$LOAD_PATH.delete '.'
require 'puppet/util/command_line'
Puppet::Util::CommandLine.new.execute
bin\puppet 主要实例化了一个 Puppet::Util::CommandLine 对象,这个对象主要用于理清 Puppet 的调用信息:调用的是哪个命令、有哪些命令行选项等。在后面的章节中我们会发现,如果以 Rack 中间件的方式启动 Puppet Master,会用到一些 trick,这也是 CommandLine 存在的原因。
CommandLine 对象实例化完毕后,execute 方法被执行。在这个方法中,最重要的是 find_subcommand.run 语句。
- 文件:
lib/puppet/util/command_line.rb
def execute
Puppet::Util.exit_on_fail("initialize global default settings") do
Puppet.initialize_settings(args)
end
setpriority(Puppet[:priority])
find_subcommand.run
end
CommandLine 类的私有方法 find_command 是理解整个启动机制的关键点,Puppet 在这个方法中,通过一些规则确定子命令的分类,然后再调用子命令对应的类,加载对应的文件。
- 文件:
lib/puppet/util/command_line.rb
private
def find_subcommand
if subcommand_name.nil?
NilSubcommand.new(self)
elsif Puppet::Application.available_application_names.include?(subcommand_name)
ApplicationSubcommand.new(subcommand_name, self)
elsif path_to_subcommand = external_subcommand
ExternalSubcommand.new(path_to_subcommand, self)
else
UnknownSubcommand.new(subcommand_name, self)
end
end
需要强调的是,Puppet 并不是根据命令的分类去查找文件,而是根据文件查找的结果,确定命令的分类,理解这一点很重要。在深入每句代码内部之前,我们应该对 find_subcommand 方法的模式有个大概认知:查找方法,然后实例化一个对应类的对象。比较令人疑惑的是,用于实例化的参数中有一个 self 。这里的 self 就是 CommandLine 对象,我们之前已经说过,CommandLine 对象已经理清了命令行调用的信息,因此我们可以在每个 Subcommand 对象中,通过 CommandLine 对象获得调用的命令行参数等信息。
Puppet 的命令分类我们已经在前面描述了,接下来,我们将详细地讨论查找的规则。由于空子命令和未知子命令的代码比较简单,我们先行介绍,接着我们将介绍外部子命令,我们最后再来分析最为复杂的内部子命令。
空命令与未知命令
将这两个命令放在一起讨论,是因为在某种程度上,这两者是一致的,以至于 UnknownSubcommand 是 NilSubcommand 的子类。前面已经说过,如果调用 Puppet
时,没有指明任何子命令,则实例化 NilSubcommand ,如果调用的子命令既不是内部子命令,又不是外部子命令,那么则实例化 UnknownSubcommand 。两者的区别在于——考虑到puppet --version 这样的输入也是合法的,NilCommand 通常要处理 -v 或 --version 选项,即显示版本号。
- 文件:
lib/puppet/util/command_line.rb
class NilSubcommand
include Puppet::Util::Colors
def initialize(command_line)
@command_line = command_line
end
def run
args = @command_line.args
if args.include? "--version" or args.include? "-V"
puts Puppet.version
elsif @command_line.subcommand_name.nil? && args.count > 0
# If the subcommand is truly nil and there is an arg, it's an option; print out the invalid option message
puts colorize(:hred, "Error: Could not parse application options: invalid option: #{args[0]}")
exit 1
else
puts "See 'puppet help' for help on available puppet subcommands"
end
end
end
# @api private
class UnknownSubcommand < NilSubcommand
def initialize(subcommand_name, command_line)
@subcommand_name = subcommand_name
super(command_line)
end
def run
puts colorize(:hred, "Error: Unknown Puppet subcommand '#{@subcommand_name}'")
super
exit 1
end
end
空对象模式
可能部分读者不太理解为什么要把空子命令和未知子命令抽象分别抽象为一个类,实际上,这里用到了一种称为“空对象模式(Null Object Pattern)”的设计模式。在大多数地方,这个模式的定义非常暧昧,根据在此处的使用场景,也许按照下面的方式理解空对象模式会更好一些:
空对象模式
将对缺失对象的错误处理,封装在一个用于表征缺失对象的类的一个方法中。
你也许无法立马理解这个拗口的定义,让我们回过头来审视 find_command 方法:
def find_subcommand
if subcommand_name.nil?
