-
红宝石 大战 Hangman at 2013年12月17日
-
红宝石 大战 Hangman at 2013年12月17日
#1 楼 @small_fish__ 哈,长的部分其实就是测试结果,这样别人直接看也可以明白其中过程。我就是把项目的 README 贴过来了:)
明白基本规则后,算法的文档部分就在解题步骤。所以如果感兴趣的话,请直接看程序吧。
个人贴这里的想法就是看看是否有人能帮忙算出给定 data 目录里的任何单词,最差猜的次数在理论上可以最少到多少次,写成论文形式最好了!
-
为什么你应该永不用 MongoDB (转) at 2013年12月13日
-
乔布斯:遗失的访谈 (1995) at 2013年12月12日
很赞同和理解他说的关于创意执行和团队合作的理念。
"光凭创意不行,他认为只要想到一个绝妙的主意,公司就一定能实现,问题在于优秀的创意与产品之间隔着巨大的鸿沟,实现创意的过程中,想法会变化甚至变得面目全非,因为你会发现新东西,思考也更深入,你不得不一次次权衡利弊,做出让步和调整,总有些问题是电子设备解决不了的,是塑料,玻璃材料无法实现的,或者是工厂和机器人做不到,设计一款产品,你得把五千多个问题装进脑子里。必须仔细梳理,尝试各种组合,才能获得想要的结果。每天都会发现新问题,也会产生新灵感,这个过程很重要,无论开始时有多么绝妙的主意,"
和
"拥有个性四溢的成员必须打磨,精神碰撞,才能各个变成美丽的”石头“。最终得由你的品味来决定,你要熟悉人类在各种领域的优秀成果,尝试把它们运用到你的工作里。毕加索说,拙工抄,巧工盗。诗人,动物学家,即使在其他领域也能做出成果。"
-
海量日志分析方案 at 2013年12月12日
哈,其实我就是干这样事的。
虽然说原始数据有几百 G,但是也并不是不可压缩的,原则就是尽量采用可枚举值或整数,比如 IP 按整数存。具体可以参考我以前做的 Android 优亿市场数据采集分析系统概要 。
另外如果你的需求只是单表 Group By 的话(如果多表 Join,也可以对数据进行预处理成单表的),推荐采用 statlysis 这个分析引擎框架,特别适合 Mongoid/ActiveRecord 这两个 ORM,具体操作你看 README 就好了,统计出来的结果基本就对应到最终图表了。欢迎反馈:)
-
『思想的火花』12 月 21 日 周末场 -《为什么蝉游记只有一个后台程序员》&《火花 API 设计实践》 at 2013年12月12日
-
『思想的火花』12 月 21 日 周末场 -《为什么蝉游记只有一个后台程序员》&《火花 API 设计实践》 at 2013年12月10日
-
『思想的火花』12 月 21 日 周末场 -《为什么蝉游记只有一个后台程序员》&《火花 API 设计实践》 at 2013年12月10日
很正常,我之前也一个人负责在线学习产品的前后端程序部分, http://mvj3.github.io/2013/08/04/a-man-github/ 。
不过 Rails 程序员确实太忙了,每天工作满满的,不像前端或设计等有一定的闲置期。
-
[北京][2013年12月14日] 线下活动,介绍貔貅 - 世界上首个全民所有比特币交易所 at 2013年12月05日
参加,了解下比特币:)
-
招个人怎么就那么的难啊?! at 2013年10月26日
-
[北京][10 月 19 日] Ruby Saturday [改地方啦,不要去贝塔咖啡了啊] at 2013年10月21日
@sundevilyang 哈,谢谢。
目前 statlysis 只完成了核心部分,图表展示模块还没有动手,所以直观点的项目介绍我估计等做个主页来介绍比较好些,所以这也是我迟迟没敢正式推出的原因。欢迎到时在微信平台推送:)
-
[北京][10 月 19 日] Ruby Saturday [改地方啦,不要去贝塔咖啡了啊] at 2013年10月19日
我分享的基于 ActiveRecord 和 Mongoid 两个 ORM 的统计分析框架地址在 https://github.com/sunshinelibrary/statlysis
-
[北京][10 月 19 日] Ruby Saturday [改地方啦,不要去贝塔咖啡了啊] at 2013年10月19日
在 @ouyang 家
-
[北京] 哈佛大牛创业团队诚觅运维工程师!时间灵活 + 项目自决 + 可以参与开发 at 2013年10月16日
-
[北京] 哈佛大牛创业团队诚觅运维工程师!时间灵活 + 项目自决 + 可以参与开发 at 2013年10月16日
#5 楼 @blackanger 来了有段时间了,帮忙推荐下候选人哈
