运维 诡异的 could not obtain a connection from the pool within 5.000 seconds
即使我连接池数给到很大,并发稍高一点就报连接池错误,看过很多帖子,Google 了很多文章,感觉都是配置 puma 的 workers,threads 然后相应提高 pool 值,我感觉我提高很大都没啥用,这是啥情况
could not obtain a connection from the pool within 5.000 seconds (waited 5.000 seconds); all pooled connections were in use
服务器配置是 8 核 32g,数据库用的阿里云 pg 版 rds,puma 设置 workers 8,threads 8, 32,数据库配置 pool 给到 300 还是会报这个错误,我看 rds 监控图表连接数最大也就 70 左右的样子,看历史从来没超过这个值,不管我 pool 给多少感觉并发稍大就报这个。另外补充一下,服务器同时开启了 rpc,sidekiq 服务。
pg 的话,我最近刚好遇到了这个问题。数据库最大连接和 pool 无关,这个数据是由 pg 配置文件里的参数 max_connections 决定的。默认 max_connections 是 100。按照你的配置 8 * 32 = 256,所以你需要把 max_connections 调整为大于等于 256 的值
慢查询从监控看很少,系统有两个服务,一个主程序,一个子服务,主程序和子服务通过 grpc 通信互相调用,可能会存在一个请求通过主程序调用子服务,然后子服务有从主服务获取资源,最后返回,这其中可能会存在调用链路比较长,用户的一个请求几秒完成也是可能,也是第一次用 rpc 服务,之前碰到此类问题提高 pool 值基本就可以解决,现在不灵了
是使用了 ActiveRecord::Base.connection.execute 这种才会出现这种问题吗,系统确实有很多这种代码执行的地方,但是不管是从监控看还是用 sql(SELECT * from pg_stat_activity)查询连接情况都不高,远没到 300,难道这种常驻线程不释放的连接监控或查询反应不出来
- 检查一下 databse.yml 的数据库连接池大小是否跟 puma 线程数一致(默认是 5)
- 检查应用中是否有多线程代码操作数据库。
这个问题一般是应用线程抢不到数据库连接池里的链接,跟数据库负载关系不大。
任何产生数据库连接的语句都会从连接池获取连接,比如 User.all ,用 ActiveRecord::Base.connection.execute 举例是因为不一定有 User Model