NilSubcommand.new(self)
# 有意省略了部分代码
else
UnknownSubcommand.new(subcommand_name, self)
end
end
想一想,我们能不能把空子命令、未知子命令的处理逻辑放在 if 子句、else 子句中呢?更进一步地,我们考虑 find_subcommand 方法的调用者,find_subcommand.run ,我们是否可以写成这样的形式呢:
if subcommand = find_subcommand
subcommand.run
else
# logic for object not found
end
当然,从语法角度上来说,这些都是可以的!但请思考,这样做真的合适么?这样做真的是“面向对象设计”么?答案是否定的。请看下面的调用关系,并仔细思考:
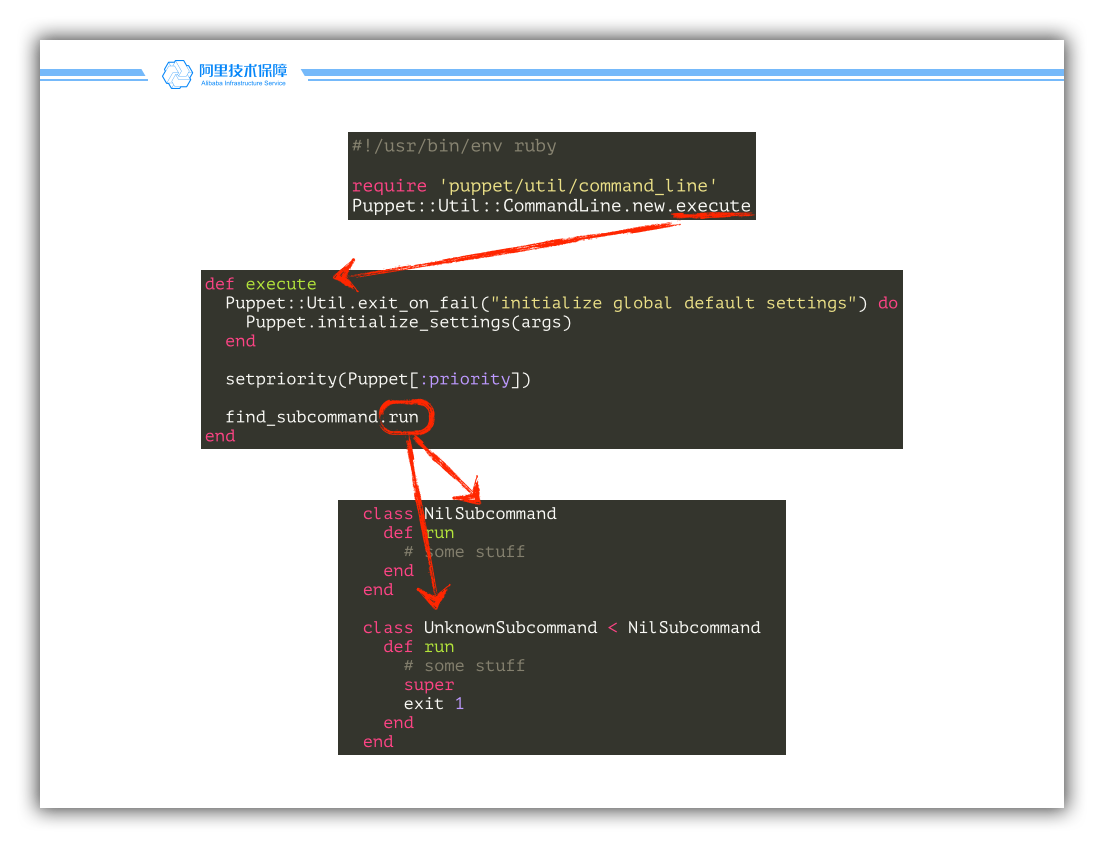
