-
Google Code 今日起将逐步关停服务 at 2015年03月13日
-
我喜欢酱紫的 Hash at 2015年03月13日
-
[转王垠] 怎样尊重一个程序员 at 2015年03月13日
虽然王垠的一些观点、言论和行为我不是十分认同,但是我依然认为他是个值得尊重的人。
-
Google Code 今日起将逐步关停服务 at 2015年03月13日
-
我喜欢酱紫的 Hash at 2015年03月12日
-
"中级 Ruby 工程师"都在做什么? at 2015年03月12日
-
为支持移动端离线模式-数据库采用 UUID 字段 at 2015年03月12日
-
为支持移动端离线模式-数据库采用 UUID 字段 at 2015年03月12日
看完楼主的描述,在这里 UUID 只起了一个作用,就是创建失败的时候删除本地数据。如果只是这样的话,大可不必把 UUID 作为一个字段保存到服务器啊。API 异步调用的时候把手机生成的 UUID 传到服务器,服务器创建成功之后返回请求时的 UUID 和新的 task 的 ID,这样手机就知道 taks 创建成功了,之后就可以用 task 的 ID 来进行查询、修改和删除的操作了。如果服务器超时或者返回失败,那么服务器和手机都可以将新创建的 task 删除。
-
我喜欢酱紫的 Hash at 2015年03月12日
-
新版 MacBook 完全没风扇了 at 2015年03月10日
屏幕不够大,拿来编程还是差点感觉。不过带着去爬山、徒步、旅游倒是很理想,不累赘,兴致来了也可以拿出来逛逛论坛或者写几行代码意思一下。
-
慎用 mongoid_auto_increment_id 这个 Gem at 2015年03月10日
-
慎用 mongoid_auto_increment_id 这个 Gem at 2015年03月10日
你列出来的目的,其实完全可以用另外一个字段(比如说 auto_id)来实现。由于并非每个 Collection 都需要自增 id,所以将自增 id 作为一个可选字段来添加到 Model 的定义,而不是缺省所有 Model 都采用自增 id 作为主键,是一个更加有灵活性和科学的做法。
其实这些需求并非是关键需求。非关键需求的特性,就是缺少的时候不会影响整个系统的运行,而过后又可以通过后台程序再次生成补上。而主键是一个关键字段,是表之间关系的连接点,如果生成错误或者不能生成,将很可能会造成整个系统瘫痪。
因此我依然认为通常情况下缺省应该采用 ObjectId 作为主键。
-
如何在服务器上启动或重启 Puma 服务 at 2015年03月08日
-
MySQL 用 UUID 作为主键,实际使用中有什么问题 at 2015年03月07日
-
MySQL 用 UUID 作为主键,实际使用中有什么问题 at 2015年03月07日
我的理解,UUID 的优势就是天然适应高并发的环境下使用。如果 id 顺序递增,每创建一条记录都需要对表加一次锁,这在高并发环境下是很大的开销,有时候甚至是不能容忍的。
-
成为一名初级 / 中级 Ruby on Rails 程序员应该具备怎样的技能树 at 2015年03月06日
-
如何在服务器上启动或重启 Puma 服务 at 2015年03月06日
-
如何在服务器上启动或重启 Puma 服务 at 2015年03月06日
装了 puma 之后,有 pumactl 这个程序
-
成为一名初级 / 中级 Ruby on Rails 程序员应该具备怎样的技能树 at 2015年03月06日
个人推荐的路线是: 数据结构》算法》操作系统》数据库》Ruby》Rails》TDD》下面自由发挥
不过这个过程对于没有计算机技术基础的人来说需要有点耐心,但是一旦走下去你的水平会提供很快,而且工作起来会更靠谱一些。
-
如何限制文章的评论个数? at 2015年03月06日
楼主的代码存在以下问题:
- Article 类不应该做有关评论个数的 validation,因为 Article 类的对象在创建的时候并不知道底下有多少 comment
- Comment 类可以做这种 validation,只是不应该用 callback 的形式,而是应该用自定义 validation 的形式。
下面是我帮你改过后的代码:
class Article < ActiveRecord::Base has_many :comments end class Comment < ActiveRecord::Base belongs_to :article validate :validate_comments_length_of_article private def validate_comments_length_of_article if article.comments.length > 2 errors.add(:base, "文章最多有3个评论") end end end最后提醒一下,即便是做了这种 validation,也不能保证所有 Article 底下的 Comment 就不会超过 3 个。因为在并发的环境下,有可能 N 个请求同时满足 validation 的条件,但是结果就是同时生成了 N 条评论。N>3 的情况下,就无法得到楼主所期望的效果了。
-
如何解决测试代码重复的问题? at 2015年03月05日
-
如何解决测试代码重复的问题? at 2015年03月05日
#11 楼 @lolychee 明白了。RSpec 有 shared_examples 和 shared_context 这两种工具来解决类似的问题,之前一直都没有留意到。我再继续研究一下。谢谢!
