-
Redux 里面如何正确的设计 reducer? at April 22, 2016
简单的说,在 action creator 里面 dispatch 其他的 action 去触发额外的状态变更。这需要 action creator 不止返回一个 object,Redux 的 thunk 和 promise 等 middleware 都支持这种做法。说的比较抽象,不过跟 @nightire 说的是一个意思。
-
npm 没有 Gemfile.lock 这样的机制,怎么想的? at April 21, 2016
@mizuhashi 我不知道有没有明白你的意思。如果你说的“resolve 结果可重现“是说”每个人 npm install 后的结果都是一样的“ 。那 npm 没法做到。甚至你把自己项目的 node_modules 删了再 npm install 都不一定完全一样。npm v3 里是安装顺序决定了那个包是平铺还是嵌套的。如果要完全可重现,除非锁定每个包的版本号并单独记录,就像 Bundler 的 Gemfile.lock 那样。
我的主要意思是:应该关注直接依赖的包有没有破坏项目的稳定性。而不需要关心 npm install 后的 node_modules 结构是不是一样的,也不用关心安装的包到底是平铺还是嵌套的。在我看来 npm + semver 可以做到这一点,所以我甚至不去折腾 shrinkwrap。举个例子,我不关心 A 的版本是 1.1.0 还是 1.9.3,只要它的行为没有改变就行。锁定版本号当然可以保证 A 的行为始终是一致的,但这不是唯一的方法。
-
Python 的函数式编程--从入门到⎡放弃⎦ at April 20, 2016
下回谁得写个:JavaScript 从嫌弃到唾弃

-
npm 没有 Gemfile.lock 这样的机制,怎么想的? at April 20, 2016
作为一个专业 Ruby 开发者和半吊子 JavaScript 开发者说几句。
第一次用 npm 的时候我也被惊到了,不是因为太好用,而是因为庞大的 node_modules 目录和层层嵌套的包。当时很多包都依赖一些基础库,比如 underscore,然后我自己的项目也需要 underscore,于是很无语的看到 node_modules 变成这个样子:
underscore `--- dependencies A `--- underscore `--- dependencies这种情况 underscore 显然被重复安装了。而且如果碰到一个依赖众多的基础库,那它下面的依赖也都重复了…… 我当时就想你个二货怎么不学 Bundler 一样展平依赖呢?
直到后来更加了解 JS 的一些模块加载,我才突然想通了。其实这样做的一大好处是“你不用管你安装的包还有哪些依赖”。
我想很多 Rubyist 都碰到过这样一种事情:你的项目本身和安装的一个 gem A 都依赖 gem B。Gemfile 大概像这样:
gem 'A' # has dependency B gem 'B'有天 B 升级了并提供了一些新特性,你想在项目中使用新版的 B。这时你就得确保 A 也能够使用新版的 B,否则就不能升级,Bundler 会提示你 A 依赖的 B 跟你的项目依赖的 B 版本有冲突。你只能使用 A 能够允许的最高版本的 B ,然后也许你就被迫升级 A 去了。如果恰好 A 那时已经没人维护了。你就有更多的事情做了,要么 fork 一个 A 自己维护,要么把你需要的功能抽出来然后 kill your dependency。
其实很多时候,我们需要的不是 锁定项目的每个直接或间接依赖的包的版本 ,而是 保证我们的项目的直接依赖的包接口和行为都是稳定的 。就我的理解,前者是方法,后者是目标。如果做到了前者,后者肯定能做到,但反过来是不成立的。达到目标的方法不止一种。
