数据库 PostgreSQL 与 MySQL 的性能
目前在项目中遇到的问题是 mysql 在数据量稍大点(3000w 行)的时候查不动了~~想换存储,以前木有用过 PostgreSql。在网上查了下资料,怎么都说 postgre 的查询速度不怎么样啊。请教用过 pg 的人,postgre 在数据量膨胀很快的时候,是怎么解决的?以及其查询效率是不是的确很慢?
参加过一个项目,数据量在千万级别,用 pg 做的存储。查询速度确实慢。简单的优化做了下,比如索引,问题没有彻底解决。后来干脆就不用 pg 做查询了,把查询工作都转移到搜索引擎中去了(用的是 sphinxsearch),pg 就只做存储和按主键读取。正好项目中没用到什么 join 查询,搜索引擎也够用了。问题算是解决了。 我觉得 pg 优化得好,应该可以支撑到亿级别的数据的快速查询。关键是没有那么牛逼的 DBA。很多时候得自己另外想办法提升速度。
如果索引字段不多,可以用 redis 查到 id,然后用 id 查 mysql 的表,这个速度还是可以保证的。
另外,如果可能的话,可以考虑数据冗余生成结果表,最后变成“索引 -> 搜索结果”的键值对,如果更新数据,同时也更新这个结果表。
数据大了肯定要分库分表的,这里建议先分表,3000 万,大概 mod(4),也就是放四张表中,这是一个简单的拆分策略。时间上:理论就是一个取模运算后就去查表,所以肯定会快几倍。
至于索引,创建索引的最主要目的其实就是为了增加查询速度,采用了优化的算法结构,具体的我就是门外汉了,可以查看下索引原理。
其实简单手段还是 explain 一下,看看到底是哪里慢了,可能删个没必要的索引或者加个索引避免全表扫描,或者修正 N+1 就好了...
#5 楼 @winnie 其实是我扯远了,手动分表也是有其好处...
#6 楼 @small_fish__ 是说 sort id? uuid 就不是顺序产生的了,不过有插入时间可以排序吧?
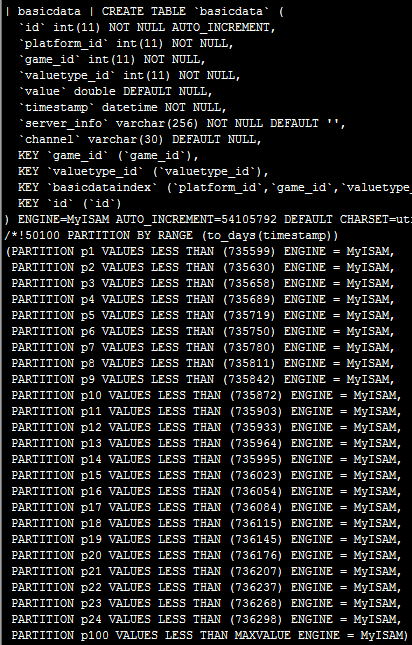
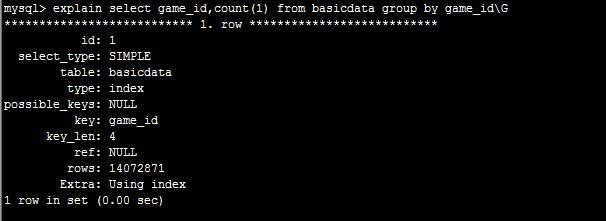
#19 楼 @bobby_chen 你这样是全表扫描,用什么都慢的拉!就算对 game_id 加上了索引,也没什么用!你还不如做一下 counter cache。
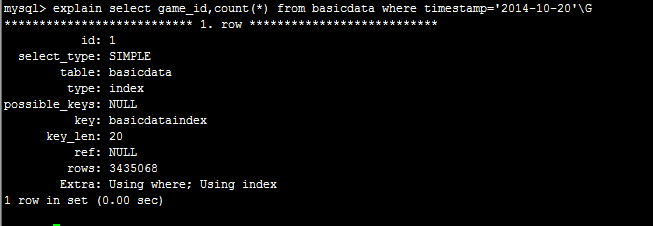

表结构一般都是为了 OLTP 优化设计的,千万级别的数据,如果查询无法有效利用索引,或者需要 scan row 数量过大,PostgreSQL 和 MySQL 都无法提供很好的性能。用 OLAP 吧。
之所以慢,都是因为这个操作其计算量大的原因。只需要将计算量降下来,或者提前一次性做好这件事情就可以了。
我给你的建议是,新建一张表,然后你对每一个 game_id 每天生成一条 count(*) 记录,然后存起来就可以了。
#9 楼 @bobby_chen 简单的聚合计算支持,复杂的不行。
http://sphinxsearch.com/docs/current.html#clustering
Starting with version 0.9.9-rc2, aggregate functions (AVG(), MIN(), MAX(), SUM()) are supported through SetSelect() API call when using GROUP BY.