-
如何解决测试代码重复的问题? at 2015年03月05日
#8 楼 @Rei 其实就相当于是 helper 吧。我感觉就干脆提取出来放到一个 helper 文件里面更方便。只是有个问题,还是上面提到的两句话:
expect(response).to be_success expect(request.flash[:error]).to be_blank如果写成一个函数:
def test_if_success expect(response).to be_success expect(request.flash[:error]).to be_blank end那么其中的 response 和 request 是否也要用参数传入呢?这样就不是很方便了。如果避免传参数,那写法是否就应该改为:
def test_if_success eval <<CODE_BLOCK expect(response).to be_success expect(request.flash[:error]).to be_blank CODE_BLOCK end -
如何解决测试代码重复的问题? at 2015年03月05日
#3 楼 @MrPasserby 你说的也是一种情况。我的理解就是,不可能所有排列组合都列举一遍,所以有时候的确是需要偷点懒,只要关键逻辑走通就可以了,其他实现逻辑一样的只测一个例子就可以了。
-
如何解决测试代码重复的问题? at 2015年03月05日
#2 楼 @Rei 不好意思,我偷懒了。具体的例子可以看一下我在 OGX 社区 的代码 https://github.com/ogx-io/ogx-io-web 里面的例子(由于代码太长就只发链接了):
在这个例子当中,判断成功的代码有很多地方都是这么两句话:
expect(response).to be_success expect(request.flash[:error]).to be_blank而且,在一个 describe 底下,两个 context 可能只是测试对象的类型不同,而测试的内容都是一样的,但测试的预期结果也会有所不同。如果能够把这些情况归纳成一种模板的话,我觉得是不是测试的代码就能够减少很多,而且看起来也更加清晰易懂呢?
不知道我说清楚问题了没有?
-
如何解决测试代码重复的问题? at 2015年03月05日
#1 楼 @spacewander 你说的我也想过,但是好像没有可以参考的代码。看了一些开源的项目,发现还没有比较系统的做法。
-
OGX 社区 开发计划 2015-2 at 2015年02月03日
今天完成了板块分类和收藏功能。添加了板块分类之后,板块列表变成了带子分类的形式了。另外还把左侧的所有板块改为收藏板块。如下图:
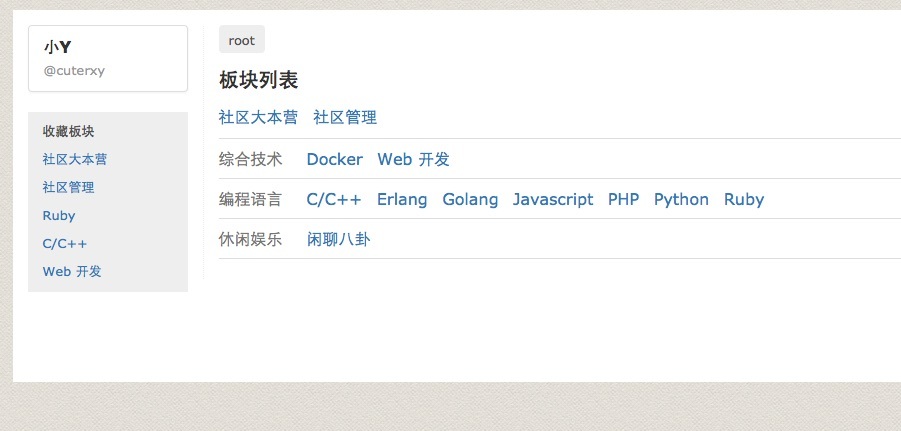
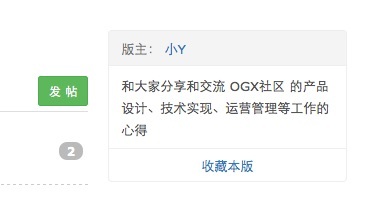
收藏板块的链接就板块页面右侧,如下图:
-
Ting 一个用 Semantic-UI 写的音乐社交网站 at 2015年02月02日
真不错,UI 做得很漂亮啊!
-
大家 MySQL 如何存储 emoji 的? at 2015年02月02日
看来还是 mongodb 好啊