分享 数据结构之 HashMap
平时在工作中,会使用大量的 Hash,这种美妙的数据结构,在开发中给予了我们极大的帮助,非常值得深入学习。我想通过本文,来梳理一下,到目前为止我在 HashMap 上粗浅的知识积淀。
文章的内容大致会有以下几个部分:
- 哈希的实现原理
- 哈希的冲突解决
- 哈希映射的应用
用哈希实现快速存取
一个爬虫系统在互联网上按照链接(url)爬取数据时,每爬取完一个链接,就将该链接保存在某个地方,标记为已爬去。当遇到下一个链接时,它需要快速的知道这个链接是否已经被爬取过,如果已经被解析过则转而爬下一个。
实现这个爬取标记的方法可以是:将爬取过的链接放到一个数组中,每准备爬一个链接,就到数组中来查找这个链接在不在数组中。不在数组中,说明没有爬取过。成功爬取后,就将这个链接追加到数组中,标记为已爬取。
此方案是可行的,不过,当爬取的数据量非常大时,上万甚至百万在互联网百亿级的链接数量中是非常渺小的。这个时候每次查询链接是否已经被爬取过,都需要遍历整个庞大的数组,时间复杂度为 O(N),性能可想而知会随着数据量的增大线性下降。
这时候,就需要一个能提供快速查找的数据结构,来替换数组方案。HashMap 就是这样的一种解决方案,它能在庞大的数据集中实现近似 O(1) 的存取时间复杂度。理想状态下,查询时间消耗不受数据量增加的影响,始终保持在一个常量范围。
本质上,用 HashMap 时,已经爬取过的链接数据也是存放到一个数组中的,只不过,通过 HashMap 存放的链接,可以快速地知道,自己是被放在数组的具体哪个下标(index),通过 index 就可以在数组中一下就将数据取到。A 是这个数组,A[index] 就直接取到数据,而不需要去遍历整个数组。
哈希如何实现
那么,HashMap 是怎么知道,某一个链接是具体存放到数组的哪一个下标中的呢?这里面一定有一个映射关系在,通过这个映射关系,就知道数据是被存放到数组的哪个位置的。
到这里就必须得介绍一个神奇的东西,映射关系的秘密就藏在里面。
哈希函数
哈希函数也称做散列函数 ,是一种数据压缩算法,可以将任意长度的内容压缩到一个固定的范围,形成一个固定长度的摘要,实现内容体积的压缩。
给一个输入(链接或者其他随意内容),哈希函数会输出一个固定长度的摘要。相同的内容每次都会得到相同的摘要,不同的内容会得到不同且分散的摘要(理想情况下)。也就是说,通过哈希函数,可以得到某个文本和一段摘要之间稳定的映射关系。
哈希函数有很多种,不同的质量也有差异,具体的可以自行深入学习,这是一个知识深水区。
到这里,我们可以基本了解上面说的,链接和数组下标的稳定映射了。可以浅显理解为,每一个不同的 url,通过哈希函数,可以得到一个数字,不同的 url 会得到不同的数字,这个数字就是数组的下标。通过这个下标就可以将数据存放到数组的下标中,并且以 O(1) 的时间复杂度,直接取到数组中的数据,A[index]。
Ruby 中的例子如下:
irb> 'https://www.baidu.com'.hash
783237224
irb> 'https://ruby-china.org'.hash
1037775096
irb> 'https://ruby-china.org'.hash
1037775096
输出值是稳定的。由于哈希函数的差异,每次重启后得到的 hash 值会不一样,但当次执行时输出是稳定的。
就是这样通过哈希函数,可以知道url是存放到数组的哪个下标的。将对应数组下标设置为true,表示已经爬取。
到这里,可以继续丰富一下 HashMap 的介绍了。HashMap 这种数据结构,提供一种 key到value 的映射。这里的key就是上面的url,value 就是上面的true 。每个 HashMap 会有很多的 key 和 value,他们被称作键值对。通过 key,可以快速地读写对应 value。
上面介绍哈希函数映射数组的时候,有一个很大很大的问题,就是哈希函数的输出值是个很大的值,还可能是负数,范围极广。那么我为了存放几个键值对,就需要申请一个超级大的数组来存放数据,而且这个数组一般来讲,由于太大,操作系统是没有办法分配的。所以,这是不科学的,那么具体的解决方案是什么呢?
