-
学 Ruby on Rails 过程中遇见的一些 “奇怪” 问题??? at 2017年07月09日
第一个 hash 多重输出的问题在一个新的 5.1.2 项目上复现不出来
另外不要覆盖 hash 函数,那个函数存在的
-
rails 中的 table 和 database 是一个概念吗? at 2017年07月08日
Rails 的 Model 指的是 Domain Model(领域模型),这个要去看一下 领域驱动开发 还有 领域模型的资料去,这个也不是 Rails 独有的概念。Active Record 选择的是领域模型中的充血模型
如果不是很精确地去理解的话,也可以把 Rails 的 Model 理解成 数据库表的实体类 + 业务逻辑
-
rails 中的 database.yml 中能设置 mysql 的端口号吗? at 2017年07月08日
一般不会,Rails 也是使用的 mysql2 这个 gem
-
rails 中的 database.yml 中能设置 mysql 的端口号吗? at 2017年07月08日
能不能这样做,跟 mysql 的驱动如何解析 host 有关,看样子不支持那样做
我其实本想直觉上说
port: 3306就能解决了,但是我手头正好有个新的 Rails 项目,我发现使用 mysql 数据库 的 Rails 的新项目模板的database.yml里并不包含port节,一般为了演示用会在文档里提到,然后默认注释掉,比如你看 PostgreSQL 的默认的 database.yml但我没有在 mysql 的看到类似的章节,模板源码在此 https://github.com/rails/rails/blob/master/railties/lib/rails/generators/rails/app/templates/config/databases/mysql.yml
如果你试过加
port奏效,那其实可以说是 Rails 的疏漏了,你可以仿照 postgresql 的那个模板,为 mysql 的增加一个如何指定port的注释,骗一个 PR 来。 -
rails 中的 database.yml 中能设置 mysql 的端口号吗? at 2017年07月08日
URI 加 端口 的文法是
host:port所以,database.yml 里的
host: 127.0.0.1可以试试加上port改成如host: 127.0.0.1:3306 -
我觉的 Ruby China 对新手不太友好 at 2017年07月08日
另外,朋友和我讲,什么都不说,那是最好的,但是总得有人出来当个黑脸,我就是那个“没有 Linus 的命,有着 Linus 的病”。
没错,对于一个常年在职工作的开发人员来说,我们是已经有了很多项目经验以及对这个行业的观点,已经形成了一定感官认识,但是对于一个新人来说,我直接告诉你别走这条路,然后不带任何的理由,尤其你要是把 @jasl 这人喊出来,他不仅不会给你指导,还不耐烦地直接怼你(在另一个帖子)。
他不仅不会给你指导,还不耐烦地直接怼你(在另一个帖子)这句话将来报道出现了偏差,你负不负责任?我第一次回复在 43 楼

这叫“不耐烦怼你”?你的标准是什么?
“代码即正义”是希望自己永远单身孤身一人自己蹲在电脑前的节奏。
做工作不谈效果、收益,那叫儿戏。写代码也不追求“正义”,追求的是 好玩 更关键的是要 解决问题
作为一个新人,他们确实是希望得到帮助、理解和学习,而老人们不是你去仗势按照自己已经定格了的所谓的人生观去评定、评述。因为或许新一代学了这样东西,会有不同的观点,人家跟你的代码观、价值观彻底不一样。
起码大多数在社区里的讨论,都围绕着对人不对事的态度去交流,别扯什么代码观、价值观不一样,也不要拿这个作为借口,现在和未来人前进的基础都是建立在“老人”的成果上的,技术交流只有在什么场景下适不适合?好在技术问题,所有的指标都可以被量化,不然,各说各话还有什么讨论的意思?
你想找代码观、价值观和你相同的,我觉得你要么需要个自己的克隆人,要么自己和自己交流。但,你认为这样有好处么?
