Ruby Ruby 版 Leetcode,已水完 100 题,求同好 Review
忽然就发现 leetcode 支持 ruby 了。然后就开始刷刷刷,从月初到现在,终于刷完了 100 题简单题。下面说下感受:
1.确实有开挂的感觉,使用 ruby 的话可以不用关心溢出、字符串数字互转、二进制十进制互转。对于专门要考察这些操作的题不应当使用 ruby 特性解决外,其他问题完全可以利用这种特性;
- ruby 的负数除法是向负无穷取整的。10/(-3) 得到的是 -4 而不是 -3。这和 c 系语言向零取整恰好相反。这样,c 系语言能过的用例,只要有负数除法,ruby 必然过不了,需要处理一下才能 AC。记得这个问题是在求解逆波兰式时遇到的。
- 如果题目要求不要返回任何对象,那你需要在方法的最后一行填上 return 空语句。否则 ruby 会把之前循环体或者其他最后的对象返回。
- 如果需要返回空串,就 return "", return String.new 产生的是个空数组 [ ] 。
- 用 ruby 刷题,性能根本不是问题,一般只比 c 慢。举个昨天刚 ac 的例子:如下图。本题是将 k 个一组的链表节点逆置,应该没有多种解法,优化空间小。
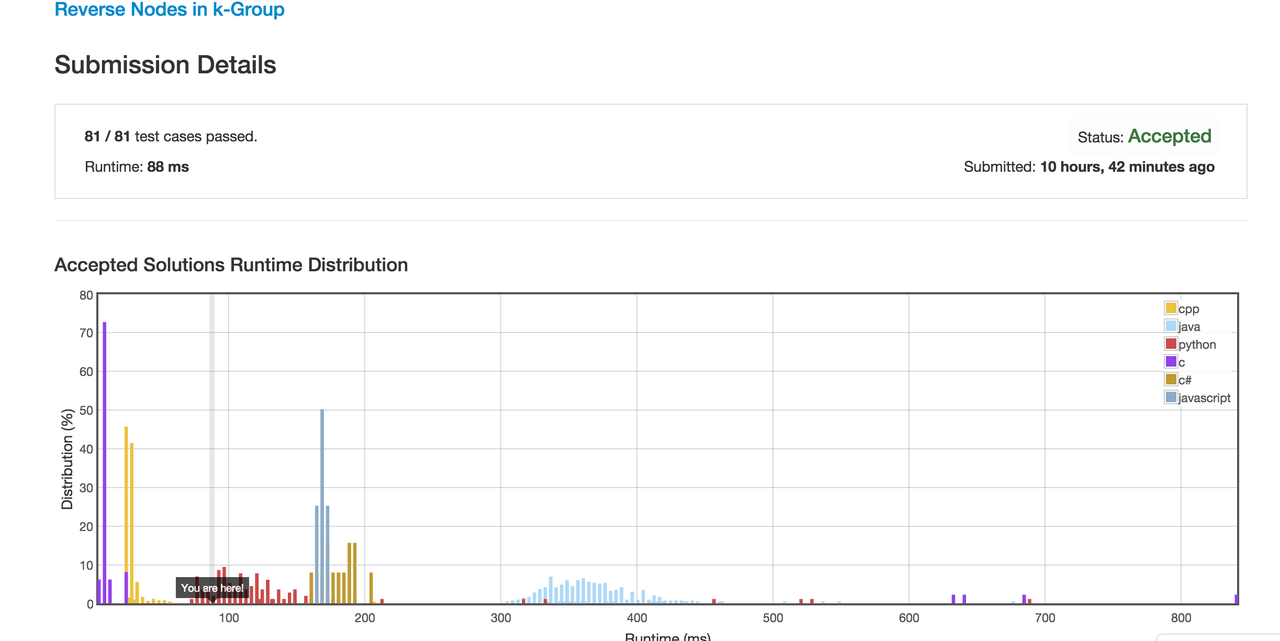
偶尔会比其他一两种语言慢一点,但一般绝不会比 python 差。
6.如果不幸发生了超时,除了优化算法,还可以使用 profile 工具确认是那些方法导致的。做 3sum 时,我使用了二分搜索查找值,但总是超时。还能是哪里出问题?可能要提前剪枝?我加了一些判断,若第一个数就大于零,就直接跳过。几个用例就通过了,但剩下的仍然通不过,我将第三个数也加了相同剪纸条件,又有新的用例通过,但依旧 TLE。怎么办?那天刚好看到本站友人介绍 profile 工具,就现学现用了。测了一下,发现 bisearch 耗时占 75%。问题一定是出在这里了。仔细查看代码,发现,应该当查找 bisearch(nums,m+1,h,target) 这里的 m+1,我误写成了 l+1。性能比逐次查找的还要差。修改错误后直接 ac。
- 部分题目可以使用闭包。比如 zigzag convert 字符串。可以用闭包产生下一个坐标。raise
- 有时我竟然利用了异常处理来解题,不知道这样的做法是不是超出了算法界讲究的 RAM 模型。比如,某题需要递归求值,但如果递归遇到特定条件时,应该立即返回特定值给主程序。但使用普通的 return,值只会传递给堆栈的下一级。方法的结束不是有 return 和 raise exception 两种方式吗?于是我拿出了不受欢迎的 raise,这样,原本超时的题目竟然 ac 了。这样真的好吗?