-
[北京] 哈佛大牛创业团队诚觅运维工程师!时间灵活 + 项目自决 + 可以参与开发 at 2013年10月16日
#4 楼 @oldfritter 欢迎在运维开发方面有经验的高手投递简历,我们开发的非业务项目都是开源的。
-
[北京] 哈佛大牛创业团队诚觅运维工程师!时间灵活 + 项目自决 + 可以参与开发 at 2013年10月16日
#2 楼 @RainFlying 开发运维工具是可以远程兼职的,如果有相关经验请发简历过来看看:)
-
高度集中持续写 12 小时代码你有什么感觉? at 2013年10月14日
#2 楼 @fsword 兴趣是自己控制的,没人逼你,不过应该也没有牛人经常写代码通宵的。个人觉得好代码是思考出来的,当然累的时候也就思考不出什么东西来,所以还是得规律生活。
附上一个 Rails commit 时间图,基本都是工作时间。高峰期是中下午,以及晚上十一二点,之后就洗洗睡了吧。
https://github.com/rails/rails/graphs/punch-card
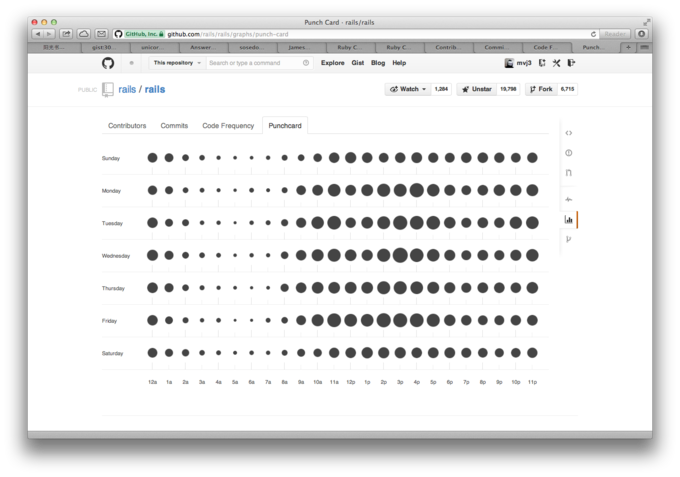
-
高度集中持续写 12 小时代码你有什么感觉? at 2013年10月14日
经常性的这样长时间工作人就傻逼了
-
熬夜写代码后头昏眼花 at 2013年10月14日
赞同。
写代码既是体力工程,也是艺术创作。
前者要求定时工作,属于马拉松式的劳累,要求适时休息,保持节奏。 后者要求要有足够的休憩时间来思考,没见过一个人太累了能思考出什么东西来。
写代码里,用熬夜方式创作,其实就是倒个时差而已,也没见他们做出什么优秀的项目来,反倒经常白天犯困睡觉。
对于公司的老板而言,经常性的无用加班无疑只是吝啬无能老板的自慰满足而已,客户因为没好产品不爽,员工因为失去成就荣誉感也不爽。个人去经常性主动熬夜工作也不过是一丘之貉。
-
如何匹配多个数据源? at 2013年10月09日
-
如何匹配多个数据源? at 2013年09月30日
可以看下 https://github.com/SunshineLibrary/statlysis#setup 的处理,目前支持 Mongoid 通过表名正则匹配解决多数据源的问题,示例代码是
Mongoid[/eoe_logs_[0-9]+$/] # support collection name regexp这样会把符合条件的 collection 放到 Statlysis::MultipleDataset 的一个 instance 里。
如果是多个数据库,或者数据源类型是 MySQL 的话,那就得 fork 下增加功能了哈。
-
[北京] 北京阳光公采诚邀 ruby 程序员加盟 at 2013年09月14日
#5 楼 @neocanable 从我招聘经验来看,在北京招 Ruby 程序员有 Ruby China 社区和 Ruby Saturday 活动就够了,有意向的看到了自己会主动联系的
-
[北京] 北京阳光公采诚邀 ruby 程序员加盟 at 2013年09月13日
#2 楼 @oldfritter 哈,@neocanable 还真的开始搞这个了!
-
RubyConfChina 2013 早鸟票价将持续到 9 月 26 日 at 2013年09月03日
等退钱,或者 RubyChina/GithubT 恤也不错
-
上海·英语流利说技术架构分享活动 at 2013年09月03日
对技术架构很感兴趣,在北京的只能等讲稿上传了
-
RubyConfChina 2013 开始接受报名和售票! at 2013年08月30日
看迟了,599 + 1
-
[9.16 更新两位讲师] RubyConf China 2013 讲师介绍 at 2013年08月23日
看到官方多了几位演讲嘉宾,目前还是不能报名...
-
Ruby 的机器学习项目 at 2013年08月18日
感谢分享,期待有更多实战的分享:)
原理其实大家都差不多,个人担心的是性能太差,我使用过 tf-idf-similarity 来分析网站文章相似性,上两千篇文章的时候十几 G 内存也抗不住了。recommendify 也是,不知道现在在性能方面有没有提升。
对于现在很多不能深入了解数据挖掘算法和具体实现的人(包括我),这方面的软件库还是没有方便到像调用 Nokogiri 之类 DSL 这般成熟。可喜的是 Ruby 在这两年看到的实践是越来越多了。
-
关于统计在线人数 at 2013年08月18日
推荐 https://github.com/eoecn/faye-online ,通过实时聊天技术实现,可以显示在线人数,还可以算出在线时长。
