http://codeforces.com/blog/entry/10024 看这个对比,吓了一跳!
擦!真是个大问题啊!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
这种比较网路上有很多,以下这种是比较 OO 问题解决的: http://blog.dhananjaynene.com/2008/07/performance-comparison-c-java-python-ruby-jython-jruby-groovy/ 当然又跟你的有差别,不过重点还是“参考就好”。选语言时碰到瓶颈再担心这个吧。
我以前也纠结这种评测。于是从c#到java,从java到nodejs,从nodejs到go。直到我看了两本书,黑客与画家,松本行弘的程序世界。并且联系到现实的工作。我才彻底的逃离了这种纠结。
首先,有这种纠结的朋友,肯定是热爱编程的,纠结的原因是追求完美。但往往这种纠结总是发生在脱离现实的前提下,也就是所谓的工程师思维。
我很赞同黑客与画家里说的一段话。语言之间,根据图灵定律,都有能力实现相同的功能。但程序员每天能写的代码量是固定的。假设平均来说,一个程序员一天能写 100 行代码。那么不管他用什么语言,基本上一天的代码量都是 100 行左右。可是 100 行代码,根据不同的语言,实现的功能差别就很大了。
另外,就是大家说的很多的瓶颈问题。语言之间的确有性能差别。可是性能差别是瓶颈么?这往往是工程师思维所忽视的问题。要回答这个问题,就一定要回到现实。比如 pv 1 千的网站,和 pv 1 千万的网站。他们的瓶颈肯定不一样。pv 1 千的网站,平静不在技术。更多的问题是运营。pv 1 千万的网站,可能会有性能问题。
不难发现,当我们回到现实的时候,其实我们所纠结的问题就很简单了,就没什么好纠结的了。性能有问题?加机器,换语言。什么有效做什么。而且 pv 1 千万说明产品不错,这时候,即便换语言也是很有信心的,没什么好纠结的。
总而言之,不是说不应该纠结这个问题。但绝大多数时候,我们是在浪费时间。就像我看到的一个笑话。小时候我总是纠结上清华还是上北大。长大了才知道其实我想多了。


@discover 不知道楼主以及各位跑过这个测试没? 在我的 iMac 2011 的机器上,我跑了一下 Py 和 Rb 的测试,结果和他给的结果很不一样啊: 为了节约时间,我把 Py 和 Rb 中的 10000000(7 个零)都改为 1000000(6 个零):
Python 的结果:14682.005000 Ruby 的结果:12301
Python 和 Ruby 在一个数量级,而且 Ruby 还快一点。明显与他的测试结果不符啊。 Py version: 2.7.5(Mac OS 自带的) Rb version:2.0.0-p353
用 2.1.0-preview2 跑了下,比 2.0 快了不少了,已经比 python3.3 快了
$h[pos], $h[j] = $h[j], $h[pos]
写成
tmp = $h[pos]
$h[pos] = $h[j]
$h[j] = tmp
就能快不少
优化前:68091 优化后:58694
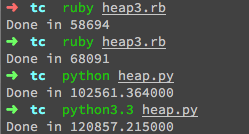
#36 楼 @skandhas 对啊,之前的 jjyr benchmark 也是类似的结果 http://ruby-china.org/topics/12688
很奇怪啊,几乎一样的实现 (Python 只是没有 direct threading),Ruby 1.9/2.0能快很多
#44 楼 @skandhas #29 楼 @ShiningRay #36 楼 @skandhas #42 楼 @bhuztez 难得大家还有雅兴关心一下 windows,那我运行一下算了,heap2.rb用了国外一个看不下去黑 ruby 的大神的 pull request。
ruby 2.0.0p353 (2013-11-22) [i386-mingw32]
C:\git>ruby heap.rb
Done in 424610
C:\git>python --version
Python 2.7.2
C:\git>python heap.py
Done in 154276.321575
C:\git>ruby heap2.rb
93.679000 0.016000 93.695000 ( 94.284052)
结论是 Python 2.7 154 秒 vs Ruby 2.0 94 秒
update:为了公平,还特意升级到了 python 最新的 2.7.5.6 ActiveState 版本
C:\git>python heap.py
Done in 154711.043911
C:\git>python --version
Python 2.7.5
显然新版本更慢一点。。
Ruby 代码主要就是 a, b = b, a 这里手工展开所以才比 Python 2.7 快了,
我去掉了个 0,实在太久了,等不起。
$ python --version
Python 2.7.5
$ python3 --version
Python 3.3.2
$ pypy --version
Python 2.7.3 (352c78d2e80f4a812ae1d8cdbe8c01a7f2e6fbc0, Aug 19 2013, 10:43:46)
[PyPy 2.1.0 with GCC 4.8.1 20130603 (Red Hat 4.8.1-1)]
$ ruby --version
ruby 2.0.0p247 (2013-06-27 revision 41674) [x86_64-linux]
$ python heapsort.py
17.9021840096
$ python3 heapsort.py
30.28932676600016
$ pypy heapsort.py
0.749085903168
$ ruby heapsort.rb
23.450000 0.010000 23.460000 ( 23.611715)
代码改成一致的实现,不能因为一边有更快的写法就用更快的写法。
from __future__ import division, unicode_literals, print_function
import timeit
try:
range = xrange
except NameError:
pass
def pushDown(h, pos, n):
while 2 * pos + 1 < n:
j = 2 * pos + 1
if j + 1 < n and h[j+1] > h[j]:
j += 1
if h[pos] >= h[j]:
break
h[pos], h[j] = h[j], h[pos]
pos = j
def heapsort(size):
heap = list(range(size))
for i in range(size//2, -1, -1):
pushDown(heap, i, size)
for n in range(size-1, 0, -1):
heap[0], heap[n] = heap[n], heap[0]
pushDown(heap, 0, n)