Bundler 和 npm 其实都是为了后者服务的。但 Bundler 选择的方式是前者(锁定所有包的版本)。这除了处理问题的哲学不同,也跟 Ruby 和 JavaScript 的运行方式有一定关系。
在 Ruby 中,一旦
require一个模块,那这个模块就存在于全局命名空间中。因此 Ruby 的世界里几乎不可能在一个项目里使用两个包的不同版本(比如 A 1.0.0 和 A 2.0.0),因为它们的很多模块名都是相同的。在这种情况下,一个 Ruby 项目的所有包,不管是直接还是间接依赖,都只允许出现一次,并且还不能有模块重名(这也是为什么每个包都会有命名空间封装一下)。这点不管用不用 Bundler 都一样。只是 Bundler 加上了锁定每个包版本的功能。至于这是不是 Ruby 世界最好的处理方式就见仁见智了。我觉得锁定版本已经是一个很好的方式了。而 JavaScript 的模块设计都是局部可用的。你在模块 a 中导入另一个模块 b,那 b 就只在 a 中有效,b 也不会被注册到全局命名空间中。这让每个模块有自己独立的依赖成为可能,只要它们从不同的地方去 require 就行了。基于此 npm 的逻辑就是每个包都应该有它自己的依赖,这可以让使用者只关心项目的直接依赖,忽略间接依赖。在达到这个目标的前提下,能共用一些包就共用,不能用就算了。
了解这一点后再来看 npm v2 的处理方式就可以理解了。这货根本没关心包共用和省空间的问题,安装时就是简单粗暴的不断嵌套。npm v3 弄成安装时尽量平铺,需要一个包不同版本就嵌套的方式,我觉得除了 windows 目录层数限制的问题(who care),另一个好处就是可以某种程度上避免空间浪费(重复安装同一个版本的包)。但不管是 v2 还是 v3,他们的核心哲学都是没有变的。
要我说 Bundler 和 npm,它们没有孰优孰劣,只是在各自的平台下做着自己认为对的事 。但我觉得身为开发者是不能被某个平台的设计方式局限的。拿一个的经验当标尺去评价另一个,就像 Windows 用户吐槽 Mac(反过来也是)一样,比较没道理。
最后说一个不锁定版本带来的担忧。我开始也担忧不锁定版本会不会导致我装的包跟别人不一样?其实仔细想想, 我担心的是不同版本的包改变了行为,导致一些不可预知的错误 。这点 npm 用 semver 解决的。semver 规定所有破坏性更新都必须改 major version。而默认加入 package.json 里的包都是锁定 major version 的。如果你依赖的包都是守法公民,那应该是不会出问题的。如果你发现出问题了,那就跟 @nightire 说的一样,当 contributor 的机会来了。
最最后说一句,因为间接依赖的被锁住导致整个系统难以升级,也属于 dependency hell 的一种。我对此是深以为然。这个说法貌似是在 Wikipedia 上查到的,如果不对欢迎指正。
-
使用 Upstart + Inspeqtor 管理你的 Sidekiq (监控、崩溃自动重启、邮件通知) at April 18, 2016
+1
-
如何独立开启 Ruby WebServer, 访问静态目录 at April 15, 2016
不止 Ruby,很多语言都有简单启动 server 的方法。Google 一下 one line server。或者看 这个链接
-
是否可以用 AWS 或者阿里云的消息队列来控制并发?还是应该用 Sidekiq? at April 14, 2016
用
concurrency来设置并发数就行了。我一般不设置优先级。Sidekiq 其实是穷人版本的消息队列,个人理解。 -
美亚购买技术图书能否直邮? at April 10, 2016
可以直邮。但运费较贵,貌似达到一定的价格可以免运费。这个得你自己去官网看看了。我只在上面买过一次,是因为那书太老了只有纸质版才买的。
