分享 聊聊 Ruby 中的 block, proc 和 lambda
做为热身,从一些简单的例子开始,
def f1
yield
end
def f2(&p)
p.call
end
def f3(p)
p.call
end
f1 { puts "f1" }
f2 { puts "f2" }
f3(proc{ puts "f3"})
f3(Proc.new{puts "f3"})
f3(lambda{puts "f3"})
若你用的是 ruby1.9 及以上的版本,还可以这样,
f3(-> {puts "f3"})
上面是 block, proc 和 lambda 的一些基本用法。
block
先说说 block, ruby 中的 block 是方法的一个重要但非必要的组成部分,我们可以认为方法的完整定义类似于,
def f(零个或多个参数, &p)
...
end
注意&p 不是参数,&p 类似于一种声明,当方法后面有 block 时,会将 block 捕捉起来存放到变量 p 中,如果方法后面没有 block,那么&p 什么也不干。
def f(&p)
end
f(1) #=> 会抛出ArgumentError: wrong number of arguments (1 for 0)异常
f() #=> 没有异常抛出
f() { puts "f"} #=> 没有异常抛出
从上面代码的运行结果可以知道&p 不是参数
def f(a)
puts a
end
f(1) { puts 2} #=> 没有异常抛出,输出1
所以任何方法后面都可以挂载一个 block,如果你定义的方法想使用 block 做点事情,那么你需要使用 yield 关键字或者&p
def f1
yield
end
def f2(&p)
p.call
end
此时 f1, f2 执行时后面必须挂一个 block,否则会抛出异常,f1 抛出 LocalJumpError: no block given (yield) 的异常,f2 抛出 NoMethodError: undefined method 'call' for nil:NilClass 的异常,ruby 提供了block_given?方法来判断方法后面是否挂了 block,于是我们可以这样修改 f1 和 f2,
def f1
yield if block_given?
end
def f2(&p)
p.call if block_given?
end
这样的话,f1 和 f2 后面无论挂不挂 block 都不会抛异常了。 我们再来看看 f2 修改前抛出的 NoMethodError: undefined method 'call' for nil:NilClass 异常,这种说明当 f2 后面没有挂 block 的时候 p 是 nil,那么我们给 f2 挂个 block,再打印出 p,看看 p 究竟是什么,
def f2(&p)
puts p.class
puts p.inspect
p.call
end
f2 {} # 输出Proc和类似<Proc:0x007fdc72829780@(irb):21>
这说明 p 是一个 Proc 实例对象,在 ruby 中,&还可以这么用,[1,2] & [2,3] 或者 puts true if 1 && 1 或者在某个类中将它作为一个方法名。
很多 ruby 老鸟会写类似下面的代码,
["1", "2", "3"].map(&:to_i),其效果和["1", "2", "3"].map {|i| i.to_i }一样,但简洁了许多,并且更加拉风。
这里的魔法在于符号&会触发:to_i 的 to_proc 方法,to_proc 执行后会返回一个 proc 实例,然后&会把这个 proc 实例转换成一个 block,我们需要要明白 map 方法后挂的是一个 block,而不是接收一个 proc 对象做为参数。&:to_i 是一个 block,block 不能独立存在,同时你也没有办法直接存储或传递它,必须把 block 挂在某个方法后面。
:to_i 是 Symbol 类的实例,Symbol 中的 to_proc 方法的实现类似于,
class Symbol
def to_proc
Proc.new {|obj| obj.send(self) }
end
end
同理我们可以给自己写的类定义 to_proc 方法,然后使用&耍下酷,比如,
class AddBy
def initialize(num = 0)
@num = num
end
def to_proc
Proc.new {|obj| obj.send('+', @num)}
end
end
add_by_9 = AddBy.new(9)
puts [1,2,3].map(&add_by_9) #输出 [10, 11, 12]
在 ruby 中,block 有形,它有时候是这样
do |...|
...