我们观察到:find_subcommand 方法的语义是查找一个特定的命令,这个命令要能够响应 run 方法。这样,当我们没有找到合适的子命令时,与其返回特殊值 nil 用于表征“对象没找到”,不如返回一个“空对象”表示“嗨,我找到了这么一个对象,但这个对象是‘空的’”。虽然后者看起来是绕了一个圈子,但两者的重要区别在于:“空对象可以响应 run 方法!因而,我们可以将错误处理的逻辑放在 run 方法中。”
下面这幅图演示了处理逻辑位置的变化,我们发现,处理逻辑被移动到了方法的内部。
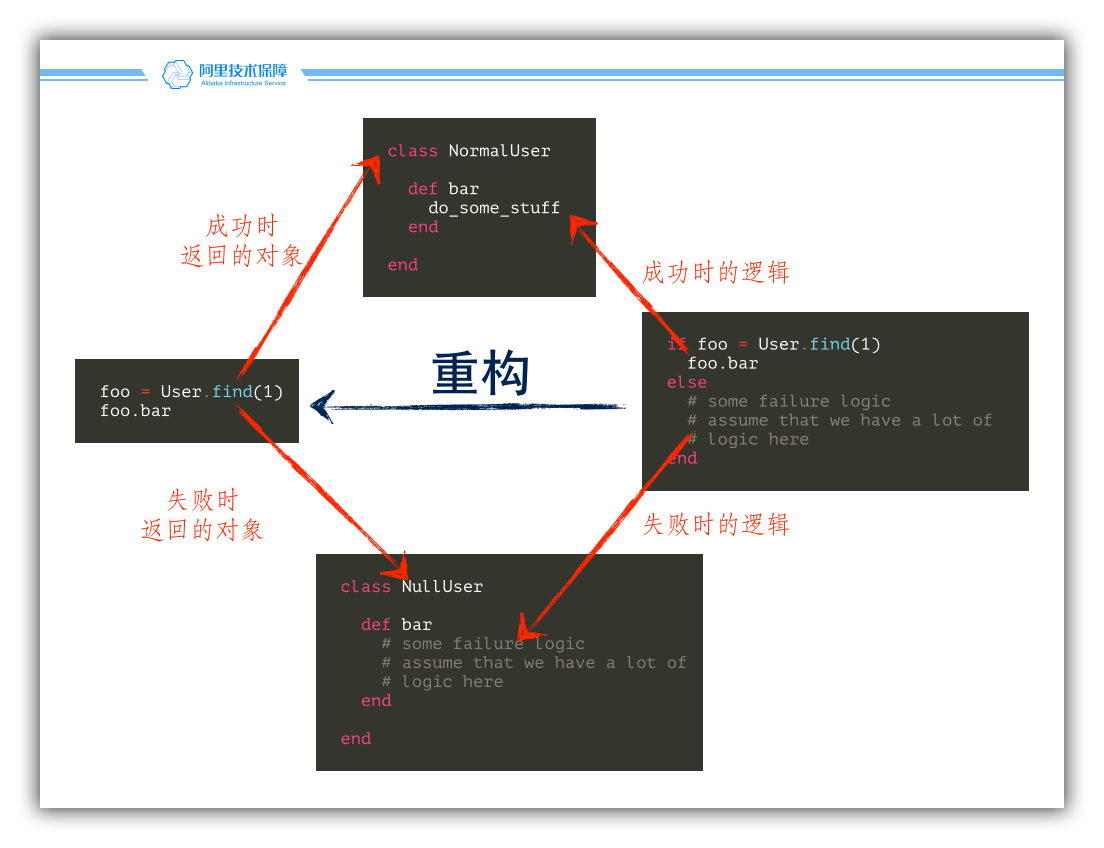
空对象模式有什么好处呢?除了绕了一个圈子,我们似乎看不到任何一点好处。实际上,如果你只有一段这样的代码,是否使用了空对象模式都并没有太大的关系,但请考虑这段代码在系统的各个地方重复出现时的情景:
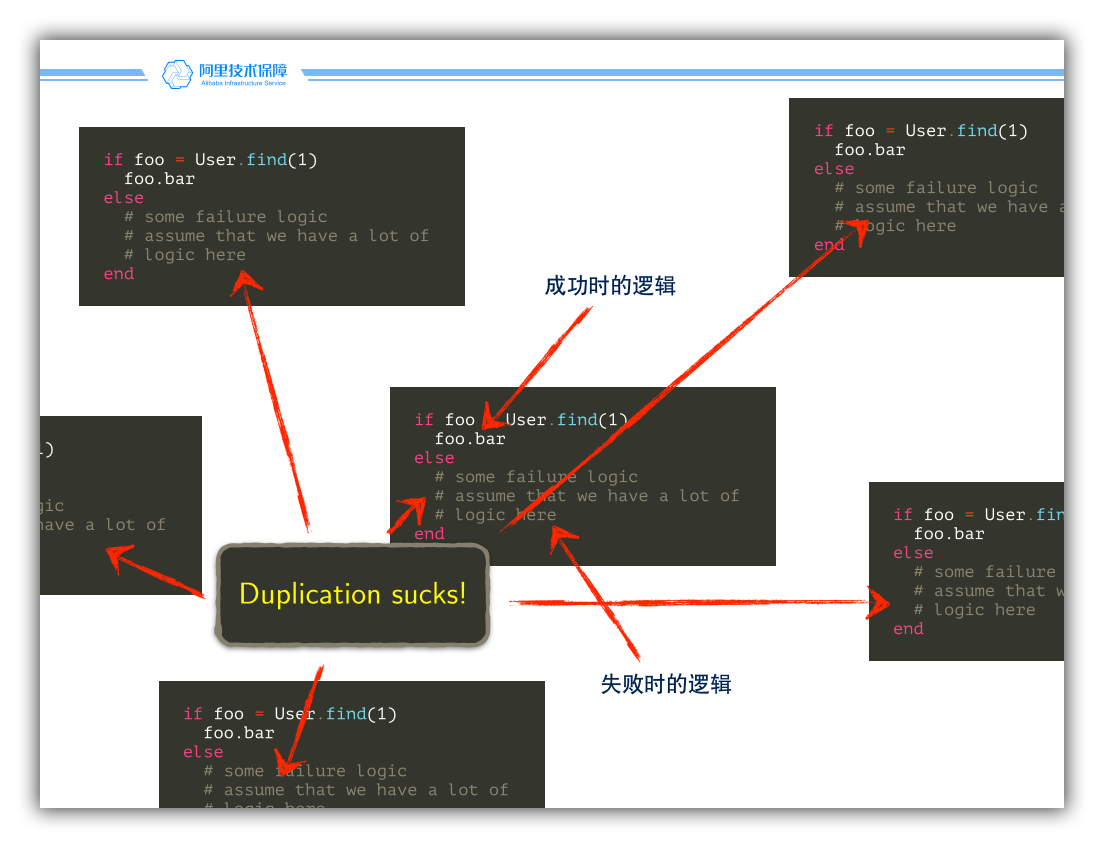
重复(Duplication)是一件非常危险的事,这种违背 DRY 原则的做法,很容易导致系统的不一致性。如果我们要修改失败时的逻辑,那么我们又需要在系统各个地方复制 - 粘贴大量的代码,我们能保证所有的出现都被有效地更新了吗?而考虑使用空对象模式的情景,缺失处理的代码被移动到了一个方法中,这样使得处理逻辑只有一份副本,对方法所做的修改,可以一致地应用到系统全局。
空对象模式的优势与劣势
设计模式只是一种工具,并不是最终目的,我们不能为了用设计模式而用设计模式。严肃的工程师需要仔细分析这些工具的适用场景。对于空对象模式来说,它的优势在于:
- 由于将逻辑封装在了一个方法中,由外部调用该方法,实践了 DRY 原则,极大程度上提高了代码的复用性;
- 通过合理地拆分,降低了系统耦合度,使得业务逻辑更加清晰;
- 由于可以在空对象的类中统一修改方法定义,避免了因为代码冗余而产生的不一致行为;
当然,空对象模式依然存在一些劣势:
- 不适合用在上下文高度相关的场景,因为此时我们很难对系统进行合理地拆分解耦;
- 可能会产生各种类型的空对象类,因此维护任务并没有消失,只是转移到对各个空对象类的维护上去了;
程序员在设计软件时,应该仔细取舍,合理地使用这些模式!