搜了一下本站,就发现半年前有人要用 ruby 解题,但有人只做了很少的几道题就不了了之了。下面是我最新 ac 的 100 题,其中 90% 以上的题目用 ruby 完成,有几道是刚开始用 java 做的,也有的是因为题目并没有提供 ruby 版本。
https://github.com/acearth/LeetCodePractice
一般来说,一个好方法的长度不应该超过 10 行代码。但解题时,代码是“一处编写,一处运行”,几乎不会有任何重用。我将自己在 20 行以内的解法视为可接受的解法。同时,有几道题使用了 ruby 的语法特性,这种做题目能 ac,但对涨姿势却一点作用也没有。从这个角度来说,4 行以下的方法不算好方法。从这种评判角度来说,我的代码,有 50% 以上的都是不合格代码,而剩下的解法中,还有很多是算法非最优,或者代码啰嗦的。这么说,这些代码都不该拿出来。但我还没发现有人公布 ruby 版的 leetcode 解法,就当是抛砖引玉吧。
看了第一题 Two Sum 你的解法 800 多 ms
def two_sum(nums, target)
pro=Hash.new
nums.length.times do|i|
pro[nums[i]]=i+1
end
nums.length.times do|i|
k=target-nums[i]
if nums.include? k
if(i+1 != pro[k])
return [i+1,pro[k]]
end
end
end
end
加个 hash 来记录,性能会好很多,80 多 ms
def two_sum(numbers, target)
hash = numbers.map.with_index.to_h
found = numbers.find.with_index do |n, index|
target_index = hash[target - n] and target_index != index
end
[numbers.index(found) + 1, hash[target - found] + 1].sort
end
Happy Number 你的解法,116ms
def is_happy(n)
a=n.to_s
a=a.to_s
k=0
while true
ss=a.to_s
d=0
ss.length.times do |i|
di=ss[i].to_i
d+=di**2
end
a=d
return true if d==1
k+=1
return false if k>100
end
end
多用 hash,96ms
def is_happy(n)
hash = {}
while hash[n].nil? do
n = hash[n] = n.to_s.chars.inject(0){|m, c| m + c.to_i * c.to_i}
end
n == 1
end
再抽了几个题目看一下,我觉得你写的代码太不像 ruby 了...
你的 https://github.com/acearth/LeetCodePractice/blob/master/isomorphic.rb 18 行
可以用 hash 的 uniq keys 来判断,3 行解掉:
def is_isomorphic(s, t)
h = {}
s.chars.each_with_index{|c, i| h[c] ||= t[i]; return false if h[c] != t[i]}
return h.keys.uniq.size == h.values.uniq.size
end
https://github.com/acearth/LeetCodePractice/blob/master/compareVersion.rb 30 多行
可以用 ruby 的数组<=>操作,8 行解掉:
def compare_version(version1, version2)
v1 = version1.split('.').map(&:to_i)
v2 = version2.split('.').map(&:to_i)
if v1.size > v2.size
v2 += [0] * (v1.size - v2.size)
elsif v2.size > v1.size
v1 += [0] * (v2.size - v1.size)
end
v1 <=> v2
end
另外 leetcode 的测试代码大部分是来自 C 的,ruby 的数字没有超界问题,有一些就可以投机了 比如 Factorial Trailing Zeroes,就可以一行解掉:
def trailing_zeroes(n)
(1..13).to_a.map{|i| n / 5 ** i}.inject(:+)
end
还可以利用强大的内置对象,比如 count primes,require 一下,也是一行解掉
require 'prime'
def count_primes(n)
Prime.each(n - 1).to_a.size
end
^_^
#5 楼 @quakewang 感谢@quakewang 指正,我写 ruby 纯属自娱自乐,往往不清楚某一块是写的好还是烂。现在有了镜子,终于可以打磨代码了。
#6 楼 @quakewang factorial trailing zero 用 inject 最快,做这题要利用遇 5 添 0 的阶乘性质,用 inject 体现了这种思想。但求素数,如果直接用内置对象,那题目是能做出来,但违背了做题的目的。这里我只能看到你熟悉 prime 对象,却难以知晓你是否会求解。
以前做 acm,好多题目都是 c 和 c++ 混着写的,高精度的题目用 java, 要是换成 ruby,就舒服很多了,@arth, 话说楼主,你也很闲啊。用 ruby 解算法题。
如果数学不太好,可以买 leetcode 的书 https://leetcode.com/book/ 15 刀那个就可以了. 里面会教你怎么把 two sum 从 800ms 优化到 80ms
#6 楼 @quakewang 虽然 5*13 接近 2*32,但对于小的数字还是多算了几遍
haskell 比较简单
trailingZeros = (sum . takeWhile (>0) . iterate (div5))
一点都不函数式的办法其实也很好呢...