end
有时候是这样
{|...| ...}
或者类似 &p, &:to_i, &add_by_9 之类,但是它无体,无体的意思就是说 block 无法单独存在,必须挂在方法后面,并且你没有办法直接把它存到变量里,也没有办法直接将它作为参数传递给方法,所以当你想存储,传递 block 时,你可以使用 proc 对象了,
p = Proc.new(&:to_i)
p = Proc.new {|obj| obj.to_i }
p = Proc.new do |obj|
obj.to_i
end
p = proc(&:to_i)
p = proc {|obj| obj.to_i}
p = proc do |obj|
obj.to_i
end
def make_proc(&p)
p
end
p = make_proc(&:to_i)
p = make_proc do |obj|
obj.to_i
end
p = make_proc {|obj| obj.to_i }
虽然我在开发中经常用到 block,但是我很少显式地去使用 Proc 或 proc 去实例化 block,比如我几乎没有写过这样的代码,
f(Proc.new {|...| ...})
f(proc {|...| ...})
p = Proc.new {|...| ...} #然后在某个地方p.call(...)或者将p传递给某个方法,比如f(p)
在使用 block 时,我会忽略 proc 的存在,我将 proc 定位为一个幕后的工作者。我经常写类似下面的代码,
def f(...)
...
yield
...
end
def f(..., &p)
...
p.call
...
end
def f(..., &p)
instance_eval &p
...
end
def f(..., &p)
...
defime_method m, &p
...
end
有些新手会写类似下面的一执行就会报错的代码,
def f(..., &p)
instance_eval p
end
def f(..., p)
instance_eval p.call
end
也有这样写的,
def f(..., &p)
instance_eval do
p.call
end
end
或者
def f(...)
instance_eval do
yield
end
end
我甚至写过类似下面的代码,
def f(...)
instance_eval yield
end
我们经常在该挂 block 的时候,却把 proc 对象当参数传给方法了,或者不明白&p 就是 block 可以直接交给方法使用,我曾经也犯过这样的错误就是因为没有把 block 和 proc 正确的区分开来,&p 是 block, p 是 proc,不到万不得已的情况下不要显式地创建 proc,每当我对 block 和 proc 之间的关系犯糊涂时,我就会念上几句。
再来聊聊 yield 和&p,我们经常这样定义方法,
def f(...)
yield(...)
end
def f(..., &p)
p.call(...)
end
yield 和 call 后面都可以接参数,如果你是这样定义方法
def f(...)
yield 1, 2
end
那么可以这样执行代码,
f(...) do |i, j|
puts i
puts j
end
但是这样做也不会有错,
f(...) do
...
end
p.call(...) 的情况类似,也就是说 block 和 proc 都不检查参数 (其实通过 proc 方法创建的 proc 在 1.8 是严格检查参数的,但是在 1.9 及以上的版本是不检查参数的),为什么 block 和 proc 不检查参数呢?其实这个很好理解,因为在实际应用中你可能需要在一个方法中多次调用 block 或者 proc 并且给的参数个数不一样,比如,
def f()
yield 0
yield 1, 2
end
def ff(&p)
p.call 0
p.call 1, 2, 3
end
f do |a1, a2, a3|
puts a1
puts a2
puts a3
end
由于方法后面只能挂一个 block,所以要实现上面的代码功能,就不能去严格检查参数了。
转入正题,这两种方式效果差不多,都能很好地利用 block。使用 yield,看起来简洁,使用&p,看起来直观,并且你可以将&p 传给其他方法使用。 但是在 ruby1.8 的版本你不应像下面这样做,
def f1(...)