for i, e in enumerate(heap):
assert i == e, "Array not sorted"
if __name__ == "__main__":
print(timeit.timeit("heapsort(1000000)", setup="from __main__ import heapsort", number=1))
require 'benchmark'
def push_down(heap, pos, n)
while (2 * pos + 1) < n
j = 2 * pos + 1
if (j + 1 < n) and (heap[j + 1] > heap[j])
j += 1
end
break unless heap[pos] < heap[j]
heap[pos], heap[j] = heap[j], heap[pos]
pos = j
end
end
def heapsort(size)
heap = (0...size).to_a
(size / 2).downto(0) do |i|
push_down heap, i, size
end
(size - 1).downto(1) do |n|
heap[0], heap[n] = heap[n], heap[0]
push_down heap, 0, n
end
raise "Array not sorted" unless heap.each.with_index.all? { |element, index| element == index }
end
puts Benchmark.measure { heapsort 1000000 }
#47 楼 @skandhas 当处理的数量级达到一定大的程度的时候,确实会出现对性能的影响
我的测试结果
$ ruby -v
ruby 1.9.3p448 (2013-06-27) [i386-mingw32]
# 七个零的结果
$ ruby heap.rb
Done in 893057
# 六个零的结果
$ ruby heap.rb
Done in 17729
作为对比的 python 结果
$ python --version
Python 2.7.6
# 七个零的结果
$ python heap.rb
Done in 179158.244072
# 六个零的结果
$ python heap.rb
Done in 14071.505574
作为对比的 java 结果
$ java -version
java version "1.7.0_45"
Java(TM) SE Runtime Environment (build 1.7.0_45-b18)
Java HotSpot(TM) 64-Bit Server VM (build 24.45-b08, mixed mode)
# 七个零的结果
$ javac Heap.java
$ java Heap
Done in 1272
# 六个零的结果
$ javac Heap.java
$ java Heap
Done in 138
跑分前均未进行热身,
机器配置
戴尔笔记本
CPU Intel(R) Core(TM) i5-3210M CPU @ 2.5.0GHz 2.50 GHz
内存 16.0GB(15.9 GB 可用)
其实 java 来测试字符串拼接也有类似的情况,在 某个数字之内(不记得具体数字了,大概是 5000)用 + 来拼接字符串毫无影响,但是一旦超过这个数字哪怕就多一次花费时间就上去了好几倍
作为对比的 jruby 结果
$ jruby --version
jruby 1.7.6 (1.9.3p392) 2013-10-22 6004147 on Java HotSpot(TM) 64-Bit Server VM 1.7.0_45-b18 [Windows 7-amd64]
# 七个零的结果
$ jruby heap.rb
Done in 1405441
# 六个零的结果
$ jruby heap.rb
Done in 7037
Real world Ruby:
首先转到 cpp 的目录
g++ -O4 heap.cpp -o heap
然后把 heap.rb 改写成
require "fiddle"
require "fiddle/import"
module Cpp
extend Fiddle::Importer
dlload '../cpp/heap'
extern "int main(int,char**)"
end
Cpp.main 0, nil
java 195 javascript 用 Mozilla 的引擎,速度上和 V8 应该区别不大
js -j 641
js -a -m 1741
在对比 Pypy 的速度
可以认为 ruby 被多加了个 0
哈,用 python 的人现在一般都不在意 python 的性能了,1 是 cpython 性能不会有大的改变了,2 是争论这个也累了。好在 python 现在有 jit 的 pypy, cython 实在是一个利器,numpy 等科学库有大量的优化的数据结构可用,现实中说 python 有性能问题的,不是你业务比肩 google, 就是自己钻研的不够了
Cython 还是略坑
from libc.stdlib cimport malloc, free
from cython import sizeof
cdef pushDown(int *h, int pos, int n):
cdef int j
while 2 * pos + 1 < n:
j = 2 * pos + 1
if (j + 1 < n) and (h[j+1] > h[j]):
j += 1
if h[pos] >= h[j]:
break
h[pos], h[j] = h[j], h[pos]
pos = j
def heapsort(int size):
cdef int i, n
cdef int *heap = <int *>malloc(sizeof(int)*size)
for i in range(size):
heap[i] = i
for i in range(size//2, -1, -1):
pushDown(heap, i, size)
for n in range(size-1, 0, -1):
heap[0], heap[n] = heap[n], heap[0]
pushDown(heap, 0, n)
for i in range(size):
assert i == heap[i], "Array not sorted"
free(heap)
└─> rvm list known
# MRI Rubies
[ruby-]2.0.0[-p353]
[ruby-]2.1.0-head
ruby-head
# JRuby
jruby-head
# Rubinius
rbx[-2.2.1]
rbx-head
# Ruby Enterprise Edition
ree[-1.8.7][-2012.02]
# Mac OS X Snow Leopard Or Newer
macruby-head
Rubinius 如何 呀?