后话
理解空对象模式了么?它只是一种教条主义的繁文缛节么?如果我的解释并没有让读者信服,那么不妨聆听 Sandi Metz 在 RailsConf 2015 上的演讲 Nothing is Something ,这一定会再次震撼你的!
外部子命令
查找规则
外部子命令的查找由 external_subcommand 方法实现,如果指定的外部子命令存在(我们说过,外部子命令是一个可执行文件),则返回该可执行文件的路径。
- 文件:
lib/puppet/util/command_line.rb
private
def find_subcommand
# 有意省略了部分代码
elsif path_to_subcommand = external_subcommand
ExternalSubcommand.new(path_to_subcommand, self)
# 有意省略了部分代码
end
Puppet 会以 puppet-<subcommand> 作为文件名,在 PATH 环境变量中的指定的路径下进行查找。例如,当我们在命令行调用 puppet foo 启动 Puppet 时,Puppet 会尝试在 PATH 所对应的路径中,寻找名为 puppet-foo 的可执行文件。对于 Windows 系统,Puppet 会尝试为 puppet-foo 文件加上 .COM、.EXE、.BAT、.CMD 等 Windows 可执行文件的后缀名进行查找。
外部命令路径的解析由 Puppet::Util.which 方法提供。它实现了一个类似于 UNIX 系统中 which 命令,可以传递给该方法一个绝对路径,或者命令名。如果找到该命令,则返回对应的绝对路径,否则抛出异常。
执行
def run
Kernel.exec(@path_to_subcommand, *@command_line.args)
end
Ruby 解释器不对外部命令的执行负责,直接调用 Kernel.exec,用外部命令的进程替换掉当前 Puppet 的进程。
小实验:用 Puppet 执行外部命令
首先,让我们为 top 命令创建一个别名:
$ which top
/usr/bin/top
$ sudo ln -s /usr/bin/top /usr/bin/puppet-top
现在,调用 puppet top ,我们马上就进入了 top 命令。这个小实验为扩展 Puppet 提供了一些思路,但考虑到执行外部命令时,Puppet 会让出控制权,因此这样的扩展是及其有限的。
应用子命令
查找规则
在讨论完三种相对简单的子命令后,我们将关注的焦点移动到相对复杂的内部子命令中。首先,“应用子命令”可能不是一个很好的名字,也许叫做“内部子命令(InternalSubcommand)”更佳合适。这是因为 ApplicationSubcommand 所对应的文件会被 Ruby 解释器加载,并在 Puppet 程序的上下文中继续执行——这与替换掉 Puppet 进程执行的外部子命令形成了鲜明对比。
- 文件:
lib/puppet/util/command_line.rb
private
def find_subcommand
# 有意省略了部分代码
elsif Puppet::Application.available_application_names.include?(subcommand_name)
ApplicationSubcommand.new(subcommand_name, self)
# 有意省略了部分代码
end
类方法 Puppet::Application.avaliable_application_names 可以根据搜索查找到的文件,返回所有可以使用的子命令的名字构成的数组。如果 <subcommand> 存在于这个数组中,那么它就被定义为一个应用子命令。下面是 avaliable_application_names 方法的定义:
- 文件:
lib/puppet/application.rb
@loader = Puppet::Util::Autoload.new(self, 'puppet/application')