eval("yield")
end
可以,
def f2(..., &p)
eval("p.call")
end
f1(...) {} # 会抛异常
f2(...) {} # 正常运行
当然上面这种用法很少见,但是却被我碰到了,我经常写一些方法去请求外部的 api,有时这些外部的 api 不是特别稳定,时不时会遇到一些 bad respoense, timeout 错误,针对这些错误,应该立即重发报文重试,对于其他异常就直接抛异常。于是我写了一个 try 方法来满足这个需求,
def try(title, options = { }, &p)
ee = '#{e}'
tried_times = 0
max_times = options[:max_times] || 3
exceptions = options[:on] || Exception
exceptions = [exceptions] if !exceptions.is_a?(Array)
rescue_text = <<-EOF
begin
p.call
rescue #{exceptions.join(',')} => e
Rails.logger.info("#{title}发生异常#{ee}")
if (tried_times += 1) < max_times
Rails.logger.info("开始重试#{title}--第#{tried_times}次重试")
retry
end
raise e
end
EOF
eval rescue_text
end
try('某某api', :max_times => 2, :on => [Net::HTTPBadResponse, Timeout::Error]) do
open(api_url)
end
最开始我用的是 yield,结果在 ree 下执行 try 方法时会报错,后来改成使用&p 就通过了。
通过试验发现在 ruby1.9 及以上版本已经没有这种差异了。
做个小结, block 和 proc 是两种不同的东西,block 有形无体,proc 可以将 block 实体化,可以把&p 看做一种运算,其中&触发 p 的 to_proc 方法,然后&会将 to_proc 方法返回的 proc 对象转换成 block 。
其中 proc 对象的 to_proc 方法返回自身。
p = proc {}
p.equal? p.to_proc # 返回true
lambda
lambda 是匿名方法,lambda 和 proc 也是两种不同的东西,但是在 ruby 中 lambda 只能依附 proc 而存在,这点和 block 不同,block 并不依赖 proc。
l = lambda {}
puts l.class
在 ruby1.8 中输出的信息类似#Proc:0x0000000000000000@irb):1(
在 ruby1.9 及以上版本输出的信息类似#Proc:0x007f85548109d0@irb):1lambda)(,注意 1.9 及以上版本的输出多了 (lambda),从这里可以理解 ruby 的设计者们确实在有意的区分 lambda 和 proc,并不想把 lambda 和 proc 混在一起,如同 ruby 中没有叫 Block 的类,除非你自己定义一个,ruby 中也没有叫 Lambda 的类,于是将 lambda 对象化的活儿就交给了 Proc,于是令人头大的情况出现了,当你用 lambda 弄出了一个匿名方法时,发现它是一个 proc 对象,并且这个匿名方法能干的活,proc 对象都能做,于是我们这些码农不淡定了,Proc.new {}这样可以,proc {}这样也没有问题,lambda {}这样做也不错,->{}这个还是能行,我平时吃个饭都为吃什么左右为难,现在一下子多出了四种差不多的方案来实现同一件事情,确实让人不好选择,特别是有些码农还有点小洁癖,如果在代码里一会儿看到proc{}, 一会儿看到lambda{},这多不整洁啊,让人心情不畅快。在这里我们认定 lambda 或者 -> 弄出的就是一个匿名方法,记做 l, 即使它披着 proc 的外衣,proc 或者 Proc.new 创建的就是一个 proc 对象,记做 p 在 ruby 各个版本中,l 和 p 是有一些差别的。
定义一些方法,
def f0()
p = Proc.new {return 0}
p.call
1
end
def f1()
p = proc { return 0 }
p.call
1
end
def f2()
l = lambda { return 0}
l.call
1
end
def f3(p)
instance_eval &p
1
end
class A
end
def f4(p)
A.class_eval &p
1
end
p1 = Proc.new { }
p2 = proc {}
l = lambda {}
def f5()
yield 1, 2
end
f5 {}
f5 {|i|}
f5 {|i,j|}
f5 {|i,j,k|}