#71 楼 @bhuztez PySonar 实在是太素了,就是个简单的 Abstract Interpretation 做类型计算,加个扫栈去环,parser 直接调用的 Jython 都不用写,真没感受到是什么惊天动地的创举... 但如果加上考虑真实世界是有 thread 和 continuation 这两种平行栈和树状栈的状况,那点代码就不够使了... 而且这种东西设计时先把类型运算的公理列出来吧 (老子从来不看 ICFP 论文集!), 但 PySonar 只能从代码中看做了什么 (还是 Java 的一下就没胃口了)... M$ 研究人员写过利用自动化定理证明来生成 reduction rule 集合的 (把 intel 手册输进去以后就能获得无敌编译器了), 显然 PySonar 没到那个程度。
动态语言做静态分析的可多了,SBCL, Cython, Groovy, Mirah, Diamond-backed Ruby... 各有它们的优缺点。例如 SBCL 就是分析得了就是一条龙,分析不了的就是一条虫。但这些东西都做了巨多的工作,design decision 中也考虑到了各种各样扭曲的 case, 和玩具不是一个层次的...
class A(object):
def x(self):
return 1
A.x(self) 的 self 的类型必须是 A 么 ?
完全没有必要 A.x(None) 也是可以的嘛
- 静态类型:变量名有类型,值不带类型信息
- 动态类型:变量无类型,值带类型信息
- 强类型:检查类型,在编译时 (例如 Haskell) 或者运行时 (例如 Lisp, Ruby)
- 弱类型:不检查类型,例如 ASM, 早期的 PHP 和 Basic (用错类型就会 segfault)
常见静态语言都带有一定的动态能力 (如 C++ 的运行时多态), 但一些要求严格的代码库,如 OpenJDK 会要求多态都在编译时决定好。
但是总有一些人想混淆弱类型和动态类型 (因为他们主张的静态类型没动态类型好听,但强类型比弱类型好听)...
静态分析做推断有两种极端:一种是什么都不丢保持精度 -- 很容易类型闭包信息爆炸内存溢出,另一种是降低精度用比较粗泛的类型去描述复杂类型运算的结果 -- 很容易什么效果都没有。现在的分析都是在这两种极端中找平衡。
看原文后面的评论吧。。
http://codeforces.com/blog/entry/10024#comment-154855
Hi!
Unfortunately, the Ruby implementation is not only very non-idiomatic in terms of code, but it does abuse the assignment operator to perform the exchange. This is why it is slower in the benchmarks. You'll find it performs way better if you take this into account.
Here's a pull request: https://github.com/MikeMirzayanov/binary-heap-benchmark/pull/10
In my testing, this version outperforms Python3 by a factor of 2. No clever tricks added.
Ruby 2.0 我电脑上约 330 s,和该网站比较接近,但 Python 2.7 我测是 120 s 左右,该网站结果应该有问题,另采用最新的 Ruby 2.1 32 bit 结果为 110 s 左右,Ruby 2.1 64 bit 结果为 100 s,稍快于 Python,以上是 Windows 下结果;在 Linux 下,Ruby 2.1 64 bit 结果为 62 s,Python 2.7.5 结果为 84.5 s,均快于 Windows 平台,且测试用的 Linux 在虚拟机中。Ruby 2.0 当 N 较小时快于 2.1 版,但 N 较大时慢于 2.1 版。Ruby 2.1 对于此测试性能已稍胜 Python 2.7。
最近是这样的感觉: 机器上面的 agent 用 C/C++ 开发,要求占用内存少,跟内核打交道 后端业务逻辑 server 用 java 和 go 开发,要求网络编程和多线程编程方便 web 用 ruby 编写,快 对于后端模块如何对性能没要求,用 ruby,方便
