新手问题 申手党:Nokogiri 如何搞定这个文本?
唉~从何说起呢? 万恶的谷歌服务器又宕机。向群里伸手只学了个开头,不得已啊只能来这申手。 按《提问的智慧》我在百度渡了一阵子,那形式啊走走也是走了啊,对不对? 然后,心安理得地来到这儿,开始发问:::::
我的文本是这个样子的:
<whcd>第一列</whcd><lxdh>第二列</lxdh><dwxs>第三列</dwxs> ...
<whcd>第一列</whcd><lxdh>第二列</lxdh><dwxs>第三列</dwxs> ...
<whcd>第一列</whcd><lxdh>第二列</lxdh><dwxs>第三列</dwxs> ...
<whcd>第一列</whcd><lxdh>第二列</lxdh><dwxs>第三列</dwxs> ...
我的目的是提取所有行部分列的值,我想用 file.each do |line| 逐行处理,感觉有点笨。 群里热心的大佬教我用 Nokogiri,我补习了一小时左右,根据一个例子(XML)搞了几下,卡着拉。
irb(main):001:0> require 'nokogiri'
=> true
irb(main):002:0> @doc = Nokogiri::XML(File.open("27065"))
=> #<Nokogiri::XML::Document:0x15619bc name="document" children=[#<Nokogiri::XML::Element:0x1561584 name="SBJGBH" children=[#<Nokogiri::XML::Text:0x15612a0 "37172713">]>]>
irb(main):003:0> @doc.xpath("/SBJGBH")
=> [#<Nokogiri::XML::Element:0x1561584 name="SBJGBH" children=[#<Nokogiri::XML::Text:0x15612a0 "37172713">]>]
irb(main):004:0> @doc.xpath("/ZGLB")
=> []
irb(main):005:0>
只能 xpath 第一列的数据,搞不到第二列和其它列。 我估计是不是我的文件不是个 XML 文件的问题,还是哪儿用错了吗?
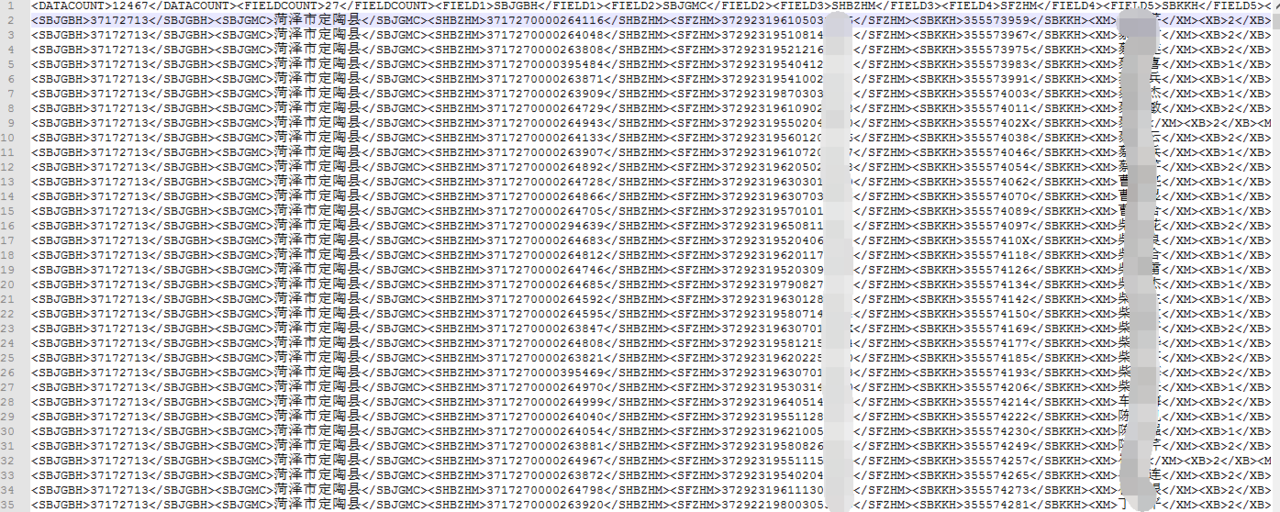 而我们只需要其中的部分字段而且用“|”分割,才能导入到我们的系统。几万行数据,本来用 vi 能搞定,用 sed 和 awk 也能搞定,但我更想用 ruby 搞定,而且我还想用 rails 做成 web 搞定,以后用起来更方便。因为有百多家银行都要转换它。
唉,先慢慢来吧!
而我们只需要其中的部分字段而且用“|”分割,才能导入到我们的系统。几万行数据,本来用 vi 能搞定,用 sed 和 awk 也能搞定,但我更想用 ruby 搞定,而且我还想用 rails 做成 web 搞定,以后用起来更方便。因为有百多家银行都要转换它。
唉,先慢慢来吧!