Ruby Rails 应用的部署管理
当使用命令行 rails new 去创建一个新项目时,Rails 默认会创建三个环境:
- development: 本地开发环境。
- test: 用来跑测试。
- production: 生产环境,用来服务客户。
在项目的最早期,还处于验证想法阶段。工程师的工作流程也比较粗狂,写代码,跑测试,然后直接部署代码至生产环境。
业务的第一阶段:少量客户阶段
产品不断迭代,逐渐的有客户开始使用产品。为了保证工程质量,这时候需要给 Rails 添加一个预发布环境,通常大家都命名为 staging 环境,工作流程也开始严谨:
- 工程师在本地开发新功能。(developer 环境)
- 在 CI(或本地)跑测试。(test 环境)
- 代码合并到 staging 分支,并且部署到 staging 环境,QA 工程师测试新功能。
- 如果没有 bug,则部署到 production 环境,供客户使用。
environments
├── development.rb
├── staging.rb
├── production.rb
└── test.rb
业务的第二阶段:大量客户 + 多团队协作
如果产品市场反响良好,客户越来越多。工程师团队规模也由几个人扩增到几十人或上百人。人员众多,且共用一个 staging 环境,合并代码到 staging 分支时容易冲突。
程序员耐心时,遇到代码冲突会联系原作者,一起解决。如果是跨国团队,因为时差的原因,一个来回的沟通需要一天时间。这时候程序员可能就没了耐心,直接重置 git 的 staging 分支。这会导致一系列的误会,别人正在测试的功能凭空消失,QA 工程师上报 bug,结果细查下来是代码重置导致的。
为了降低代码冲突和沟通成本,很多公司会为各团队创建专属的部署环境,而不是吃大锅饭。各团队井水不犯河水,如果某个部署环境出现问题,也只会影响到单个团队,不会拖累整个公司开发进度。
| 实例 | 部署的 Git 分支 | 用途 |
|---|---|---|
| production | release/xxx | 给客户使用的生产环境 |
| demo | demo | 销售给客户做演示。 |
| staging | main / 下一个 release 分支 | 用于上线前的回归测试 |
| staging-1 | staging-1-branch | 给 "小熊猫" 团队使用 |
| staging-2 | staging-2-branch | 给 "自杀小分队" 团队使用 |
| staging-3 | staging-3-branch | 给 "星河战舰" 团队使用 |
| staging-4 | staging-4-branch | 给 "深海水妖" 团队使用 |
| staging-... | staging-6-branch | 给 ... 团队使用 |
工程师越多,需要的 Rails 部署环境也越多。如果我们要创建 6 个部署环境 staging,staging-1, staging-2, staging-3, staging-4, demo, 该怎么做呢?
可以在 Rails 的 config/environments 目录下创建 6 个配置文件。这是 Rails 推荐的配置风格,原汁原味。
> tree environments
environments
├── demo.rb
├── development.rb
├── test.rb
├── production.rb
├── staging.rb
├── staging-1.rb
├── staging-2.rb
├── staging-3.rb
├── staging-4.rb
...
但事情没那么简单,除了 config/environments,还有许多额外工作。我们要在 config/database.yml 添加 6 个新部署环境的数据库配置。
default: &default
adapter: postgresql
database: <%= ENV['DATABASE_NAME'] %>
username: <%= ENV.fetch("DATABASE_USER", 'postgres') %>
password: <%= ENV['DATABASE_PASSWORD'] %>
port: 5432
production:
<<: *default
demo:
<<: *default
staging-1:
<<: *default
staging-2:
<<: *default
staging-3:
<<: *default
...
此外,如果有些工程师在常量中定义配置,那我们还需要全局搜索 Rails.env,确保新创建的部署环境,都有匹配的赋值。尤其是在犄角旮旯里定义的变量,如果遗漏,新部署会一直报错。
比如,有人会把各个部署环境的 Redis 地址写在了常量中。
# config/initializers/sidekiq.rb
case Rails.env
when :demo
REDIS_HOST = 'redis-demo.3922002.redis.aws.com:6379'
when :staging-1
REDIS_HOST = 'redis-s1.3922002.redis.aws.com:6379'
when :staging-2
REDIS_HOST = 'redis-s2.3922002.redis.aws.com:6379'
...