是否是在 Worker 或者 Thread.new 或者 Concurrent 这样的地方报的错?
Thread.new 和 Concurrent 都没有用到,目前报错都是在 rpc 服务调用的时候报的,我怀疑是 rpc 的问题,rpc 也有一个线程池,我目前开了 200,主子服务通信,子服务会调用主服务查询数据(这个调用应该是产生了新的线程),我通过 SELECT * from pg_stat_activity 查看是可以看到 rpc 线程占用了部分连接,但是从监控图来看,总连接数并不多,和我设置的 300 差很远,如果说监控显示的连接数和 300 接近我到好理解,调整对应的服务线程数就行,现在并不是这样。
下图是 SELECT * from pg_stat_activity 查询部分链接情况,其中看 rpc 也占用了连接池
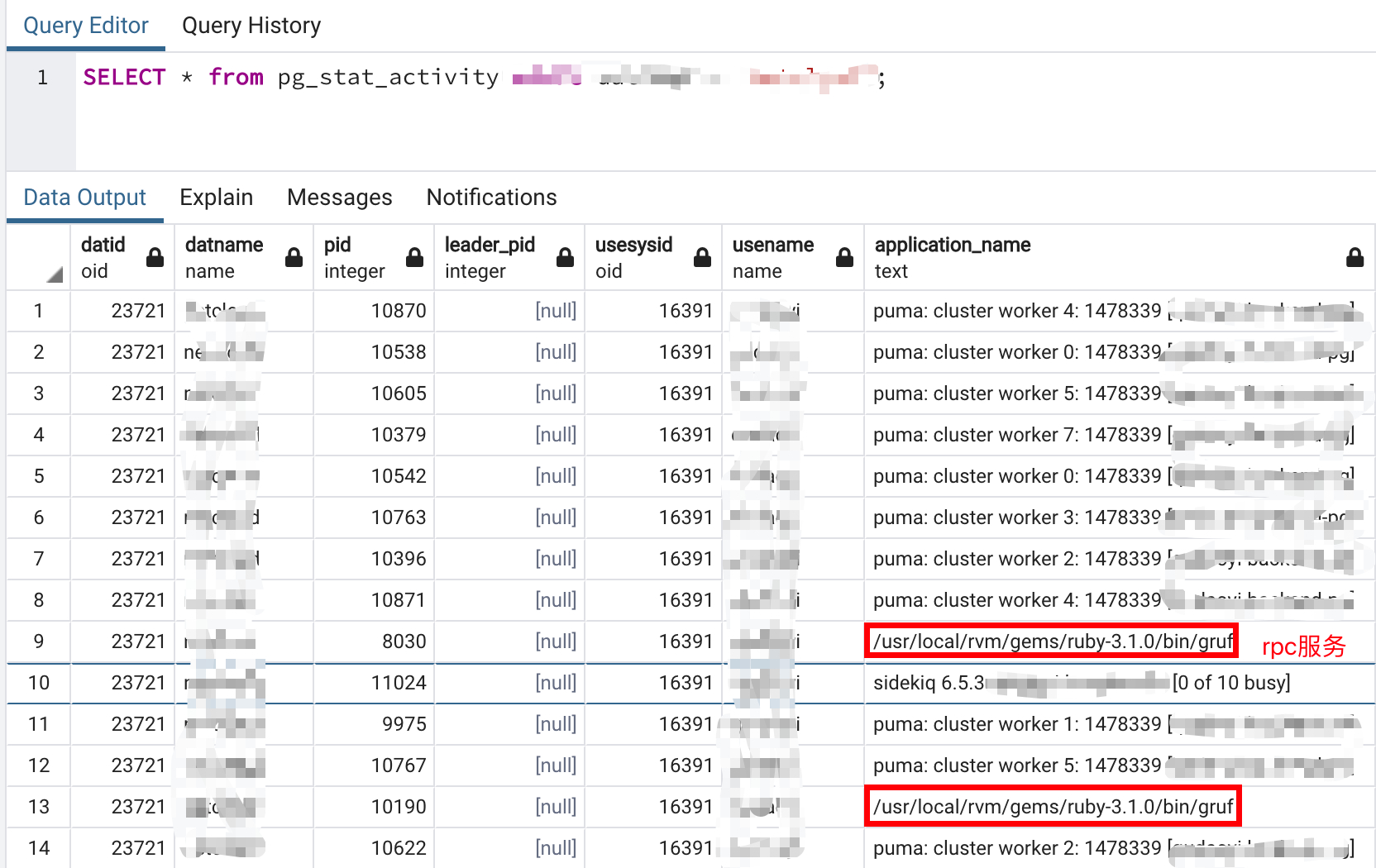
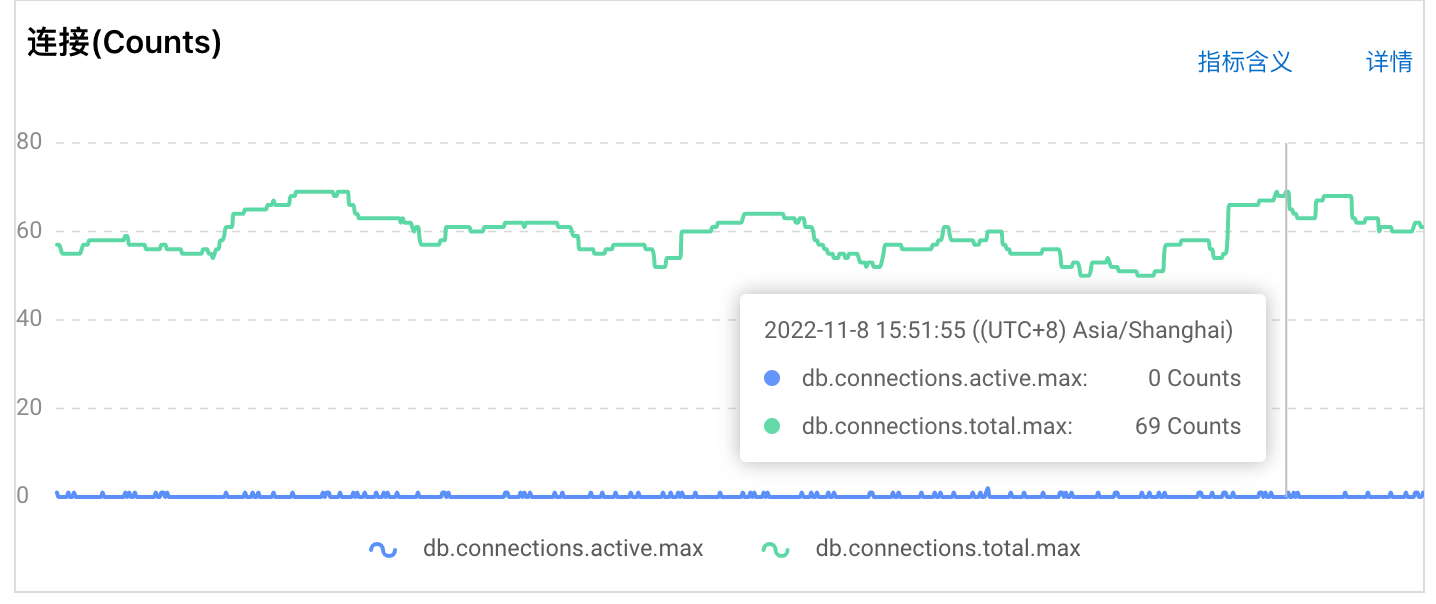
rds 后台监控图显示连接并不高,就是这个不高也报了连接池错误
先看一下ActiveRecord::Base.connection_pool.size。这个数是你 rails 进程的最大并发数。
rpc 也有一个线程池,我目前开了 200
相当于 200 个线程共享 ActiveRecord::Base.connection_pool.size 个数据库链接,如果 size 太小肯定不够用,从 pool 里 checkout 一个 connection 肯定会超时。
ActiveRecord::Base.connection_pool.size 这个应该取的就是 database.yml 配置的值,ActiveRecord::Base.connection_pool.stat 这个会返回 {:size=>300, :connections=>0, :busy=>0, :dead=>0, :idle=>0, :waiting=>0, :checkout_timeout=>5.0} 这类信息 rails c 里看不出来有什么不一样,我准备放在报错的时候打印试试 connections 是否会反应当前连接数
建议查一下 grpc 进程的数据库连接池大小。连接池大小一般都是通过环境变量来的,可能 grpc 进程的大小不是 300。 如果你是直连 postgres(不通过 pgbouncer 一类的中间件),连接池满的话 pg 不可能不到 70 个链接。
建议查一下 grpc 进程的数据库连接池大小
这个怎么查看某个进程的连接大小,我用 SELECT * from pg_stat_activity 这个查询并不大,大部分都是 puma 进程在占用,我的程序报错都会发飞书消息,在报错的时候我用这个 sql 查询结果确实也不高和我在 rds 后台监控表看的差不多,和程序设置的 300 连接池还差很远,就是这个问题各个地方显示都不高,就是报连接池错误所以才比较奇怪
