-
Merry Christmas 皆さん at 2013年12月25日
In fact, I do not understand Japanese, this word is translated by Google. 実際に、私は日本語が理解できない、この単語は、Google で翻訳されています。
-
让爬虫轻松一点~(一) at 2013年12月23日
这不太合适吧~ , 你自己也说了这么干
有违业界规范,怎么话锋一转 , 自己却干起这勾当了 ... -
PHP 中国社区 at 2013年12月04日
楼主 , 我该点什么 ?
-
难道 Ubuntu 才是开发 Rails 的最佳环境? at 2013年12月03日
Mac和Ubuntu都很好 , 在这两个之一开发都完全没有问题 , 选择一个合适你的才重要 . 在Mac平台安装Ubuntu是件很蛋疼的事情 , 楼主请自重 . 虚拟机也算了吧 .... -
用 Node-webkit 来解决企业应用浏览器兼容问题 at 2013年11月29日
-
RubyConfChina 2013 大会照片收集 at 2013年11月29日
-
RubyConfChina 2013 大会照片收集 at 2013年11月29日
@lgn21st @rei @huacnlee 快
ban掉 @thunder3721 ...... -
[黑色星期五] 效率型工具 Manico 66% 折扣,现在仅 6 元人民币 at 2013年11月29日

早就想买了 ... 支持

-
用 Node-webkit 来解决企业应用浏览器兼容问题 at 2013年11月29日
-
RubyConfChina 2013 大会视频 (更新下载链接) at 2013年11月29日
-
部署 unicorn 上的时候发生 at 2013年11月29日
#2 楼 @shangrenzhidao 恩 , 好多了 ... 看看这个吧 Unicorn error: text file busy .
-
部署 unicorn 上的时候发生 at 2013年11月29日
代码没有格式化 , 没有看的欲望 ..... 我是不是病了 ?
-
关于数据库字段类型 text 的新发现 at 2013年11月29日
@Rei 即使加上代码格式化按钮了还是有人不懂格式化。
-
这就是响应式布局 at 2013年11月29日
这 ... , 好生动 ... , 这应该只是相对布局得到的结果 , 响应式布局应该考虑到当屏幕变小后个元素之间的摆放 , 至少应该合理 . 比如这个 轻松熊 , 已经像 哈士奇 了 ....
-
关于 CarrierWave 使用心得,抛砖引玉 at 2013年11月27日
Markdown 和
ruby没啥关系 . 推荐花几分钟了解下 . -
[北京] 天铭博锐 Ruby on Rails 工程师 at 2013年11月27日
这 ....
薪酬待遇:4K~8K
要饿死的节奏啊~~ , 这待遇估计新手 ( 没有歧视新手的意思 ) 都找不到吧~
-
类似淘宝的超多二级域名是怎么搞的。。 at 2013年11月27日
域名泛解析 , 将
*.taobao.com解析到服务器即可 . -
除了 wordpress,还支持高效率免费搭建博客的 sae 有哪些? at 2013年11月27日
SAE就算了吧 , 别这样对自己 . -
mysqld 占这么大内存 正常不 at 2013年11月27日
一般都是占满 .
看着用这么多的内存,心里不爽
这是病 , 得电~~~~ZZZ
-
Devdocs - 很棒的在线文档整合应用 at 2013年11月27日
看起来应该是生成文档的时候创建了
json形式的索引文件 (#26 楼 @linjunhalida 不是SQL数据库 ) , 然后通过CDN网络将manifest.appcache列表中的文件缓存到浏览器本地 然后解析json数据导入到了本地的Local Storage存储 .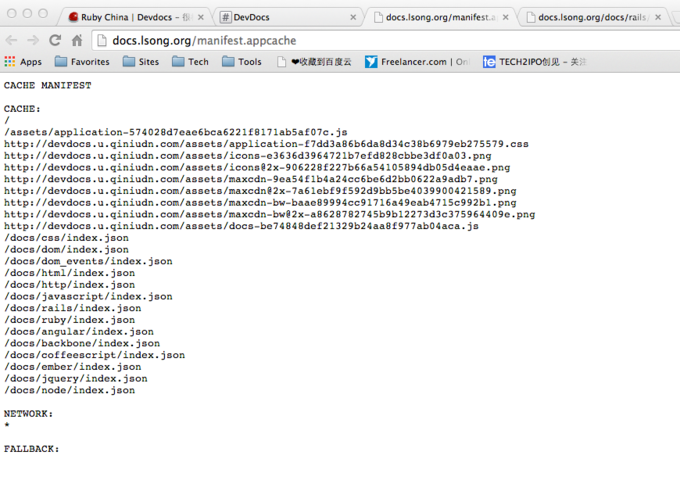
用户搜索时在
Local Storage中检索 , 发现符合的条目即读取对应条目的path属性 , 获得文档的真实路径的html文件显示出来 .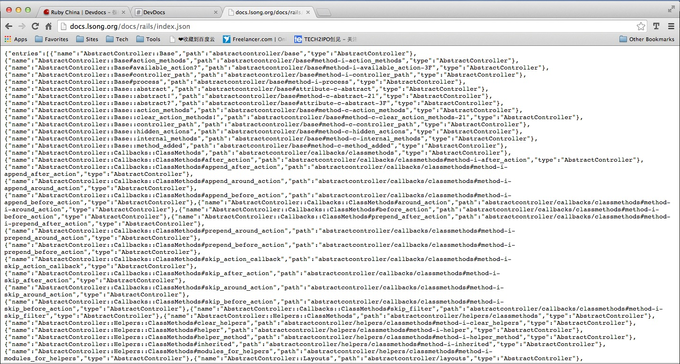
所以通过这些手段达到了比较理想的检索速度 .
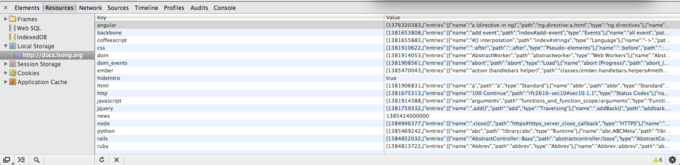
-
Devdocs - 很棒的在线文档整合应用 at 2013年11月26日
-
Life’ s too short to build something nobody wants. at 2013年11月26日
生命太短暂 , 以至于我们不愿意 (花太多时间) 做没有回报的事情 .
-
从 Ruby China 的登录表单来说 Devise 的问题:“记录登录状态” 不生效 at 2013年11月26日
#1 楼 @tyaccp_guojian 记住密码只是记住
用户名和密码, 并不能达到记住用户登录状态的能力 . 我没用过Devise, 但是看起来应该是它无论如何都写入了remember_token到cookie了 . -
关于 build 的问题 at 2013年11月26日
update_attributes(:product => params[:product])orupdate(params) -
关于 build 的问题 at 2013年11月25日
-
我大 RubyChina 为毛不自己做搜索,而是转向 Google 呢 at 2013年11月25日
Google是首选 , 由于Ruby-China很多高质量原创内容,所以收录非常快 . -
Mac 上用什么好的工具可以读取 SQL Server 的 MDF 数据库文件 at 2013年11月25日
VirtualBox:P . -
有没有人做过论坛爬虫? at 2013年11月25日
爬虫这些一般定制性都比较强 , 通常用 nokogiri 这个
gem来解析HTML实现 . 另外可以参考 @hooopo 同学的 https://github.com/hooopo/direct_web_spider 项目。 -
关于 rails 项目部署成功之后,访问是运行流程是什么? at 2013年11月25日
-
有白头发了,咋整呢? at 2013年11月25日
剃个光头就好了 ...







 .
. .
.