-
[上海] 扎实发展的众筹网站 dreamchina.com 招聘 ruby 程序员 at December 25, 2013
-
Merry Christmas 皆さん at December 25, 2013
@KoALa 从 github 关联看是真的!
-
Merry Christmas 皆さん at December 25, 2013
2 楼竟然是 Matz
@yukihiro_matz メリークリスマス
-
Rails 项目维护数据库,偏向于使用 ActiveRecord::Migration or 数据库脚本? at December 12, 2013
auto migration
-
数据库表关系问题 at December 09, 2013
对文档数据库认识不深的话,更不建议用了,如果是刚刚开始的项目,换关系数据库得了
-
数据库表关系问题 at December 09, 2013
@dxwts 隐约感觉你用 mongodb 做这个网站是选型错误。。。不过你可以参考下下面的几个文章怎么做:
http://mongomapper.com/documentation/plugins/associations.html
http://mongoid.org/en/mongoid/docs/relations.html
当然如果是 mongodb 的话,这样子的实现也不一定是最佳实现,可能是把价格信息保存在 product 表里更合适些 http://ruby-china.org/topics/15720
-
数据库表关系问题 at December 09, 2013
嗯,再就是 has_many, has_many through 了
-
数据库表关系问题 at December 09, 2013
上面的例子最好加一个(商品 ID)+(供应商 ID)的唯一性校验
-
数据库表关系问题 at December 09, 2013
还应该是上面的结构,我给你举个例子吧:
商品表: thinkpad x1, Macbook Air 供应商表: 京东, 一号店, 苏宁 商品-供应商表: (商品ID),(供应商ID),(价格)。。。 thinkpad x1, 京东, 10000 thinkpad x1, 一号店, 11000 thinkpad x1, 苏宁, 12000 Macbook Air, 京东, 1 Macbook Air, 一号店, 2 Macbook Air, 苏宁, 3 -
数据库表关系问题 at December 09, 2013
product, manufacture, product_manufacture (多对多,保存 price)
-
用 Go 写了个类似 ActiveRecord 的 ORM 库, gorm at December 08, 2013
Go 里面那个 db 支持 connection pool 吗?
支持
还有那个 db.where 在 go 里面 能实现比如 user.where 这样的吗?
在 Go 里不能 Hack 其它的库,所以不能实现这种方法,不过你可以自己填加一下,也很简单。
不过我感觉在使用 db.where 以后,感觉还不错,特别对于使用不同的数据库来查询不同的数据的程序来说,挺方便的,例如你可以建议一个 db1,db2
-
Go's Reflect at December 06, 2013
package main import ( "fmt" "reflect" ) type Type1 struct { A int } type Type2 struct { *Type1 } func setValue(v interface{}) { value := reflect.ValueOf(v) field := value.Elem().FieldByName("Type1") t := &Type1{123456789} field.Set(reflect.ValueOf(t)) } func main() { t := Type2{} setValue(&t) fmt.Println(t.A) } -
用 Arch linux 的进来看看,最近更新系统你们遇到过这个问题没有?[更新,解决方案] at December 01, 2013
用了 manjaro 后,一切就清静了 ;)
-
Sam Stephenson 告诉你为什么要使用 CoffeeScript at November 24, 2013
我用 CoffeeScript 重写了我的 vrome 插件后,然后速度变慢了些,特别一些 js 处理很多的地方。。。不过写起来很爽的
-
git pull 和 git fetch 有什么区别? at November 23, 2013
解决的问题不是这里写了么:
* rename `branch1` to `branch2` $ grb mv [branch1] [branch2] [--explain] * rename current branch to `branch` $ grb mv branch [--explain] * add a remote repo $ grb remote_add `name` `repo path` [--explain] * remove a remote repo $ grb remote_rm `name` [--explain] * delete branch `branch`,default current_branch $ grb rm [branch] [--explain] * pull branch `branch`,default current_branch $ grb pull [branch] [--explain] * push branch `branch`, default current_branch $ grb push [branch] [--explain] * create new branch `branch` $ grb new [branch] [--explain] * prune dead remote branches $ grb prune// repo 的简介是 A tool to simplify working with remote branches, 但是 rm 操作还会删除本地的分支,会否有歧义?