实际的方案就是,刚开始只申请长度为 L 的数组,L 的值一般是 20。在计算url到底存放到数组的哪个下标之前,先用 url 的哈希值 x 对 L 取模。假如 x=2348275235354,那么结果如下:
irb> 2348275235354 % 20
14
那么这个 url 对应的键值对,就存放到数组下标为 14 的位置。每次存取,都需要进行取模操作。这样就避开了上面说的数组超级大的问题,当键值对的数量进一步增加的时候,再扩大数组的容量。
然而,问题随之来了,慢慢地会发现又很多 url 的哈希值 x 对 L 取模后都是 14,这样就造成了冲突,没办法直接在数组下标为 14 的位置直接存放数据了。这就引出了 hashMap 的冲突解决。
常见的冲突解决方案
链表

如上图表示,value 会被存放在一个链表中,当有 key 冲突的时候,就将键值对追加到链表的头部。当要获取 key 对应的 value 时,需要遍历整个链表。
这种实现相对简单易懂,不过当链表长度过大时,遍历链表会导致性能明显下降。 这里有一个基于链表的实现实例
链表加红黑树
由于遍历链表会带来性能损耗,在这基础上的一个解决方案就是,当链表长度超过某个阈值时,就将链表变成一颗红黑树,通过红黑树来提升查找性能。
这样会导致实现复杂度上升,同时内存消耗也会增加。
开放地址
开放地址 则是另外一种实现方式。

当发生下标冲突的时候,则转而去查看对应下标的下一个位置是否为空,如果为空则将键值对存入,不然检测下一个下标,不停地往下探测,直到有空的位置。
这种探测的方式被称为线性探测,探测的间隙根据实现方式的不同而有差异。
这种方案,避免了创建链表,这样可以节约不少内存。同时由于冲突的键值对都是存放在相邻的位置,查找时会得益于计算机预读连续内存数据(链表数据是分散的),从而提升性能。Ruby 2.4 中的 hash 就是使用的这种方案。
不过这种方案不适合存放大规模数据,会导致更频繁的重哈希,探测的实现也增加了整体复杂度。 RubyChina 上有这种方案的文章介绍
哈希的扩容
前面介绍过,HashMap 刚开始都是分配一个小数组来存放数据的,如果存放的数据不断增加时怎么办呢?
当数据增加时,它需要扩容,扩容的过程就需要重哈希。重哈希的过程就是:
- 重新申请一个更大的数组
- 遍历原来的数组,将所有数据,重新映射到新数组中
- 废掉原来的数组
可以看出,这是一个非常耗时的过程,特别是当数据量特别大的时候。重哈希例子
Redis 为了减少重哈希过程中带来的延迟,使用了一种精妙的方式。它不一次性完成上面的第 2 步,而是将第 2 步的操作分散到后面的多个操作中去。每来一个对应的 redis 请求,就移动一个数据,直到移动完毕,才将旧数组废弃掉。它的重哈希可能会持续很长的时间。
并发性
经过上面介绍的 HashMap,可以发现一个问题,就是在写入数据或者重哈希的时候,它并不是线程安全的。
不过,在 Ruby(MRI) 和 Python 这种语言中,这并不是什么问题,因为根本就没有真正的并发。但是在 Java 中,这个问题就值得思考了。
为了保证线程安全,在多线程环境下,就需要对 HashMap 的操作加上互斥锁,保证同一时间只能有一个线程进行写操作,当然这会极大的损耗性能。
当多个线程对不同的且没有冲突的 key,进行写操作时,可能并不会造成并发问题,但这种情况无法识别,进而造成了性能上的白白浪费。
针对这种情况,Java 中有一个 ConcurrentHashMap,它号称可以实现并发写操作。进一步了解其实现原理,它在内部进行数据分段,每个分段各自独立,段与段之间可以实现并发写,但是同一段的数据,还是需要互斥锁。当然这在另一个层面解决了,上面所说的性能浪费问题。
它需要进行两次哈希,第一次哈希找到对应的段,第二次才找存放数据的位置。
哈希映射
由于哈希函数,能实现一份数据到一段摘要的稳定映射,这种特性在计算机领域中得到非常广泛的应用,常见的就是路由分发。下面列举一下简单的例子。
ES 分片,ES 中数据是存放到多个分片的。通过哈希映射就能计算出这片文档应该放到哪个分片,下一次来查找,通过映射规则,就直接到对应的分片上拿数据。
Nginx 代理,实现负载均衡时,可以对链接进行哈希,将请求稳定地代理到固定的机器上。
Redis 集群,当单台 redis 容量不够时,需要将数据存放到多个机器上时,也可以对 key 进行哈希,从而稳定映射到对应的机器上。