def trailing_zeroes n
zeros = 0
zeros += n /= 5 while n > 0
zeros
end
贴一个数字转罗马数的代码
def int_to_roman(num)
dfs(num,"")
end
def dfs(val,tmpStr)
case val
when 1000..3999 then dfs(val-1000,tmpStr+'M')
when 900..999 then dfs(val-900,tmpStr+'CM')
when 500..899 then dfs(val-500,tmpStr+'D')
when 400..499 then dfs(val-400,tmpStr+'CD')
when 100..399 then dfs(val-100,tmpStr+'C')
when 90..99 then dfs(val-90,tmpStr+'XC')
when 50..89 then dfs(val-50,tmpStr+'L')
when 40..49 then dfs(val-40,tmpStr+'XL')
when 10..39 then dfs(val-10,tmpStr+'X')
when 9 then return tmpStr+'IX'
when 5..8 then dfs(val-5,tmpStr+'V')
when 4 then return tmpStr+'IV'
when 1..3 then dfs(val-1,tmpStr+'I')
when 0 then tmpStr
end
end
p int_to_roman 1
p int_to_roman 1999
p int_to_roman 1880
这个题可以把 4*,9的情况并入到 5##,1**的情况里,但是会引入不必要的代码。有朋友说 case 太多了,该怎么优化
代码地址 https://github.com/acearth/LeetCodePractice/blob/master/int_to_roman_dfs.rb
ROMANS = [%w(I II III IV V VI VII VIII IX),
%w(X XX XXX XL L LX LXX LXXX XC),
%w(C CC CCC CD D DC DCC DCCC CM),
%w(M MM MMM) + [''] * 6]
def int_to_roman(num)
r, i = '', 0
while num != 0 do
r = ROMANS[i][num % 10 - 1] + r unless num % 10 == 0
num /= 10
i += 1
end
r
end
新手上路
学习 Ruby 大概一周左右,受这帖子的启发开始用 Ruby 重新实现 Leetcode 上面的问题,之前找工作时 Leetcode 上面的题目都做过一遍,问题的思路是有的,更多的是关注语法层面怎么实现自己的想法。
遇到个想不明白的地方,借这个帖子请教一下: Ruby 程序如何在简洁和易读性之间取舍?
用 Anagrams 这个问题举例:
第一个版本基本上是重写了之前的 C++ 代码:
def anagrams(strs)
hash = Hash.new
strs.each do |str|
sorted_str = str.chars.sort.join # sort each string in alphabetic order
hash[sorted_str] ||= []
hash[sorted_str] << str
end
hash.values.select{ |element| element.size > 1 }.flatten
end
后来掌握了如何使用 Ruby 的 Hash 做计数器,代码缩短成了这个样子:
def anagrams_even_shorter(strs)
hash = Hash.new{ |h, k| h[k] = Array.new }
strs.each { |str| hash[str.chars.sort.join] << str }
hash.values.select{ |value| value.size > 1 }.flatten
end
我现在的水平,anagrams 这个函数比较好理解,anagrams_even_shorter 看起来会比较费劲,想问一下各位大神,第二个版本的代码是否过度追求程序简洁导致可读性的降低?