经过测试在出现连接池超时报错后 logger 打印 ActiveRecord::Base.connection_pool.stat 信息居然返回的是 {:size=>300, :connections=>5, :busy=>2, :dead=>0, :idle=>3, :waiting=>0, :checkout_timeout=>5.0},这啥情况 @piecehealth ,这个代码打印的信息看不懂了
@txbleehom 这种一般都是两个问题,1 是有慢查询,前面连接处理慢导致后面的连接找不到新的连接池对象。2 是 puma 设的参数不合适,导致并发起来的时候连接池不够。
值得注意的是,puma 的最大线程数不要超过 5,worker 数少于或等于 cpu 核心即可。这个已经是并发最好的模型。也不需要过多的连接数。有需要进一步交流的可以加我微信。
值得注意的是,puma 的最大线程数不要超过 5,worker 数少于或等于 cpu 核心即可。这个已经是并发最好的模型。也不需要过多的连接数
感谢指点,开始一直以为线程数小并发不行,之前是 puma 设置是 8 worker,32 线程,现在改成 6 worker,5 线程,并发好像也没啥影响,结合对 rpc 的进一步了解,确定 rpc 会占用连接池,rpc 池开 100 就是最大并发 100 线程,虽然之前有预料是这个问题,还是受监控连接池不高影响了判断,现在改成 150 连接池,rpc pool size 设置 100,puma 设置 workers 6,threads 5, 5 就没问题了
先说一下结论免得你排查走弯路:抛ActiveRecord::ConnectionTimeoutError错误的话 100% 是因为你的业务线程数跟 ActiveRecord 的本地数据库连接池大小不匹配(错误信息could not obtain a connection from the pool within %0.3f seconds (waited %0.3f seconds); all pooled connections were in use, https://github.com/rails/rails/blob/v7.0.4/activerecord/lib/active_record/connection_adapters/abstract/connection_pool/queue.rb#L124), ActiveRecord::ConnectionTimeoutError的注释:
