Ruby 几道有趣的 leetcode 题目
今天刚刚做完第 200 道 leetcode 题目。说说自己的感受,并分享两道有趣的题目。
1.运行时间排名 只有相同语言的排名才有意义。我原先以为 ruby 比 python 快,有时确实如此,但也不确定。前几天看了个 leetcode 的 discuss 帖子,说某题用 python 比 C++ 要快很多----都知道 C、C++ 在时间排名上一般总高于其他语言。系统管理员 1337coder 的回复大概是与机器等配置有关,用户不宜以此和其他语言做对比。
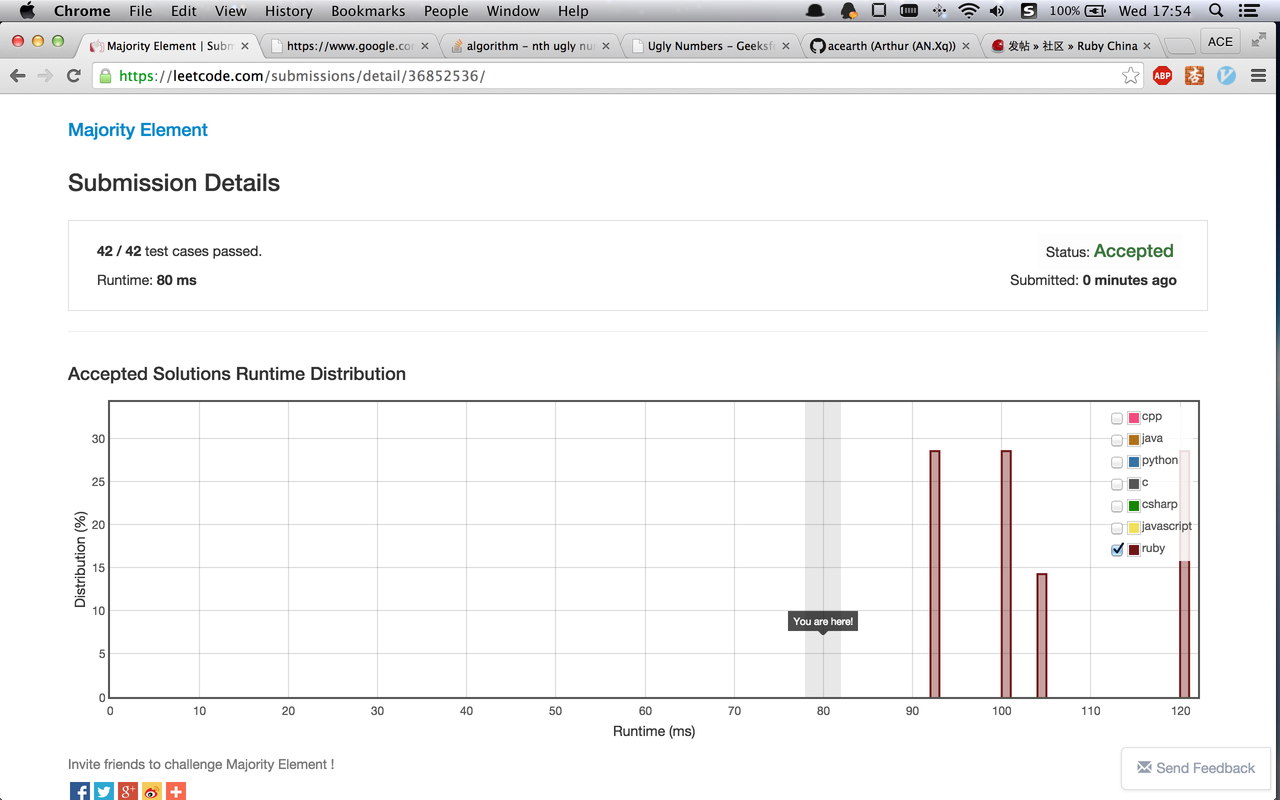
运行时间排名十分不稳定,这可能与目前 ruby 的提交量太少有关,但也与服务器有关。我的猜测是,如果有相邻两个时间分布式相同的,那得到这两种分布的概率是相同的。比如下图,92ms 和 104ms 的运行时间有相同的分布。如果这次运行时间是 92ms,下次也可能是 104ms。
- 做题训练很有价值
这两百道题,至少有 170 道题目是自己想出来然后一行行 coding 提交 AC 的。现在回顾前面一百题,已经感觉自己原先的方法十分拙劣了。这算是做题的一个收获。
3.两道有趣的题目 3.1 majority elements 求一个元素中出现次数最多的元素。这个题目的常规解法是使用优化后的动态规划。遍历一遍数组得到结果。但一个更有效的方法是排序。先上代码
def majority_element(nums)
nums.sort[nums.size/2]
end
其实上面的分布图就是该题使用排序法得到的结果,该法的运行时间明显优于其他方法。但是排序时间复杂度为 O(nlogn),为何这里特别快? 记得库函数中的 sort 方法都是三路快排加插入排序。在该题中,由于至少有一般的元素是相同的,所以插入的过程应该是直接插入尾部,这样时间几乎接近线性。但和传统方法比又少了若干次比较,所以更快。该法思路来源于同组同学。
3.2 find first missing one. 找出一个乱序数组中缺少的第一个正数。如 [4, 0 ,3,1] 缺少的第一个正数是 2。 这题一般的思路是直接将正数值放入其对应下标,然后按序遍历数组,找到和值不对应的下标即为所缺。但这样仍然需要多次比较和读写数组(尽管是线性复杂度)。本人的思路如代码所示:
def first_missing_positive(nums)
oldBase, base=0,0
arr=[nums,nums.reverse]
i=0
loop do
arr[i].each { |e| base=e if e==base+1 }
break if base==oldBase
oldBase,i=base,1-i
end
return base+1
end
首先记录当前已有的值(初始为零),然后按序遍历数组,如果 1 出现了,就找 2,2 出现了就找 3,直到找到为止。为了加速移动,并应对数组已经有序的情况,在正序遍历数组后再逆序遍历数组。和常规方法相比,该法的复杂度是 O(n*n)。但只要输入序列不是锯齿状(如快排的 killer adversary, 又如 [2,4,1,3]),该法在除锯齿状数据的情况以外运行时间都很短。在随机产生数据的前提下,我对两种思路的数据都做了实验,O(n*n) 的解法要快于 O(n) 法。但如果数据是用 knuth shuffle 洗牌的思路生成随机数组(如 [4,2,1,3]),只是将原组做了交换,缺失值为最大值的情况下,该法将产生很多循环,运行效果变差(在对 10000 个连续值 shuffle 后的数组处理)。用这种思路解题,运行时间 76ms,和其他方法的最优时间相同。
最后感谢关注了 leetcodePractice 的各位朋友,是你们带给我更大动力。特别感谢@quakewang,对我提出了许多批评的同时展示了许多书写良好的代码。
本人 LeetcodePractice 项目地址:https://github.com/acearth/LeetCodePractice
欢迎批评和关注!