数据库 [已解决] select count (*) from table_name 为什么没有使用主键索引?
今天在测试索引的时候碰到一个十分诡异的问题,百思不得其解。
表结构
- 主键索引
- token 的索引
devices_token - token 的前置索引
devices_token_prefix_index
我创建了一个只有两个字段、三个索引的测试表。
CREATE TABLE `devices` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`token` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `devices_token` (`token`),
KEY `devices_token_prefix_index` (`token`(15))
) ENGINE=InnoDB AUTO_INCREMENT=67828774 DEFAULT CHARSET=utf8;
插入了 6000 万条测试数据后,表的大小为 8G。
诡异事件
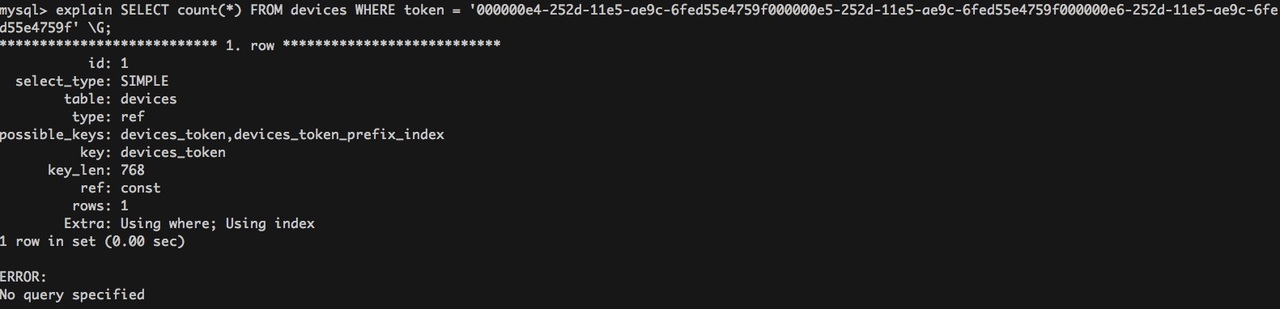
我想看一下数据库已经插入了多少条记录,就做了一个简单的查询
select count(*) from devices
结果整整花了 9s 的时间(这种简单的查询如果使用 primary key 的话,应该只有 0.5ms 之内)
我百思不得其解,explain 一下,结果发现这个查询语句压根没有使用 primary key,而是使用了前置索引 devices_token_prefix_index。MySQL 的这种行为怎么这么古怪?

无引用文章