先谢过了。
#26 楼 @noisedispatch 找个平衡就好,比如团队中可以规定一行代码不能超过 80 个字符之类的。 第 2 个版本挺好的,真要追求简洁的话,我就会 one liner 了(通常会被其他人打
def anagrams(strs)
strs.inject(Hash.new([])){|h, s| h[s.chars.sort.join] += [s]; h}.values.select{ |v| v.size > 1 }.flatten
end
#27 楼 @quakewang 看看我的解法是不是短点
def anagrams(strs)
strs.group_by{ |s| s.chars.sort }.values.reject{ |v| v.length == 1 }.flatten
end
感谢点评,Ruby 刚起步,简洁具体指什么还在慢慢体会,现在的感觉就是如果思路是清晰的,实现的时候就可以做到很简洁,比如第一个版本的代码(基本上就是按照 C++ 的实现方式在写),很多都是自己陷入原来的思维模式,认为需要一个 Hash of String array 但是在 Ruby 中是不需要的。至于可读性,还是要对 Ruby 语言有一定程度的理解才好。
看了 #28 @nouse 的代码,真的就是我的想法,在此一并谢过。
#3 楼 @quakewang 受你启发,我重写了 two sum。最多遍历数组一次。而且无需对数组排序。同时,按序遍历保证会将结果按序输出。代码如下。总共 4 行,68ms。
def two_sum(nums,target)
hash=Hash.new
nums.each_with_index {|n,i| return [hash[n],i+1] if hash[n]!=nil; hash[target-n]=i+1 }
end
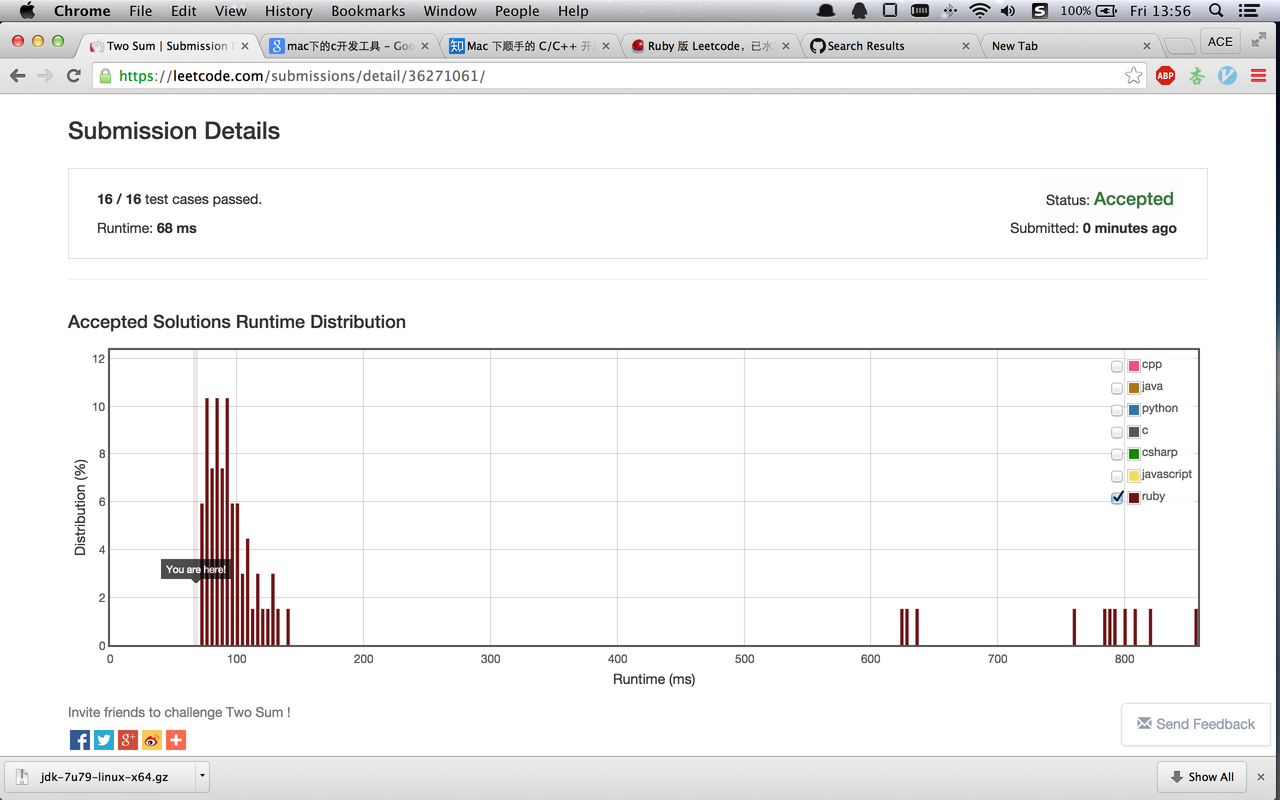 顺便发个图正确多待一会首页。
顺便发个图正确多待一会首页。