# 有意省略了部分代码
# @return [Array<String>] the names of available applications
# @api public
def available_application_names
@loader.files_to_load.map do |fn|
::File.basename(fn, '.rb')
end.uniq
end
puppet/application 文件夹下的脚本文件所对应的子命令都是应用命令,例如,子命令 agent 就与 puppet/application/agent.rb 文件相对应。需要注意的是,Puppet 利用了一个 Puppet::Util::Autoload 类的对象 @loader 来执行目录查找,而 Autoload 对象的默认查找的路径包括:
-
gem_directories:当前系统安装的所有 gem 的路径; -
module_directories(env):安装的所有 Puppet 模块的路径; -
libdirs:Puppetlib文件夹的路径,默认值是$vardir/lib; -
$LOAD_PATH:Ruby 的文件加载路径;
理解应用子命令的查找规则后,我们开始考虑应用子命令的加载与执行。
加载
由于 Autoload 类的设计,脚本文件的内容还需要满足一些约束:
- 必须定义在 Puppet::Application 命名空间下;
- 必须是 Puppet::Application 的子类;
- 必须采用驼峰式大小写风格书写类名;
也就是说,应用子命令 my_subcommand 应该对应:
-
puppet/application/my_subcommand.rb文件; - 文件中应该包含这样的类定义:
class Puppet::Application::MySubcommand < Puppet::Application;
如果 my_subcommand 对应的是一个有效的应用子命令,那么 Puppet 就使用一个 ApplicationSubcommand 来加载它。ApplicationSubcommand#run 方法会被调用,在此方法中,代码 Puppet::Application.find 方法用于找到 @subcommand_name 所对应的 Ruby 文件,加载该 Ruby 文件,并返回在该 Ruby 文件中定义的类。这样做之所以可行,是因为就像我们前面所解释的那样,文件名和文件内容之间需要满足一定的映射关系。类似的技巧在很多 Ruby 项目中使用。
- 文件:
lib/puppet/util/command_line.rb
class ApplicationSubcommand
def run
# 有意省略了部分代码
app = Puppet::Application.find(@subcommand_name).new(@command_line)
Puppet::Plugins.on_application_initialization(:application_object => @command_line)
app.run
end
end
随后的 new 会实例化该类的一个对象,并且,Puppet 会将 @command_line 作为参数传递给 new 方法,这样,我们编写的子命令就可以通过解析 @command_line 来处理命令行参数。
实例化完成以后,加载过程完成,调用 app.run,进入到子命令的执行。程序的控制权转移到 Puppet::Application 类及其特定子类。
执行
Puppet 所有的应用命令都继承自 Puppet::Application 类,而子类大多没有覆盖父类的 run 方法,因此我们有必要考察一下 Application 类是如何定义命令的执行的。
- 文件:
lib/puppet/application.rb
def run
exit_on_fail("get application-specific default settings") do
plugin_hook('initialize_app_defaults') { initialize_app_defaults }
end
