-
报错的的那个进程 pool size 不一定是 300
确实是这个问题,之前改 puma 线程数测试了大并发确实没问题,我还以为是好了,客户实际用又出现了,后来发现问题原因是子程序的问题。 我服务器跑了 4 个主要进程(主程序 puma 进程,主程序 sidekiq 进程,主程序 grpc 进程,子程序 grpc 进程),之前一直把注意力放在主程序的 pool 上,因为查询数据库只有主程序查,子程序根本不查数据库,子程序只会通过 grpc 向主程序请求数据,令人意外的是子程序数据库配置还是默认值都没改过,adapter 默认是 sqlite3 都不是 pg,结果居然是向主程序请求数据时居然读取的是子程序的 pool 配置,八杆打不着,但结果就是改子程序 pool 到 100 之后,线上稳定运行了就再也没有报错,这真是一个很迷惑的行为。
-
我做了一个面向开发者的 newsletter at 2022年11月14日
想起了一直看的 rubyweekly ,每周推一些 Ruby 新闻和文章
-
bundle install 时无法装 grpc 网上能找着的姿势都试了一圈还是不行 at 2022年11月09日
降低版本试一下,我的程序有用 grpc 服务,不过是 1.48 版本,没出错
-
值得注意的是,puma 的最大线程数不要超过 5,worker 数少于或等于 cpu 核心即可。这个已经是并发最好的模型。也不需要过多的连接数
感谢指点,开始一直以为线程数小并发不行,之前是 puma 设置是 8 worker,32 线程,现在改成 6 worker,5 线程,并发好像也没啥影响,结合对 rpc 的进一步了解,确定 rpc 会占用连接池,rpc 池开 100 就是最大并发 100 线程,虽然之前有预料是这个问题,还是受监控连接池不高影响了判断,现在改成 150 连接池,rpc pool size 设置 100,puma 设置 workers 6,threads 5, 5 就没问题了
-
经过测试在出现连接池超时报错后 logger 打印 ActiveRecord::Base.connection_pool.stat 信息居然返回的是 {:size=>300, :connections=>5, :busy=>2, :dead=>0, :idle=>3, :waiting=>0, :checkout_timeout=>5.0},这啥情况 @piecehealth ,这个代码打印的信息看不懂了
-
建议查一下 grpc 进程的数据库连接池大小
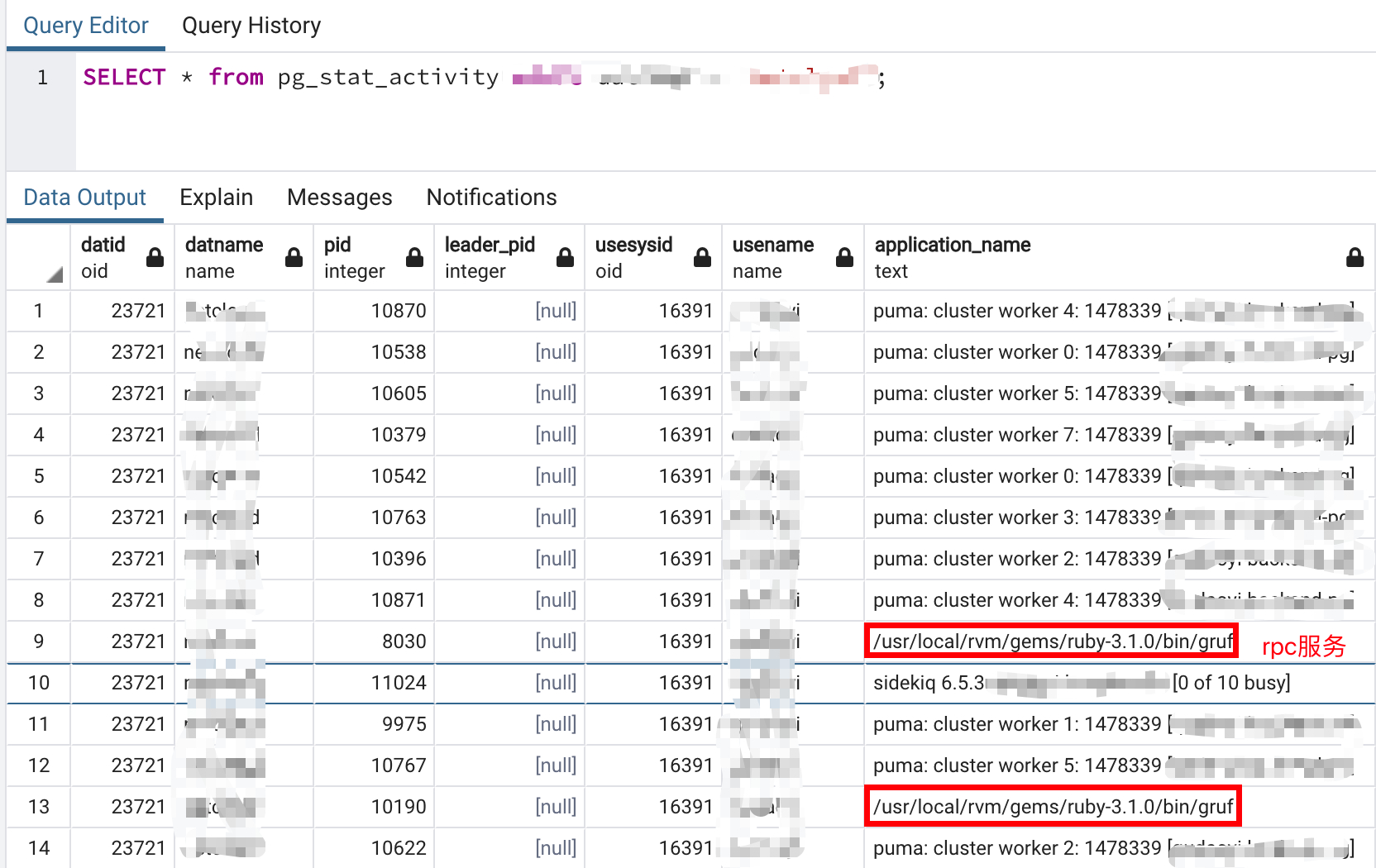
