分享 ElasticSearch 导入数据的一个坑,肯定不止我一人中招
今天使用 ES 时,碰到一个坑,估计其他同学或许也会碰到,特此分享一下。
step 1 Model
- BetOrder 是一个订单的 model,搜索时我打算使用 term query。我把 mapping 设置为
index: 'not_analyzer',故意不分词,以便精确搜索。 - Gem 用的是 elasticsearch-rails
# model/bet_order.rb
# Set up index configuration and mapping
# Searching tokens exactly
settings do
mappings do
indexes :title, index: 'not_analyzed'
indexes :nickname, index: 'not_analyzed'
indexes :user_key, index: 'not_analyzed'
indexes :out_trade_no, index: 'not_analyzed'
indexes :trade_no, index: 'not_analyzed'
indexes :buyer_email, index: 'not_analyzed'
end
end
step 2 导入数据
BetOrder.import
step3 悲剧了,导入数据后 mapping 不对
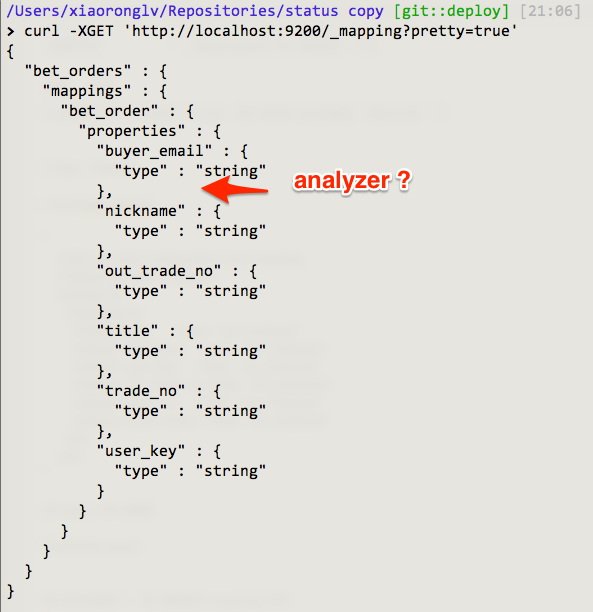
然后是 debug 呀,debug。。。。。
翻来覆去的找,没找到原因,最后去翻了翻 elasticsearch-rails 的源码,原来导入数据的时候需要加上参数 force: true,才会根据 mapping 创建索引。
BetOrder.import force:true
源码地址:
问题解决,上一个正常 mapping
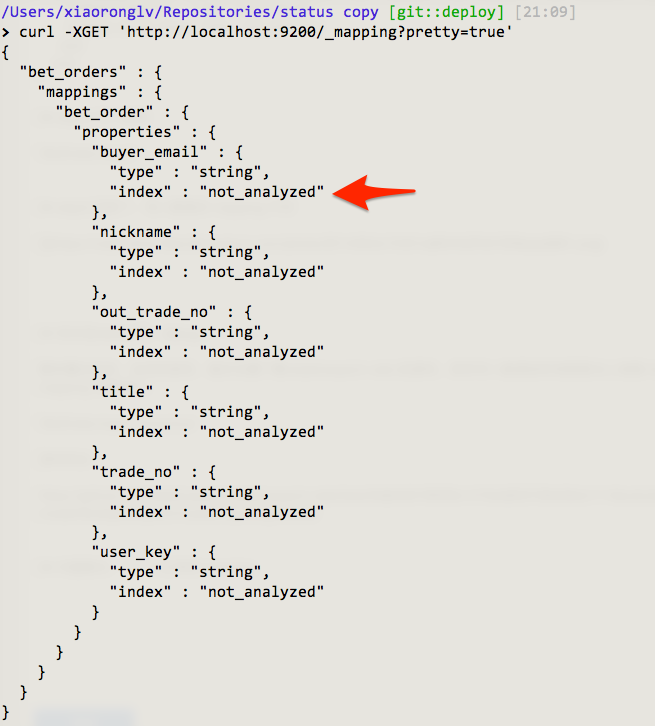
顺便请教一个问题:为什么第一次 import 数据时,作者不根据 model 中定义的 mapping 创建。这算不算一个 bug?