Puppet.push_context(Puppet.base_context(Puppet.settings), "Update for application settings (#{self.class.run_mode})")
configured_environment_name = Puppet[:environment]
if self.class.run_mode.name == :agent
configured_environment = Puppet::Node::Environment.remote(configured_environment_name)
else
configured_environment = Puppet.lookup(:environments).get!(configured_environment_name)
end
configured_environment = configured_environment.override_from_commandline(Puppet.settings)
# Setup a new context using the app's configuration
Puppet.push_context({ :current_environment => configured_environment },
"Update current environment from application's configuration")
require 'puppet/util/instrumentation'
Puppet::Util::Instrumentation.init
exit_on_fail("initialize") { plugin_hook('preinit') { preinit } }
exit_on_fail("parse application options") { plugin_hook('parse_options') { parse_options } }
exit_on_fail("prepare for execution") { plugin_hook('setup') { setup } }
exit_on_fail("configure routes from #{Puppet[:route_file]}") { configure_indirector_routes }
exit_on_fail("log runtime debug info") { log_runtime_environment }
exit_on_fail("run") { plugin_hook('run_command') { run_command } }
end
这里用到了模板方法的模式,run 方法定义了子类方法执行的步骤,子类只需要完成或实现这些方法即可:
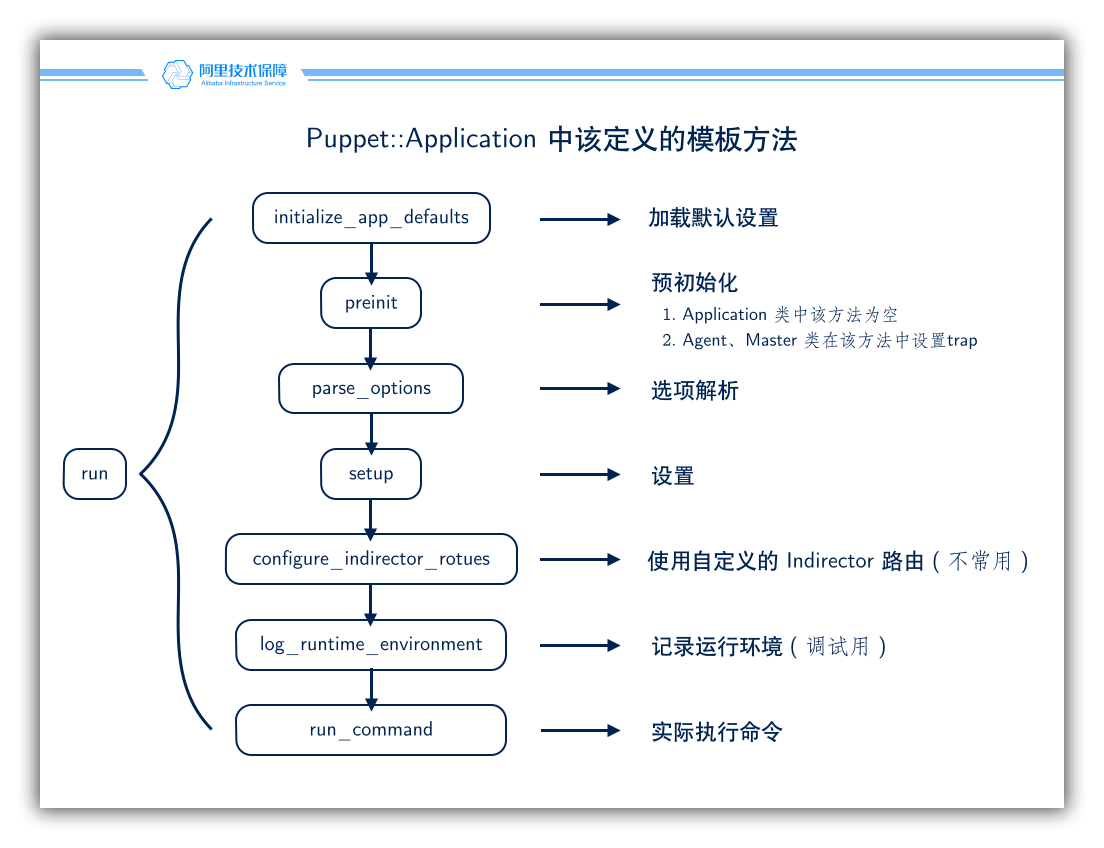
这里有必要明确地提一下 exit_on_fail 这个方法,这个方法由模块 Puppet::Util 提供。由于在顶层环境抛出异常会导致 Ruby 解释器退出,所以 Puppet 特意封装了 exit_on_fail 这个方法。我们可以将想要执行的代码作为代码块传递给 exit_on_fail ,后者会帮我们做异常处理。
- 文件:
lib/puppet/util.rb
# Executes a block of code, wrapped with some special exception handling. Causes the ruby interpreter to
# exit if the block throws an exception.
#
# @api public
# @param [String] message a message to log if the block fails
# @param [Integer] code the exit code that the ruby interpreter should return if the block fails
# @yield
def exit_on_fail(message, code = 1)