这个怎么查看某个进程的连接大小,我用 SELECT * from pg_stat_activity 这个查询并不大,大部分都是 puma 进程在占用,我的程序报错都会发飞书消息,在报错的时候我用这个 sql 查询结果确实也不高和我在 rds 后台监控表看的差不多,和程序设置的 300 连接池还差很远,就是这个问题各个地方显示都不高,就是报连接池错误所以才比较奇怪
-
ActiveRecord::Base.connection_pool.size 这个应该取的就是 database.yml 配置的值,ActiveRecord::Base.connection_pool.stat 这个会返回 {:size=>300, :connections=>0, :busy=>0, :dead=>0, :idle=>0, :waiting=>0, :checkout_timeout=>5.0} 这类信息 rails c 里看不出来有什么不一样,我准备放在报错的时候打印试试 connections 是否会反应当前连接数
-
Thread.new 和 Concurrent 都没有用到,目前报错都是在 rpc 服务调用的时候报的,我怀疑是 rpc 的问题,rpc 也有一个线程池,我目前开了 200,主子服务通信,子服务会调用主服务查询数据(这个调用应该是产生了新的线程),我通过 SELECT * from pg_stat_activity 查看是可以看到 rpc 线程占用了部分连接,但是从监控图来看,总连接数并不多,和我设置的 300 差很远,如果说监控显示的连接数和 300 接近我到好理解,调整对应的服务线程数就行,现在并不是这样。
下图是 SELECT * from pg_stat_activity 查询部分链接情况,其中看 rpc 也占用了连接池
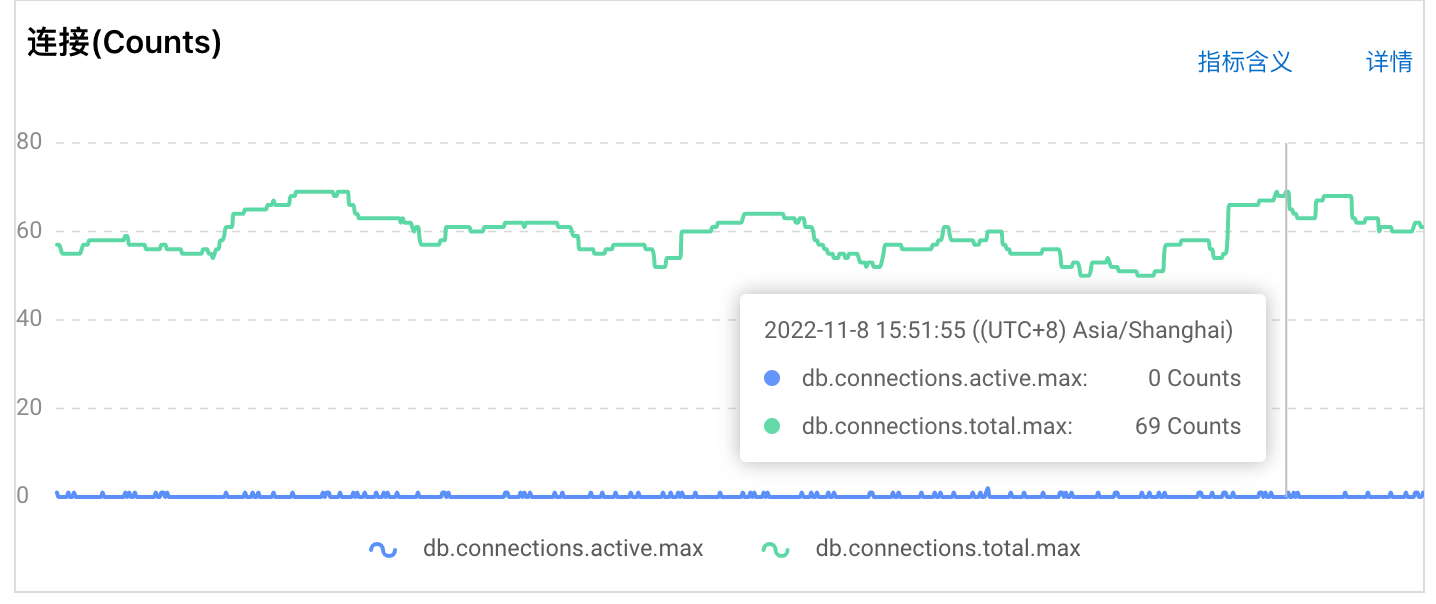
rds 后台监控图显示连接并不高,就是这个不高也报了连接池错误
-
是使用了 ActiveRecord::Base.connection.execute 这种才会出现这种问题吗,系统确实有很多这种代码执行的地方,但是不管是从监控看还是用 sql(SELECT * from pg_stat_activity)查询连接情况都不高,远没到 300,难道这种常驻线程不释放的连接监控或查询反应不出来
-
慢查询从监控看很少,系统有两个服务,一个主程序,一个子服务,主程序和子服务通过 grpc 通信互相调用,可能会存在一个请求通过主程序调用子服务,然后子服务有从主服务获取资源,最后返回,这其中可能会存在调用链路比较长,用户的一个请求几秒完成也是可能,也是第一次用 rpc 服务,之前碰到此类问题提高 pool 值基本就可以解决,现在不灵了
