-
Rails 5.2.2 jQuery 用不了? at 2019年03月14日
-
你弄清楚这个请求是服务器发送的还是用户浏览器发送的。
我猜这是服务器发送的,只能用 format.html,你的 respond_to if true 路径上没有处理这个类型。
-
第三方的 post 请求,应该是后台调用吧?不是用户请求,不需要 redirect 到用户的页面。
如果是用户跳转回网站应该是 get 请求。
-
所以你要考虑 funds_user_path 这个 action 需不需要 logged_in_user?如果需要的话第三方如何处理。
-
是不是 funds_user_path 又触发了 logged_in_user filter
-
升级 ruby 的 gem 环境问题 at 2019年03月09日
我没这样弄过,不清楚了。
-
升级 ruby 的 gem 环境问题 at 2019年03月09日
ruby 2.6 默认带 bundler。
-
Ruby China 非官方 HTML5 应用发布 at 2019年03月08日
非 Ruby China 提供
-
添加字段后,启动,本地跑起来一点问题都没有,,放到线上发布后就报错 at 2019年03月06日
没环境调试不知道问题在哪。提醒一下 ActiveRecord 自带 enum https://api.rubyonrails.org/v5.2.2/classes/ActiveRecord/Enum.html
-
ruby 中 MD5 加密返回的字符串是 32 位的,怎么返回 16 位的? at 2019年03月05日
Digest::MD5.digest str
-
ruby 入门难道比 php 入门难道更高么 at 2019年02月28日
小马过河。
-
SimpleAPM - Rails 慢事务追踪 at 2019年02月26日
之前觉得做个开源 APM 系统挺有前途的,然后发现 Elastic 做了…… https://www.elastic.co/solutions/apm
-
大家在 Rails 的基础上是怎么进一步提升开发效率的? at 2019年02月22日
楼主都还没开始讨论就引用了 Anti TDD 的资料,就是说楼主已经意识到自己问题在哪里了?
-
一个多年 Linux 用户的 Mac 使用体验 at 2019年02月21日
感觉楼主舍不得自己的多年 Linux 用户经验,对 Mac 带着抗拒心理,总是想找点瑕疵。完美的设备是不存在的,用 Mac 一个理由就够了:不折腾。
我也是多年 Linux 用户,转 Mac 后马上就适应了。我不是 Linux 系统开发,精力应该放在自己工作的领域。
-
数组变量重新接受赋值后 object_id 改变 at 2019年02月16日
a[1] = b[0] -
缩减 Docker 镜像体积历程总结 at 2019年02月06日
一个小项目用 ubuntu 的镜像打包出来也是 500+MB,alpine 把依赖安装全估计体积差不多。
看了下,ubuntu 18.04 基础镜像是 86.2MB。
-
用 Sonic Pi 演奏东热片头曲 at 2019年01月29日
有在线执行的地方么?或者录个视频也好。

-
Rails Production Log 有什么方便 check 的方法吗? at 2019年01月26日
搞套 ELK https://www.elastic.co/cn/elk-stack ,自建或云服务。
-
GitHub 可以免费创建私有仓库了 at 2019年01月26日

-
GitHub 可以免费创建私有仓库了 at 2019年01月26日
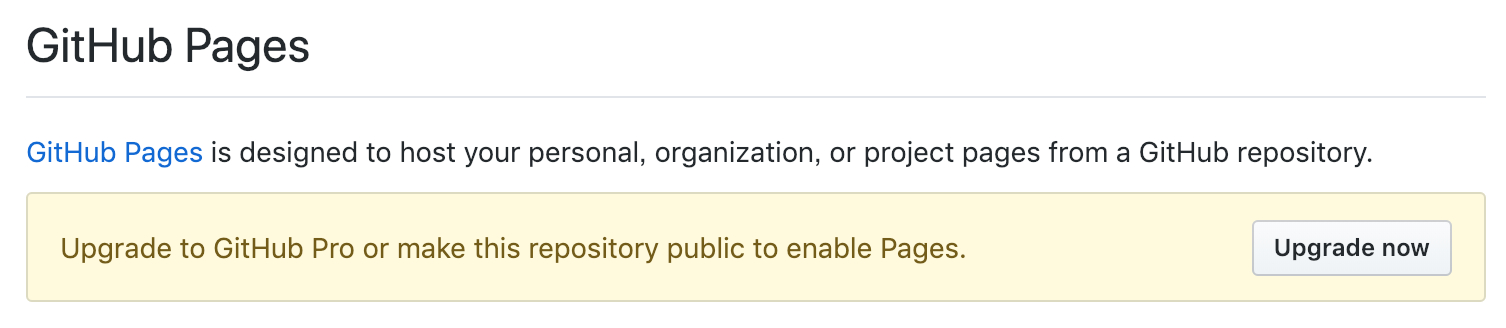
注意了,免费版的私有库没有 GitHub Pages,害我博客挂了一个月。
-
前后端分裂 at 2019年01月26日
我靠,博客挂了一个月我没发现,已经修复。
-
如何在 win2003 或 xp 上安装 ruby (>= 2.3) at 2019年01月25日
今年 2019 年……
-
这种喷子为什么不 Ban 不删? at 2019年01月16日
楼主十三楼也有问题,用词挑衅,不符合社区氛围,结果就是自己也添堵算是惩罚。
-
这种喷子为什么不 Ban 不删? at 2019年01月16日
脏话贴已删,已记录,再犯会封号。
-
ActiveStorage 的 Log 好长啊,看着好难受 at 2019年01月13日
我发现它跟一些 CDN 配合不好,打算某个项目换回 carrierwave 了。
要用 ActiveStorage 有些坑应该绕过:
- 从性能考虑,头像这类不需要保护的地址应该直接用 CDN 地址不需要跳转。
- 文章内嵌附件的地址要用自己的跳转地址,例如 /attachments/:id/download,默认的跳转地址在更改 secret_key 之后会失效。
Basecamp 自己就是这么做的,但是 ActiveStorage 却没有默认提供!
-
GitHub 可以免费创建私有仓库了 at 2019年01月08日
已降级。