-
关于 Ember 里的模板 at April 05, 2016
toy project 就写页面里,估计你说的是是写
<script>标签里那种。正式项目不管大小,模板预编译成 JS 文件,当做静态资源加载。Handlebars template 本质上是 JS 函数。 -
程序员健身 App 有木有需求? at March 27, 2016
不是打击楼主,但不是所有问题都能用/需要用程序去解决
-
如何将数组转换为 ActiveRecord_Relation 类型呢? at March 26, 2016
为什么要把数组转换成 ActiveRecord_Relation 呢?我感觉这应该不是楼主原本需要解决的问题。如果说出你原本的需求,也许会有其他的方法。
-
有什么轻量级的并发框架推荐吗? at March 26, 2016
同样推荐 concurrent-ruby。并发 HTTP 请求的情况属于 Ruby 内部进行 IO 操作,这种情况不会触发 GIL。你可以看看 concurrent-ruby 里面的 Future 和 Workflow,方便组织代码。不过如果要做一些限制(比如最多并发 10 条 HTTP 请求)那就要再想想了,也许需要用到 ThreadPool。
-
做项目经常要找图标么?用 IconJar 来管理吧 at March 23, 2016
+1,也分享一个我用的 https://icomoon.io/ 。可以自己组合不同 icon 库的图标字体然后打包。免费版的够用,搜索也比较方便(有一定的容错率)。
-
RSpec 如何更好的测试 call method at March 17, 2016
首先如果只论如何用 mock 解决这个问题,那也就只能 mock
User.find了。mock 就是要模拟程序行为。楼主却想 mock 一半再绕过去,思路有些奇怪。就测试本身而言,controller 测试因为承上启下的特殊性,更适合用来测试结果而不是过程。我看楼主在上面几楼反复强调
block_user!在其他地方已经测到了,感觉楼主并没有完全理解测试的关注点。就你的例子而言,我对 model 和 controller 测试的看法:- model 更偏单元测试,需要关注边界条件。比如 user 不能 block 他自己。
- controller 更偏集成测试,假设每个组件都工作正常的情况下,程序整体行为是否正确。你没必要在 controller 里穷举
User#block_user!的所有可能情况,因为单元测试已经保证了这一点。
最后,我不怎么写 controller 测试,因为大部分情况下我都用 service object 封装业务逻辑,然后对 service object 写单元测试去了。实际行为我用 request 测试去保证(API 项目)。
-
我是来认真吐槽 “英语流利说” 这家公司的电话面试的 at March 17, 2016
好奇翻了一下 @tony612 的信息,然后找到博客翻了翻…… 我觉得能连续做 125 天 contribution 的人技术和态度都不会差。
-
同构化的 React + Redux 服务端渲染 at March 16, 2016
赞一个!这个得慢慢看,里面我不懂的太多了…… 早上看了一下 Redux 的文档,思路和行文都非常好,很久没有文档看的这么带劲了。
-
如何劝说别人使用英文资料? at March 14, 2016
让我想到一个梗,这年头 程序 = 搜索引擎 + 英语
-
JavaScript ASI 机制详解 at March 08, 2016
-
JavaScript ASI 机制详解 at March 08, 2016
@nightire 赞同。我现在比较喜欢多行