如果 Ruby China 总是希望有且只站在 Ruby China 那帮人自己进度去衡量他人,我觉得,确实是比较失望。至少,一开始就不让人发帖子而是先去搜索,对,如果我要去搜索,我一定不会来这里,而是选择 Baigooduck(baidu / google / duckduckgo)。
论坛上线基于 ElasticSearch 的搜索功能前(顺便吐槽下新的搜索不好用),论坛的搜索一直是使用 Google 的站内搜索,没错,其实是希望你去 Baigooduck 的。
但是,即使你即使不指定范围,搜索到的很多关于 Ruby 的技术文章,也是来自 RubyChina 的,搜索引擎也一直是论坛新用户的来源之一。
那么为什么会这样?要感谢这么多年来社区成员的奉献。
所以,你选择 Baigooduck 后,又回到了这里,开不开心?意不意外?
社区的本质是沉淀知识,而“沉淀”则是社区和 IM(微信群、QQ 群等)最大的不同点。
另外,
如果 Ruby China 总是希望有且只站在 Ruby China 那帮人自己进度去衡量他人你来到朋友家,你要让朋友按照你的习惯去伺候你,你咋不上天呢?不成规矩,不成方圆。至于技术问题,那么显然是各抒己见,每个社区管理员都有自己的本职工作,每个成员也都在不同的公司、学校,甚至有着不同的职业,诞生一个RubyChina 精神是不可能的。另外,我以前发一个帖子,关不掉,而且管理员还把帖子重启,添油加醋,我觉得,这里的管理员确实……
那件事嘛,我得道个歉,之后我被严重警告了一次
-
Helix: Build Native Ruby Extensions Without Fear at 2017年07月08日
If you want to use Helix in a gem, and distribute it to users without requiring a Rust compiler, you will need to build binary distributions for your target environment.
We want to support a smooth workflow for specifying your target environments and getting the binaries for each of them. We are exploring both cross-compilation solutions, VM-based solutions, and some combination of the two.
一样在路线图里的~~
-
我觉的 Ruby China 对新手不太友好 at 2017年07月08日
你大可以发帖问问这论坛里有多少人是我的学生,我可能是
常年在职工作的开发人员里,对新人最友好的了,对,我说这话不虚。另外,你可能高估了我的年龄。
-
Rails 里如何定制 bootstrap at 2017年07月08日
-
Helix: Build Native Ruby Extensions Without Fear at 2017年07月08日
rust 官网中讲的和 helix 没关系,helix 的野心相当大,他的目标是用 rust 代码在 ruby 层面和一般的 ruby 代码的行为完全保持一致,这个可以看下他官网的 roadmap#drop-in-replacement
-
大家有被颈椎病困扰的吗? at 2017年07月08日
- 有那种专业的运动康复教练,如果你有幸能认识一位(国内专业的很少,很多是省市国家级运动队退下来自己干个体户的),效果拔群,但是收费较贵。
- 平时注意锻炼
- 一把好椅子可以有效避免问题复发
- 一个好枕头可以有效避免问题复发,我也是疼到起不来床之后才知道原来枕头还可以卖到上万元的(并不是那种啥玉石做的装逼枕头)...
-
主要还是因为 Assets Pipeline 没能够打动前端圈子,最终 Rails 决定向前端社区妥协,按照他们的风格办事,其中 yarn 是最符合 DHH 口味的(其实 yarn 可以理解成“更好的”npm,依赖声明
package.json也是复用 npm 的,并且 yarn 的主力开发 Yehuda Katz 还曾是 Rails core team 成员)。对于 Rails 项目来说,集成一个前端框架的最好的方式是引入对应的 gem,比如 jquery-rails font-awesome-sass bootstrap-sass 这些 gem 按照 Assets Pipeline 的最佳实践原则组织文件,提供 helper,并且可以对 AP 做一些 tweak(比如 font-awesome 自动把他的 fonts 文件加入到预编译的列表里,调整 CSS 编译器和 JS 压缩器的参数等)
但是,前端的库层出不穷,只有极少数的前端项目接纳了 Assets Pipeline,面对没有接纳 AP 的项目,只能拉下他们的代码,放入到 vendor 目录,这是很土很落后的做法了。
Rails 在正式把 yarn 加入套餐前,社区里就有很多种方案了,npm-rails bower-rails 等,Rails 集成 yarn,算是提出了官方的前端依赖管理的解决方案,把法(AP)外之地的管理现代化。
至于 webpacker,他算是复用了这部分基础设施而已
-
Helix: Build Native Ruby Extensions Without Fear at 2017年07月08日
这个项目已经算是推倒重来一次了,第一次比较正式的介绍应该来自这篇 http://blog.skylight.io/introducing-helix/ 去年新加坡的红点 RubyConf 上 Godfray 还谈论了这个项目。
最开始这个项目是在 https://github.com/rustbridge 组织下的(里面还有一个 rust-nodejs 的 bridge 项目,但目前都已被清空了),然后,这个项目在几个月后,就太监了...