第一次用最好用
--explain看看会做什么,熟悉以后就很方便了// 同时还发现个小问题,如果在 master 上进行 rm master 操作,最后的 branch -d 会有问题吧
明知删除当前所在分支有问题,就用
grb remote_rm master么,或者换个本地分支 ;) -
git pull 和 git fetch 有什么区别? at November 23, 2013
学这么多还不如用 grb .... https://github.com/jinzhu/grb
-
为什么你应该永不用 MongoDB (转) at November 22, 2013
@zgm 嗯,我了解一些,上面也提过,例如可以搜索之类的。但有得有失,只能是在各种对比后的取舍。
-
为什么你应该永不用 MongoDB (转) at November 22, 2013
@jarorwar 纯技术探讨。。。。。又没有人会一直全对。。。
-
为什么你应该永不用 MongoDB (转) at November 22, 2013
@jarorwar mysql 存序列化后的 json 就可以了么,只是这些动态增加的字段搜索可能是个问题,但如果你想搜索的时候,就在跑程序的时候动态的用 sql 增加一个字段呗,然后赋值到这个字段就好了,也很简单。
你可以用 mongodb 加字段,又没有法律规定你用关系型数据库不可以。
-
为什么你应该永不用 MongoDB (转) at November 22, 2013
@jarorwar 例如?
-
为什么你应该永不用 MongoDB (转) at November 22, 2013
@jarorwar 嗯,不过等冗余变的太多的时候,维护冗余的逻辑会遍地都是。。。然后会出现各种莫名的 bug,因为冗余忘记更新了。。。
mongodb 看似比 SQL 简单,但和封装 SQL 的 ORM 相比,还是有些差距,因此还不如挑个好的 ORM 用呢
-
为什么你应该永不用 MongoDB (转) at November 22, 2013
@jarorwar 加冗余简单,维护难。。。
-
[美国] 大家也可以考虑下国外 at November 20, 2013
-
用 Go 写了个类似 ActiveRecord 的 ORM 库, gorm at November 01, 2013
@yakczh 不清楚分布式文件系统的实现,但我感觉所谓的适合不适合和语言无关,要关注的是需要的性能以及开发时间的平衡。。。
这还取决于你的需求,用来存大文件的分布式文件系统,和小文件,只写不读的,只读不写的要求完全不一样。。。
没有研究没有发言权,所以我也不能给你什么有用的建议。。。
-
rails 的脚手架真的显得很初级吗? at November 01, 2013
话说写项目的时候,真心没有用过 scaffold (脚手架) 。。。删除无用的文件/代码太麻烦了。。。。。。
不过 generator, 应该都会用吧。。。
-
用 Go 写了个类似 ActiveRecord 的 ORM 库, gorm at November 01, 2013
-
要小心使用 Where ("xxx NOT IN (?)", array) 。。。 at November 01, 2013
@quakewang +1
-
要小心使用 Where ("xxx NOT IN (?)", array) 。。。 at November 01, 2013
@quakewang 所以我说我执行了好多次,第一次是 0.1 几秒
-
要小心使用 Where ("xxx NOT IN (?)", array) 。。。 at November 01, 2013
虽然我奇怪怎么可能慢 0.01 秒呢。。。。只是一个 1=1,不过根据我人工测试了好几次,好像都是类似这个结果。。。。
-
要小心使用 Where ("xxx NOT IN (?)", array) 。。。 at November 01, 2013
@Victor ActiveRecord 上面的生成的 SQL 还是不够聪明
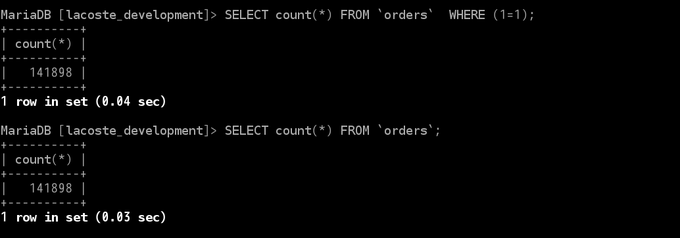
"SELECT `orders`.* FROM `orders` WHERE (1=1)"比
"SELECT `orders`.* FROM `orders`"慢 0.01 秒