Raised when a connection could not be obtained within the connection acquisition timeout period: because max connections in pool are in use.
可能的原因有
- 配置问题,比如 puma/worker max thread 跟 database.yml 里的 pool size 不匹配;
- 业务线程有多线程占用 ActiveRecord 的数据库连接。
如果是数据库原因不能建立新的数据库连接,抛的错是 ActiveRecord::ConnectionNotEstablished,错误信息来自于具体数据库连接的库,例如 pg 的是: https://github.com/rails/rails/blob/v7.0.4/activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb#L87
我好奇的是你的 ActiveRecord pool 设成 300 居然还能 checkout 不了新的数据库连接,我猜测你的应用应该有多种 rails 进程(比如 puma,worker,grpc 三种进程),报错的的那个进程 pool size 不一定是 300。
puma 的最大线程数不要超过 5,worker 数少于或等于 cpu 核心即可。这个已经是并发最好的模型. 大佬可以讲讲这个吗,我也一直以为线程越多,同时可连接的人就越多,并发就越大。之前看有的文章写的是 worker 设置为 cpu 核心数,threads 设置为 cpu x2。还有就是使用 sidekiq 的话,文档建议 concurrency 25,那实际中 database 的 pool, sidekiq 的 concurrency,puma 的 worker、threads 这几个是什么关系,应该怎么设置
报错的的那个进程 pool size 不一定是 300
确实是这个问题,之前改 puma 线程数测试了大并发确实没问题,我还以为是好了,客户实际用又出现了,后来发现问题原因是子程序的问题。 我服务器跑了 4 个主要进程(主程序 puma 进程,主程序 sidekiq 进程,主程序 grpc 进程,子程序 grpc 进程),之前一直把注意力放在主程序的 pool 上,因为查询数据库只有主程序查,子程序根本不查数据库,子程序只会通过 grpc 向主程序请求数据,令人意外的是子程序数据库配置还是默认值都没改过,adapter 默认是 sqlite3 都不是 pg,结果居然是向主程序请求数据时居然读取的是子程序的 pool 配置,八杆打不着,但结果就是改子程序 pool 到 100 之后,线上稳定运行了就再也没有报错,这真是一个很迷惑的行为。