同时在发展的还有一个项目 https://github.com/d-unseductable/ruru 几个月断更之后,刚刚看到作者又在继续开发了。
再然后就是 usehelix.com 上线,Yehuda Katz 的公司全面接管项目,看上去也有了喜人的进展。
衷心看好这个项目,如果能够达成路线图的目标,一定会救赎 Ruby 和 Rails,底层通过高性能语言实现,Ruby 作为上层暴露的接口,就像 Python 在 TensorFlow 的作用一样。
-
这下真伤心了 at 2017年07月08日
我这不还没入监呢么...
-
这下真伤心了 at 2017年07月08日
我要开始怼人了。
你是 2013-12-22 注册的论坛,可以说,你是社区的早期成员了,今天是 2017 年 7 月 8 日,在近四年的时间里,你有多少进步?是不是总结出了值得分享的心得?是否变成“过来人”可以解答新手的问题了?你现在居然说
我能做的就是把这个问题提出来,你是不是在承认自己四年的时间毫无成长?我觉得也已经体现我的价值了所以四年后的今天你还就这点价值?我为什么要冒天下之大不韪,发如此敏感的话题,惹得广大老鸟们生气呢?
- 你以为没有人思考 Rails 为什么衰退么? Ruby 和 Ruby on Rails 在 2017 年 还有前途吗?
- 你以为管理员没有思考论坛为什么不活跃了么? Ruby China 正在衰退吗?
- 你意识到论坛
不活跃而你的实际行动是什么?平常潜水,你就是那个不活跃分子好不好。 - 你真的只惹到老鸟们生气了么?点开每一个回复你的用户,看看他们的发帖和回复,自己去判断。
你一边抱怨着论坛不活跃了,一边高谈阔论,你指出的解决方法有根据么?
- 要求别人活跃帮助他人不计较付出,自己
平常潜水 - 要求社区成立委员会,明确社区发展导向。这个委员会本身就是公开的 关于 - 社区管理员
- 完全可以依托论坛成立商业公司,你知道成立公司要做哪些事情么?付出多少精力和金钱?我 @Rei 我俩管理员都曾是创业者, @lgn21st 现在仍在积极创业,我们都对成立公司的程序和操作以及代价有一定了解。你建议成立公司的依据是什么?程序和代价是什么?成本核算?如果社区要成立公司,你会出资支持么?
我们欢迎意见,但我们(无论是社区也好还是现实中的自然人)希望得到的是“建设性”意见。
你因为没有人支持你的观点而伤心了,你的不负责言语有没有伤害到别人呢?想过没有?