在常量里定义配置,太容易出错。多数工程师会把不同部署环境的配置抽出来,放到不同的配置文件中,并且用一些库来管理,Rails 常用的库是 rubyconfig/config。如果团队在使用这些库,我们也需要为新的部署环境添加配置文件。
config/settings/demo.yml
config/settings/production.yml
config/settings/staging.yml
config/settings/staging-1.yml
config/settings/staging-2.yml
config/settings/staging-3.yml
config/settings/staging-4.yml
...
以上方案有几个的缺点:
第一,即使有完备的内部文档,全套走下来,工程量不小,人力成本很高。
第二,每次创建新的部署环境都要修改老代码中的常量。修改正在运行的老代码乃兵家大忌,稍有不慎就会 bug 缠身,死无葬身之地。
第三,安全性差。配置中包含 client_secret,token,私钥,如果代码不幸泄露,各种秘钥被一锅端。使用这种方案创建的 docker 镜像混杂了各种配置信息,不干净。万一泄露,也是个麻烦事。
虽然有种种缺陷,但这种 Rails 原生的解决方案也能维持一段时间。
业务的第三阶段:多租户方案 + 私有化部署 + 百人以上开发团队
项目早期,通常只有一个 production 部署环境。
- 如果产品面向的是普通客户(To C),一个 production 部署就能满足所有客户的需要。
- 面向企业客户的 SaaS 产品,早期也是多租户(multi-tenant)设计,一个 production 部署环境服务所有的企业。
因此很多程序员脑子里有个假设:"production 部署环境只有一个"。随着业务的增长,这种假设会被打破。
为了国家安全,一些国家要求本国的公民的数据必须保存在本国的数据中心。Apple iCloud 既在美国有数据中心,也在中国贵州有数据中心,同一套代码部署在中国和美国,都是以 production 模式运行。抖音在美国部署在 Oracle Cloud 上,在中国则部署在自己的机房里,他们也都以 production 模式运行。
大客户处于安全的考虑,要求私有化部署。阿里云同样一套代码,会卖给政府,中国电信,公安系统,代码部署在他们各自的机房。Gitlab 是一个开源的代码管理平台,客户可以选择使用云版本,也可以私有化部署到内网,无数企业为了安全性选择后者。所有企业的运行模式也都为 production。
所以一套 SaaS,在真实的世界中的部署场景应该是这个样子:
| 运行实例 | 部署的 Git 分支 | 用途 |
|---|---|---|
| production | release/100* | 部署在公有云上,多租户使用的 SaaS |
| production-gov | release/101 | 客户为政府,部署在政府私有机房 |
| production-cnpc | release/99 | 客户为中石油,部署在中石油私有机房 |
| production-china-police | release/100 | 客户为中国警察,部署在公安私有机房 |
| production-us-police | release/100 | 客户为美国警察,部署在 AWS |
| production-huawei | release/100 | 客户为华为,私有化部署 |
| demo | demo | 销售给客户做演示。 |
| staging | main / 下一个 release 分支 | 用于上线前的回归测试 |
| staging-1 | staging-1 branch | 给 "小熊猫" 团队开发测试使用 |
| staging-2 | staging-2 branch | 给 "自杀小分队" 团队开发测试使用 |
| staging-3 | staging-3 branch | 给 "星河战舰" 团队开发测试使用 |
| staging-4 | staging-4 branch | 给 "深海水妖" 团队开发测试使用 |
| staging-... | staging-... branch | 给 ... 团队开发测试使用 |
note:
release/xxx 代表某个已经过 QA 测试的部署分支。
当有众多 production 环境时,难道要把所有客户的配置都混入到代码里吗?显然不可能!客户也不答应!所以大家不约而同的认为代码应该无状态,配置信息应单独存储,这样创建一个部署环境时就不需要改动一行代码了。
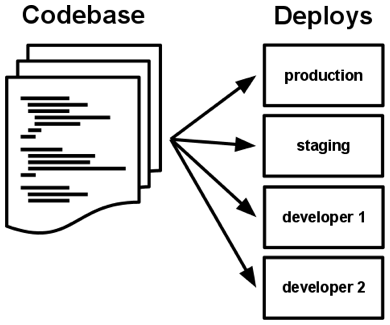
概念:部署 (deploy)
当一套代码的 production 环境只有一个时,我们可以用 "production "等字眼代指某个运行的实例。