-
cpu 利用率挺低的,看监控图表,基本 15% 以下,难道是瞬时高的问题,感觉也不应该
-
刚看了,这个值目前是 420,主要 rds 监控图表看,最大也就 70 多
-
分布式 ID 有什么好的建议 at 2022年10月13日
这倒是个可以考虑的方案,目前只考虑程序部署多台服务器,数据库用的阿里 rds 暂不考虑多台问题
-
分布式 ID 有什么好的建议 at 2022年10月13日
自增 id 可以猜测数据,hashid 指的是什么,因为我还要考虑多机部署问题,多台机器生产唯一趋势递增 id
-
分布式 ID 有什么好的建议 at 2022年10月13日
多台机器部署用 redis 也可以吗,每台机器间各自生成的 id 是否会冲突重复
-
分布式 ID 有什么好的建议 at 2022年10月13日
UUID 的查询性能应该比较差,所以没采用
-
carrierwave-aliyun 可以生成 oss 智能媒体链接吗 at 2022年09月07日
file.url(thumb: '?x-oss-process=image/resize,h_100')这个开始就试过,换成?x-oss-process=imm/previewdoc,copy_1 文档也当缩略图生成了,点击链接就是下载下来一个无效的文件,那我再试试 activestorage-aliyun 看下,谢谢你的建议
-
有没有可能基于 Ruby 封装一个自己的语言 at 2021年09月09日
哦哦,有空研究下

-
有没有可能基于 Ruby 封装一个自己的语言 at 2021年09月09日
不错,可以研究下,现在研究的方向多了几条选择

-
有没有可能基于 Ruby 封装一个自己的语言 at 2021年09月09日
他这个是有自己的一套语法规则的,即使少个分号结尾都会报错,必须按照他的语法规则来,有自己完整的文档,也算是一套比较成熟的脚本语言了,他这个语言只服务于他自己的产品,内部提供很多接口可以调用自己内部产品相关数据
-
有没有可能基于 Ruby 封装一个自己的语言 at 2021年09月09日
这个大致看了下,好像还不错,可以研究下
-
有没有可能基于 Ruby 封装一个自己的语言 at 2021年09月08日
其实也没打算做太复杂,如果能解决 eval 安全问题也行,毕竟 eval 什么都可以执,安全隐患很大,或者说有什么沙盒模式随便怎么折腾不影响主程序,而且能接收住程序提供的特定接口