不管你喜不喜欢知乎,我都建议你再好好读读 如何看待女权主义者在 Steam 坎巴拉太空计划社区中心发表的这番反歧视言论? 这篇回答。
-
在学习 Rails 之后,有点想法想和大家分享一下 at 2017年07月07日
Linus 批评的是自以为是的人,他批评的问题和指出的那一行都代码质量没关系。我不攻击你原帖的观点,我直译了 Linus 的文字,指出了他的观点,你一不去求证,二你声称英文不好并在我指出你误读了他的文字的前提下仍坚持错误的理解,这就叫自以为是,并且,你不虚心。
没有,或者你觉得我有,那请你举证。
开源精神就是“你行你上”,你自己没做过什么事而挺爱指指点点,想必 Linus 的经典言论“Talk is cheap,show me the code”你一定听过。此外,不谈我为中国 Rails 社区的贡献,你学的 Rails 里就有我的代码,我写过的 Gem 应用在很多公司的很多系统里,涉及现金流水数千万,你跟我谈开源精神?对,我这句在装逼。不要去教专业厨师应该怎么做饭,“键盘大厨”讽刺的就是这种人。
我还有很多人从各种角度讲明了你的观点不妥,我的观点和你的相悖,所以我就是在反对你的观点。你抛出观点,还不能允许别人反对了?
再重温一遍我引用的来自知乎的那段话
我的观点是:己所不欲,勿施于人;以身作则;尽力而为
你反感知乎,而我引用的是某人的文字。难道你认为这句话是他发表在知乎上的,所以他的话对你而言就是被讨厌的?
-
在学习 Rails 之后,有点想法想和大家分享一下 at 2017年07月07日
再次重申,没有喷代码,不信你自己去翻译。
再次重申,没有喷代码,不信你自己去翻译。
再次重申,没有喷代码,不信你自己去翻译。
-
在学习 Rails 之后,有点想法想和大家分享一下 at 2017年07月07日
另外我不知道你英语不好,你我完全不相识,而是当我看到你完全误读了 Linus 的话,让我知道你可能英文不是很好。
-
在学习 Rails 之后,有点想法想和大家分享一下 at 2017年07月07日
本来我是不想说啥的,但既然你崇拜 Linus,我就把 Linus 的观点分享给你,并且,我告诉你 Linus 恰好批评你的观点,我不知道你会怎么想。
如果你说我欺负你英文不好,那你大可亲自去了解清楚我刚发的截图的讨论过程,然后用实证说出来:我欺负你了,我不友善。
无论怎样,我还是要引用我引用的知乎某个回答的一段话:
她一方面强迫他人去理解和接受她的"世界“,一方面又关闭了交流的门,想想看她应该把“己所不欲,勿施于人”理解为单方面让别人去适应自己,而并没有尊重别人的想法,反而认为别人如果想法跟她不一样,就是别人的不对。
-
在学习 Rails 之后,有点想法想和大家分享一下 at 2017年07月07日
我就是把截图里的 linus 的回复,直接翻译成中文而已,不信你自己敲到 google translate 里看看
-
在学习 Rails 之后,有点想法想和大家分享一下 at 2017年07月07日
你自己把截图里那段话,放到翻译软件里看看他在批评什么。
-
在学习 Rails 之后,有点想法想和大家分享一下 at 2017年07月07日
何况你这样说是伤害到很多一直热心社区人的心的,我们解答问题,分析知识,封装 gem,现在有个人跳出来,我觉得你们对新手不友好。
你说一直在做这件事的人什么感受?我们在做这事的时候,你在做什么?你凭什么这么说?
-
在学习 Rails 之后,有点想法想和大家分享一下 at 2017年07月07日
何况 Linus 另一句经典名言了:Talk is cheap, show me the code.