当一套 Gitlab 代码有成千上万个 production 运行实例时,"production 环境"就无法指代任何事。
为了更精确的表达,我们用部署(deploy)这个概念代指代码的运行实例。
同时 config/environments 下的个文件 production.rb / staging.rb / development.rb / test.rb,我们称之为代码的运行模式。
当 Gitlab 部署到华为内网时,我们可以这样描述 "Gitlab 在华为创建了一个部署(deploy),它的运行模式为 production"。
The 12-factor Application
Heroku 写过一篇 SaaS 架构文章《12-factor Application》,概括了设计 SaaS 应用的 12 条原则,被奉为圭臬。时至今日,依然无出其右。
第一条原则:一份基准代码(Codebase),多份部署(deploy)
每个应用的一份基准代码,可以同时存在多份部署。每份部署相当于运行了一个应用的实例。通常会有一个生产环境,一个或多个预发布环境。
第二条原则:显式声明依赖关系(dependency)
同样的代码,在不同机器,依赖要一致,行为也要一致,比如:
- JavaScript 使用 npm 或 yarn 来管理各种库的依赖。
- Ruby 使用 Bundler 来管理各种库的版本依赖。
- Docker 不但打包代码的库的依赖,还打包了操作系统的依赖。任何人获得 docker image 后都可以运行代码,不会出现这种尴尬情况:一份代码只能在我的电脑上跑,不能在你的电脑上跑。
第三条原则:在环境中存储配置
12-Factor 推荐将应用的配置存储于环境变量中(env vars, env)。环境变量可以非常方便地在不同的部署间做修改,却不动一行代码。
Docker
比如 Docker 允许你把配置放到环境变量中,从而创建不同的实例(container)。
docker run --name postgresql \
-e POSTGRES_USER=myusername \
-e POSTGRES_PASSWORD=mypassword \
-p 5432:5432 -v /data:/var/lib/postgresql/data \
-d postgres
Helm
Helm 是一个 Kubernetes 应用的包管理工具,它也遵循了 12-factor 的前三条原则。它有三个核心概念 chart,config,release。
- chart 是模版,无状态。
- config 是配置信息
- release = chart + config。当把模版和配置拼凑在一起时,就创建了一个部署实例。
我想开源软件之所以更偏爱 12-factor,是因为作者从第一天开始就知道,这份软件会千千万万个个体使用,所以绝对不能 hard code,配置和代码必须分离。
我们可以借鉴 12-factor 思想,用一份代码代码可以迅速创建几十个部署,让业务程序员开心,让 DevOps 开心,让客户开心。
优化方案
第一步,让代码无状态,代码中所有的配置信息都取自环境变量。
比如,DB 的配置要取自环境变量。
# config/database.yml
# ...
production:
<<: *default
database: <%= ENV['DATABASE_NAME' %>
host: <%= ENV['DATABASE_HOST'] %>
password: <%= ENV['DATABASE_PASSWORD'] %>
Sidekiq 的配置也取自环境变量。
Sidekiq.configure_server do |config|
config.redis = {
host: ENV['REDIS_HOST'],
port: 6379
}
end
# ...
任何逻辑,但凡和部署相关,其配置都取自环境变量。
class OauthController < ApiController
def redirect
redirect_to(ENV['GOOGLE_OAUTH_URL'])
end
end
第二步,准备配置文件。
为 staging-1, staging-2, staging-3, staging-4,demo,production,production-gov,production-china-police,production-us-police 等部署环境创建配置文件。
如果你使用的是 AWS,可以把某个部署的配置保存在 Parameter Store,敏感信息可以保存在 AWS secret manager。
# 创建 staging-1 的配置信息
aws ssm put-parameter \