var时把逗号放前面,但 object 和 array 把逗号放后面。都是为了你说的原因。不过这种风格不太一致,ESLint 中貌似只能允许 comma first 或者 last。你有类似经验么? -
RanSack 怎么处理英文下划线的 at March 07, 2016
@u1453357893 @easonlovewan 估计跟版本有关,这个方法是 4.2.1 加入的,在
ActiveRecord::Sanitization::ClassMethods里面。 -
JavaScript ASI 机制详解 at March 07, 2016
@billy 其实我也是,只是我改的是
semi规则 -
JavaScript ASI 机制详解 at March 07, 2016
@nightire ESLint 只有非常少数的配置是跟分号风格相关的,
semi,no-unexpected-multiline,no-unreachable这三项配置就可以避免很多错误了。其实最开始我打算把风格问题放进来写,不过写着写着发现 ASI 的部分太多了,而且风格问题属于个人偏好。所以才打算分开写,这篇就是不带个人意见的 ECMAScript 标准分析。
-
RanSack 怎么处理英文下划线的 at March 06, 2016
这是个被低估的问题。
_是 SQL like 的通配符,Rails(包括 Sequeel 和 Ransack)默认不做处理,但提供了你一个方法sanitize_sql_like自己转换。sanitize_sql_like(string, escape_character = "\") Sanitizes a string so that it is safe to use within an SQL LIKE statement. This method uses escape_character to escape all occurrences of “", ”_“ and ”%“
q = User.sanitize_sql_like("_") User.where("username like ?", "%#{q}%") -
Ruby 处理 PDF 的开源项目大家有了解么? at March 04, 2016
Prawn 足够强大了。
-
服务器上的周期性任务大家都习惯用什么来实现呢? at February 24, 2016
固定周期的用 crontab。如果”周期性“涉及到可编程逻辑(比如按不同 company 的本地时区来周期性计算)我还是用 background job 去处理。如果必须要用 Sidekiq 做周期性任务的话,sidetiq (不是 sidekiq) 这个 gem 可以看看。
-
Rails 用 RJS 简单有效的实现页面局部刷新 at February 23, 2016
@optionsource 也许没表达清楚,就是建一个匿名函数表达式去封装一下:
(function() { // Your code })(); -
Rails 用 RJS 简单有效的实现页面局部刷新 at February 22, 2016
@huacnlee js.erb 里的脚本是直接 eval 跑的,所以里面声明的变量会变成 全局变量 ,所以任何 js.erb 最好加上闭包。CoffeeScript 貌似不用管这个问题,因为默认生成的 JavaScript 就是有闭包的。
-
Ruby China 官方 iOS 客户端已发布上线 at February 15, 2016
-
Ruby China 官方 iOS 客户端已发布上线 at February 05, 2016
漂亮,去下一个试试。
-
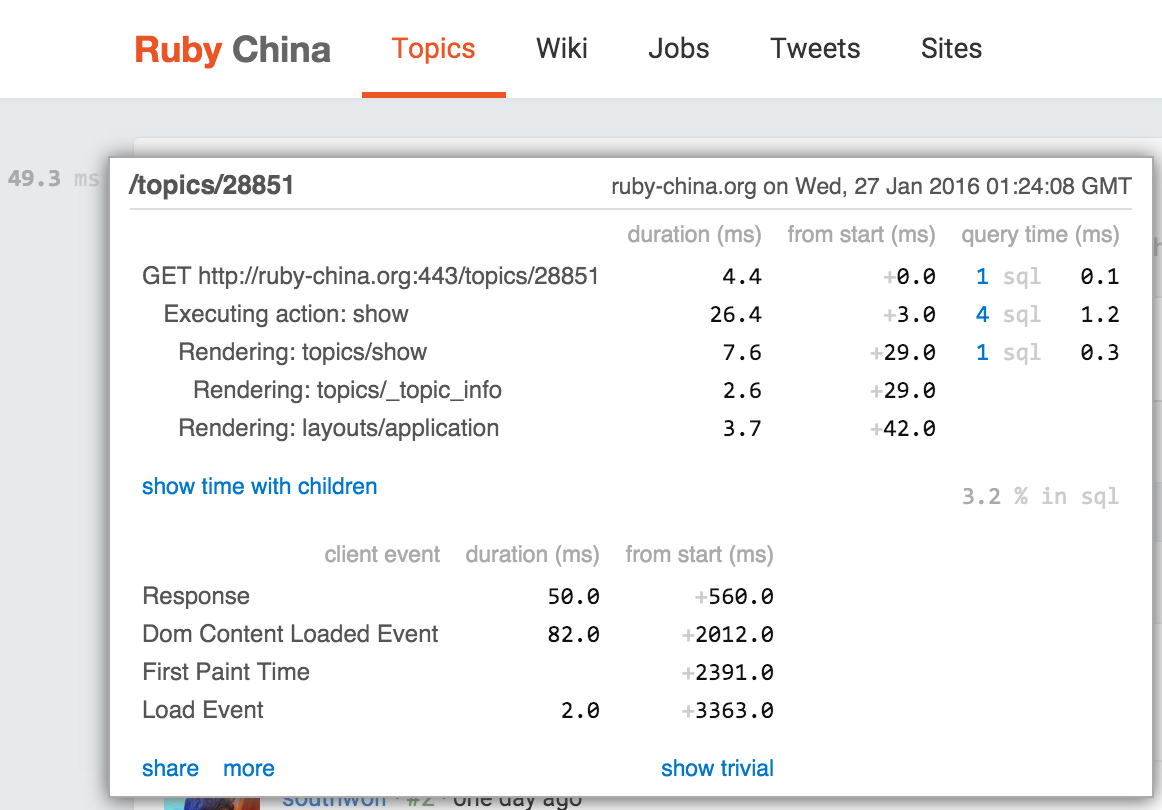
PG 上线升级修好啦! at January 27, 2016
@huacnlee 左边的 profiler 忘了在 production 下关了?