与其指挥大伙你们应该怎样,不妨身体力行,用自己的行动鼓舞大家加入到你的事业,亲自帮助到一些人,让别人在其他人面前说出:这个人,感谢他。
你帮助到的人有几个捡起你的衣钵,薪火就传下去了,这是一笔投资。你可以看到,慈善的逻辑,就是这样。
-
在学习 Rails 之后,有点想法想和大家分享一下 at 2017年07月07日
你的英语不太过关,linus 说的跟代码没有关系
-
在学习 Rails 之后,有点想法想和大家分享一下 at 2017年07月07日
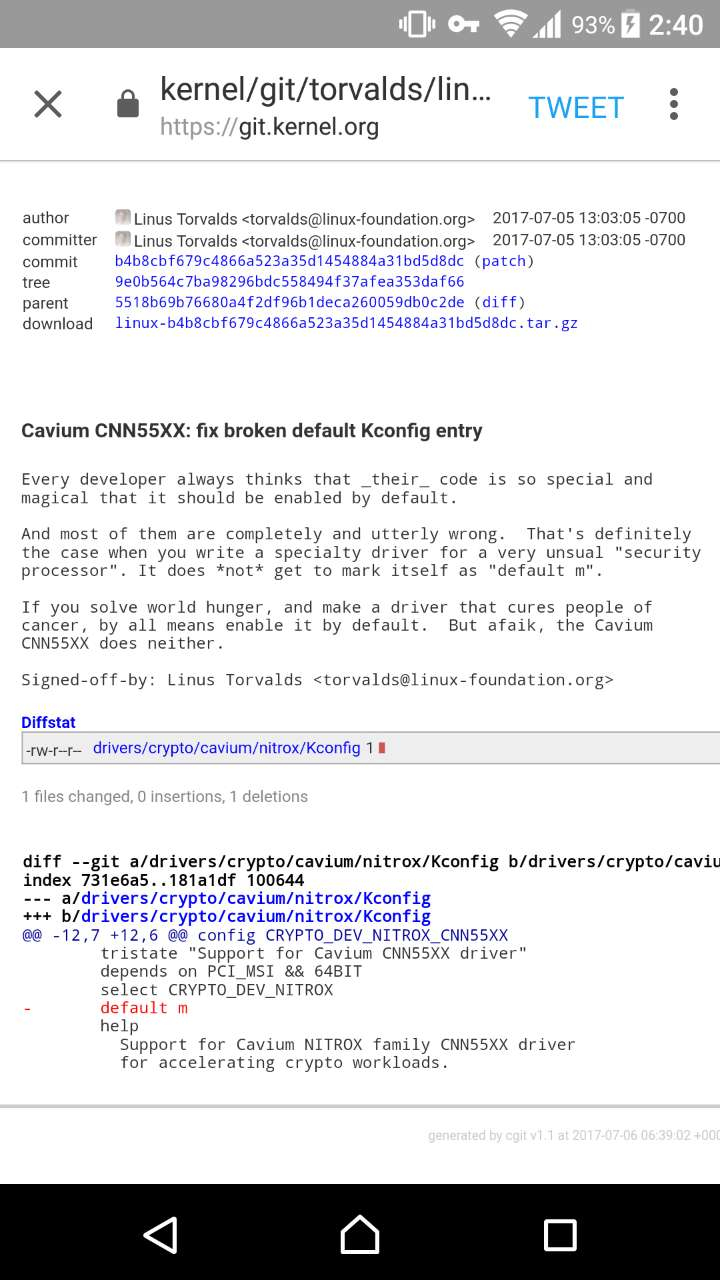
他吐槽的是 default m 那一句啊,意思是提交者希望默认启动他的驱动。
直接翻译 Linus 的话:
每个开发者都认为他们的代码是特别的、精巧的以致于应该被默认启用。
但抱有这想法的大多数人都是完全的彻底的错了。
我想引申一下:
每个人都觉得自己的想法或者建议是有益的、可行的以致于大家应该听从。
但抱有这想法的大多数人都是完全的彻底的错了。
-
在学习 Rails 之后,有点想法想和大家分享一下 at 2017年07月07日
然而 linus 大神刚怼了楼主的想法...
-
在学习 Rails 之后,有点想法想和大家分享一下 at 2017年07月07日
-
yarn 可以替代过去把前端的依赖放到 vendor 的作用
-
招聘 [Freewheel] 软件工程师 (后台 C++/ 算法 / 全栈 / 后端 / java 开发 / 大数据) 美资互联网 / 美国轮岗机会 / 免费午餐 / 夏季周五下午 3 点就下班哦 at 2017年07月07日
支持一下!