--name "staging-1-configuration" \
--value "parameter-value" \
--type String \
--tags "DB_HOST=xxx,DB_USER=xxx,DB_PASSWORD=xxx,REDIS_HOST=xxx,GOOGLE_OAUTH_URL=xxxx"
如果你是用的是 Kubernetes,可以把不同部署的配置信息保存在不同的 ConfigMap,敏感信息保存在 Secret 中。
kubectl create configmap staging1-config-map \
--from-literral="DB_HOST=xxx" \
--from-literral="DB_USER=postgres" \
--from-literral="DB_PASSWORD=xxx"
第三步,以 production mode 运行各个部署环境。
staging-1, staging-2, staging-3, staging-4, staging-5, ... staging-x,demo,production,production-gov,production-china-police,production-us-police 内部的运行脚本都如下所示:
export .env
RAILS_ENV=production rails s
第四步:把代码和配置组合在一起,创建一个个部署。
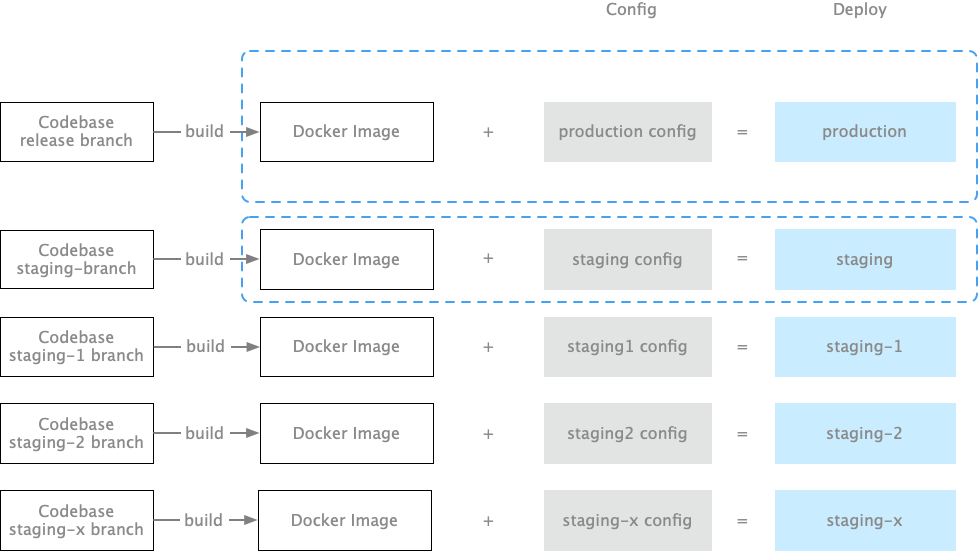
如果你使用的是 Capistrano 部署代码,那么
Code + 配置 = 部署
如果你使用的是 Docker 部署代码,那么:
Docker Image + 配置 = 部署
如果你使用的是 Kubenetes,将不同配置文件注入到了 Pod 中,就变成了不同的部署。
---
apiVersion: v1
kind: Pod
metadata:
labels:
name: webapp
name: webapp
namespace: default
spec:
containers:
- name: web-app
image: web-app:staging-1
envFrom:
- configMapRef: 👈 看这里
name: staging-1-config-map
- secretRef: 👈 看这里
name: staging-1-secrets
优点
代码无状态,可以被复用。如果想创建部署,只需要准备一份新的配置文件就可以,省事省力。
代码和 Docker image 中不包含机密信息。即使代码泄露也不会扩大风险。
方便私有化部署。
可以为不同部署的配置文件可以设置不同的访问权限,比如仅仅允许特定团队访问 production 部署实例的的配置信息。
在本文中所有部署的运行模式都是 production mode,以此消除了不同部署的差异 (parity)。
缺点
NewRelic, Datadog, Sentry 等监控工具默认会把环境信息附着在监控数据上,方便筛选过滤。在第二种方案中,所有的部署的运行模式都为 production mode,这导致监控数据都混在 production 下。遇到事故,工程师根本无法排查是哪个部署出了问题。
如何解决监控工具的问题?
其实 NewRelic, Datadog, Sentry 提供了接口,允许我们自定义部署的名字,以 Sentry 举例,它的语法如下:
Sentry.init do |config|
#...
config.environment = "你喜欢的部署名"
end
因此我们可以在 staging-1, staging-2, staging-x, production-x 等不同部署的配置中,引入一个新的变量 "DEPLOY_ID" 来声明部署的名称,并赋值给监控工具。
假如 staging-1 的配置信息如下:
DEPLOY_ID =staging-1
DB_HOST=xxx
DB_USER=xxx
...
我们可以这样配置 Sentry:
Sentry.init do |config|
#...
config.environment = ENV['DEPLOY_ID'] # 它的值为 staging-1
end
可以这样配置 Datadog:
Datadog.configure do |c|
# ...
c.env = ENV['DEPLOY_ID'] # 它的值为 staging-1
end
这样就能保证监控工具的正常显示了。
感谢
本文中的方案,来自于 Workstream 同事们 和 SAP 前同事们的实践经验,我只是加工整理,提笔记录下来。
特别感谢 Louise Xu, Felix Chen, Vincent Huang, Teddy Wang, Kang Zhang 的审校和反馈。