lambda 和 proc 之间的区别除了那个经常用做面试题目的经典的 return 之外,还有一个区别就是 lambda 不能完美的转换为 block(这点可以通过 f3 和 f4 执行的过程得证),而 proc 可以完美的转换为 block,注意,我说的 lambda 指的是用 lambda 方法或者->符号生成的 proc,当然和方法一样 lambda 是严格检查参数的,这个特点也和 proc 不一样。
从上面的数据对比来看,在 1.8 版本,lambda 和 proc 方法生成的 proc 对象的行为是一致的,但在 1.9 以上和 jruby 的版本中,lambda 和 proc 的不同处增多,可以认为 ruby 的设计者们并不想把 lambda 和 proc 混同为一件事物。如我前面所讲,proc 的主要作用是对象化 block 和 lambda,并且 proc 在行为上更接近于 block。
retrun 的几个试验
def f0()
p = Proc.new { return 0}
p.call
1
end
def f1()
l = lambda { return 0}
l.call
1
end
f0 # 返回0
f1 # 返回1
如果你能够理解 proc 在行为上更像 block,lambda 其实就是方法只不过是匿名的,那么你对上面的结果不会感到惊讶。
如果把 f0,f1 做一些修改,就更容易理解上面的结果了。
def f0()
return 0
1
end
def f1()
def __f1
return 0
end
__f1
1
end
f0 # 返回0
f1 # 返回1
return 只能在方法体里执行,
p = Proc.new { return 0 }
l = lambda { return 0 }
p.call # 报LocalJumpError
l.call # 返回0
构造 p 的时候我没有使用 proc {return 0},因为在 ruby1.8 中,proc {return 0}的行为和 lambda 一样,比如在 ruby1.8 中,
def f(p)
p.call
1
end
p = proc { return 0 }
l = lambda { return 0 }
f(p) # 返回1
f(l) # 返回1
p.call # 返回0
l.call # 返回0
def f(p)
p.call
1
end
p = Proc.new { return 0 }
l = lambda.new { return 0}
f(p) # 报LocalJumpError
f(l) # 返回1
我感觉 proc 中的 return 能记住 proc 生成时其 block 的位置,然后无论 proc 在哪里调用,都会从 proc 生成时其 block 所在位置处开始 return,有下面的代码为证:
def f(p)
p.call
1
end
def f2()
Proc.new { return 0 }
end
def f3()
lambda { return 0 }
end
p = f2()
l = f3()
f(p) # 报LocalJumpError: unexpected return,from (irb):29:in `f2'
f(l) # 返回1
我在 1.8, ree, jruby, 1.9, 2.0 各版本都测试过,结果一样。
再看看下面的代码,
def f0(&p)
p.call
1
end
def f1()
yield
1
end
f0 { return 0} # LocalJumpErrorw
f1 { return 0} # LocalJumpErrorw
f0(&Proc.new{return 0}) # LocalJumpError
f0(&lambda{return 0}) # 返回1
def f2(&p)
p
end
def f3()
p = f2 do
return 0
end
p.call
1
end
f3 # 返回0
我们重点看看 f3 中的 proc p,它虽然是从 f2 中生成返回的,但是 p 生成时其 block 是处在在 f3 的方法体内,这个类似于,
def f3()
p = Proc.new { return 0}
p.call
1
end
所以执行 f3 时,没有异常抛出,返回 0。
总结
当你想写出类似于 f do ...; end 或者 f {...}的代码时,请直接使用 block,通过 yield, &p 就能达到目的,当你想使用 proc 时,其实此时绝大部分的情况是你实际想用 lambda,请直接使用 lambda{}或者->{}就可以了, 尽量不要显示地使用 Proc.new{} 或者 proc{}去创建 proc。
废话说了一大堆,其实我最想说的是:用 block,用 lambda,不要用 proc,让 proc 做好自己的幕后工作就好了。
 Proc 里写 return 会把 call Proc 的方法直接 return 掉是一个很奇怪的设计,一直被我认为违反了代码结构化。
Proc 里写 return 会把 call Proc 的方法直接 return 掉是一个很奇怪的设计,一直被我认为违反了代码结构化。
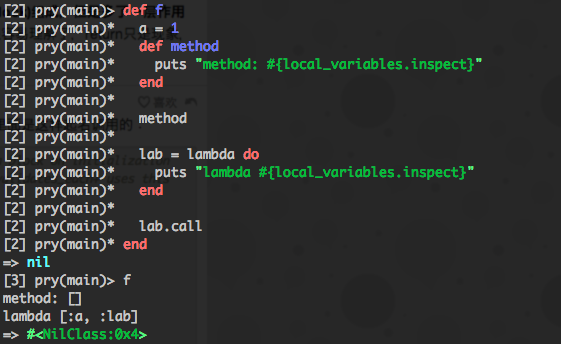 否则这里 lambda 里的 local variable 也不应该包含 a 才对。。
否则这里 lambda 里的 local variable 也不应该包含 a 才对。。