这些例子都是通过 哈希值% 某个固定的数量 来实现稳定的路由分发。在上面的 Redis 例子中,不同的 key 可能会被路由到不同的机器上,从而实现负载分摊。
当 Redis 集群规模需要扩展,需要由原来的 3 台机器扩展到 5 台时,那么问题来了。
上面的某个固定的数量会发生变化,从原来的 3 变成了 5,假设原来some_redis_key这个 key 的数据被路由存放到机器 1,现在由于机器增加了,它会被路由到其他机器。也就是说,原来这个 key 对应的数据就会找不到了。由于某个固定的数量发生了变化,导致原来的映射规则发生了变化,新情况下,原来的大量数据就会一下子找不到,因为现在被路由到的机器,并不是之前存数据的机器。
集群中庞大的数据量,不可能会像重哈希那样重新全量分配一次数据,这个不现实。所以这种简单的映射方案,在 Redis 这种集群中是不能用的,需要有一个能适应集群数量变化的映射方案,使得机器数量变化时,原来的映射不会被完全打破。
这就是引出本文中最后一个要点: 一致性哈希。
一致性哈希
一致性哈希算法 是一个很牛逼的创造,它保证了在集群情况下,有新的机器加入,或者有机器退出时,原来的映射关系不会被全面地破坏,只会影响局部的数据映射。
环形哈希空间
假设选择的哈希函数的输出值的范围是 0~2^32,不管输入什么值,得到的哈希值都在这个区间中。现在把这个水平横向的区间的首尾相连,也就是把这个区间想象成一个环。
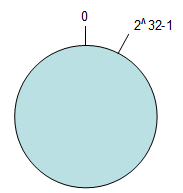
以 redis 的 key 存储来举例说明,所有的 key 的哈希值都会落到这个环上,这种映射关系是通过上面介绍的哈希函数得到的,也就是说这个映射关系是稳定的。
上面我们介绍的 redis 的 key 存储映射方式是 Hash(key)%机器的数量 , 通过得到的值,决定存放到哪台机器。这种映射方式在机器数量变化时,会在很大程度上破坏原来的映射关系,及其不稳定。
回到上面的环形空间,如果能将机器映射到环形空间上,有 N 台机器,就将环形空间分为 N 个弧,每个弧占原来的区间的一部分。

如上,将环形空间分为了三个弧,也是三个区间。假设各个区间的范围为
- n1:[0, 2^10],
- n2:[2^10 + 1, 2^20]
- n3:[2^20 + 1, 2^32]
n1, n2,n3 的值可以用Hash(机器IP)得到,一般哈希函数会使其哈希值均匀地落到环上,对应的上面的区间值会变化,但还是会将环分为三个区间。
当有 key 存入时,Hash(key)得到的哈希值,落在哪个区间,那么就将这个 key 存放到对应区间的机器上。
当 n3 退出了集群,Hash(key)的值不会变, Hash(n1机器IP)和Hash(n2机器IP)当然也不会变,也就是说原来落到 n1 或 n2 机器上的 key 的映射关系不会变化。变化的只有之前落到 n3 机器上的 key。
n3 退出集群之后,环形空间就被分为了两个:
- n1: [0, 2^10]
- n2: [2^10 + 1, 2^32]
结果是:
- 原来落到 n3 上的 key,会落到 n2 上
- 原来落到 n2 上的,还是落到 n2 上
- 原来落到 n1 上的,还是落到 n1 上
可以看到,影响是很有限的,只有部分 key 受到影响,当集群机器数量较多时,受影响的 key 会更少。
当集群中有一个新的机器加入时,环形区间会被分成 4 个弧,也就是原来的一个区间被一分为二,这样也只会影响原来某个弧形中的一部分 key。
核心原理,便是这样,不同的实现会有所差异,有很多资料介绍区间的划分是顺时针转动,我想核心原理是类似的。集群中,为了使 key 尽量分散在环形空间中,还会引入虚拟节点。一个实际节点,会对应一个或多的虚拟节点,用虚拟节点将环形空间分为均匀的多个弧,然后 key 会落到虚拟节点对应的弧上。虚拟节点实际上又是和实际节点对应的,最终还是落到了对应的实际节点上,只不过会更加均匀,中间用虚拟节点转了一层,具体的细节可以查询资料,一看便明白。
结语
终于要收尾了,在心里组织这些知识,只花了很短的时间。但是当慢慢地将这些东西用文字表达出来时,耗费的时间增加了无数倍。一方面在知识的深度和广度上拿捏不准,自己在某些点上储备还有限。另一方面,要将某个知识点或者逻辑,用浅显的文字简单清晰地表达出来还是很考验功力,这方面,道路漫长。
最后,希望大神们不吝赐教,指出文中存在错误或不足的地方。