MariaDB [test]> EXPLAIN SELECT `game_id`, count(`game_id`) FROM `basicdata` WHERE `timestamp` = '2012-04-15' GROUP BY `game_id`\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: basicdata
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 3071957
Extra: Using where; Using temporary; Using filesort
1 row in set (0.00 sec)
MariaDB [test]> CREATE INDEX `index_1` ON `basicdata` (`timestamp`, `game_id`);
Query OK, 3071957 rows affected (26.18 sec)
Records: 3071957 Duplicates: 0 Warnings: 0
MariaDB [test]> EXPLAIN SELECT `game_id`, count(`game_id`) FROM `basicdata` WHERE `timestamp` = '2012-04-15' GROUP BY `game_id`\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: basicdata type: ref
possible_keys: index_1
key: index_1
key_len: 8
ref: const
rows: 44
Extra: Using where; Using index
1 row in set (0.00 sec)
特地给你建了一个环境试的。
#35 楼 @bobby_chen 还请你好好研究一下 索引 这个东西本身。
SQL 查询如果没有合适的索引就会扫全表。
你上面的例子就是典型。
WHERE子句里第一个条件是timestamp = ?,然后GROUP BY是game_id (虽然你原句里没写GROUP不过这样原则上是病句)
那么只有在有 (timestamp) 索引的情况下才能利用到索引。
而最佳的情况是有 (timestamp, game_id)`,这样就能完全利用索引来计算。
你的问题不是索引太多,而是索引没有跟着需求走。建议你先列出要用到的查询语句,看下每个语句要用到的列,然后再根据实际需要去建立索引。
以下是只有timestamp索引的情况。虽然用了索引但是还是要局部扫表。
MariaDB [test]> EXPLAIN SELECT `game_id`, count(`game_id`) FROM `basicdata` WHERE `timestamp` = '2014-10-15' GROUP BY `game_id`\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: basicdata
type: ref
possible_keys: index_1
key: index_1
key_len: 8
ref: const
rows: 94
Extra: Using where; Using temporary; Using filesort
1 row in set (0.00 sec)
是这个样子。局部扫表 这个词还是第一次听说...... 但 game_id 上有没有索引和是否扫描关系不大,过滤的只是 timestamp,只要有 timestamp 的左前缀索引都是会走索引。
你这两个主要差异在排序上:
- Using index 覆盖索引,因为第一个 [timestamp, game_id] 上有索引,并且也只 select 了这两个列。
- Using filesort 进行了排序,有 group 子句都要排序,第一个没排是因为索引加在 [timestamp, game_id] 上并且 timestamp 为常量之后 game id 本身在 BTree 上就有顺序。似乎加上 order by null 可以避免(未试过..)。
PS1. 楼主的查询用了索引..
PS2. 楼主用的是 MyIsam
PS3. 针对楼主的这句查询,加一个 Game 表(估计已经有了),设置 counter cache,select id, basicdata_count from games一句话搞定。
因为 [timestamp, game_id] 上有索引的情况下,只读取索引就可以得到结果,所以完全不用读数据表了。第二种情况是只用索引来搜索数据,所以用了索引但是还是要用去数据表里搜出所有的数据来做聚合运算。虽然速度不慢但是会增加 I/O。倒不如说,其实把 game_id 放进联合索引就是相当于做了半个 counter_cache。
对于楼主的两条查询 EXPLAIN,可以看到 possible_keys 都是 NULL,而 keys 则有索引。这种情况官网解释为:
It is possible that key will name an index that is not present in the possible_keys value. This can happen if none of the possible_keys indexes are suitable for looking up rows, but all the columns selected by the query are columns of some other index. That is, the named index covers the selected columns, so although it is not used to determine which rows to retrieve, an index scan is more efficient than a data row scan.
另外,我用的是 Aria,想来 MyISAM 应该会是同样的结果。