yield
# First, we need to check and see if we are catching a SystemExit error. These will be raised
# when we daemonize/fork, and they do not necessarily indicate a failure case.
rescue SystemExit => err
raise err
# Now we need to catch *any* other kind of exception, because we may be calling third-party
# code (e.g. webrick), and we have no idea what they might throw.
rescue Exception => err
## NOTE: when debugging spec failures, these two lines can be very useful
#puts err.inspect
#puts Puppet::Util.pretty_backtrace(err.backtrace)
Puppet.log_exception(err, "Could not #{message}: #{err}")
Puppet::Util::Log.force_flushqueue()
exit(code)
end
module_function :exit_on_fail
回到 run 方法中来,在它定义的几个步骤中,除 run_command 方法外,其它几个方法都在 Application 中定义好了,子类只需要根据具体需求覆盖这些方法即可。而 run_command 方法通过一些 Ruby 技巧,间接实现了 Java 中的抽象方法的效果——如果子类没有实现该方法,程序就会抛出异常——这意味着子类必须实现该方法。因此,我们需要尤为关注这个方法。
def main
raise NotImplementedError, "No valid command or main"
end
def run_command
main
end
子类可以根据需要选择覆盖 main 方法或 run_command 方法实现实际的执行结果。
小实验:以应用子命令的方式扩展 Puppet
在“查找规则”小节中,我们介绍 Puppet 会从四个路径搜索应用子命令,这为我们扩展 Puppet 提供给了无穷的想象力。在本节中,我们将简单介绍,如何通过编写 Ruby Gem 来实现一个 Puppet 应用子命令。
首先,我们需要新建一个 Ruby Gem,我们可以利用 Bundler 来创建一个 Gem 骨架:
$ bundler gem my_app
然后新建 lib/puppet/application 目录,并在该目录下新建 my_app.rb 文件。作为示例,这里在文件中输入下面的内容,其中,options 是在 Application 类中定义的用于参数处理的方法,Puppet 的参数处理机制,我们会在后面的文章中讨论:
class Puppet::Application::MyApp < Puppet::Application
option("--from [NAME]") do |name|
options[:from] = name
end
def main
from = options[:from] || "my customize application subcommmand"
puts "Greet from #{from}."
end
end
打包并安装 Gem。
$ gem build my_app.gemspec
$ gem install my_app-0.1.0.gem
这时候就可以尝试运行我们自定义的应用命令了!
$ puppet my_app --from me
Greet from me.
$ puppet my_app
Greet from my customize application subcommmand.
这里只是演示了通过编写 Ruby Gem 来扩展 Puppet 应用子命令,之所以这样做,很大程度上是为了代码分发。实际上,我们还可以利用 Puppet 的插件同步(PluginSync)机制来实现类似的扩展。
Puppet 对扩展友好,并预留了各种扩展方式。读者完全可以发挥想象力,利用 Ruby 的动态特性,通过继承等手段(合理使用猴子补丁也无妨),根据需要定制 Puppet!
plugin_hook 模式
读者也许会注意到 plugin_hook 这个方法,这个方法用到了许多 Ruby 黑魔法实现了一个非常灵活的效果。例如,考虑代码:
- 文件:
lib/puppet/application.rb,有意重新编排了格式
exit_on_fail("initialize") do
plugin_hook('preinit') do
preinit
end
end
它完成了这样几个步骤:
-
plugin_hook会首先向 Puppet 所有已载入的插件广播,即,调用他们的before_application_preinit方法。 - 然后执行传递给它的
preinit方法,并记录该方法的返回值。 - 此后,再调用所有插件的
after_application_preinit方法。 - 最后,返回刚才调用的
preinit方法的返回值。
对于有元编程经验的程序员来说,理解 plugin_hook 方法的实现并不构成问题,它的实现代码如下:
def plugin_hook(step,&block)
Puppet::Plugins.send("before_application_#{step}",:application_object => self)
x = yield
Puppet::Plugins.send("after_application_#{step}",:application_object => self, :return_value => x)
x
end
private :plugin_hook
需要说明的是,这个设计最初是为扩展 Puppet 而预留的,但实际上它并没有多大的用处。首先,Puppet 会在几个目录中搜索 plugin_init.rb 文件,但初始搜索路径只有 $LOAD_PATH ,这是非常有限的。其次,这个功能已经在 4.X 系统中被去掉了。
结语
在这篇文章中,我们讨论了 Puppet 的启动过程,了解了 Puppet 中四类命令的查找与加载。请读者仔细理解其中的运行机制,我们将在后面的章节中,继续介绍 Agent 和 Master 的启动过程。
 好文啊,建议楼主出 电子书。
好文啊,建议楼主出 电子书。