-
请教一个 Linux 问题,如何将一个服务器完全隐藏起来? at August 30, 2015
然后还有一台服务器 B,然后我的任何请求,不管连接 B 服务器的任何端口(不是个别端口,是所有的),全部转到 B 服务器。
不好意思,这句话我没明白,连 B 的任何端口不就是到 B 上面吗?
-
Grape 的 JSON 参数验证,以及 nested params 问题 at August 30, 2015
http request header 中设置 content-type 为 application/json,传 json 参数是没有问题的
-
Rails 日志展示 at August 24, 2015
elasticsearch + logstash + kibana
-
寻找替代 sidekiq 的东西 at August 22, 2015
可以考虑财付通的虚拟运通卡,跟 master card 一样,且 cvv code 是短信动态发送的,只会扣财付通余额,不担心泄漏问题
-
SQL 的问题,活动的列表里面需要获取当前用户的是否喜欢了某一条活动 at August 20, 2015
#13 楼 @zhzenghui 推荐 vincent 大神的讲解 http://www.slideshare.net/vincent253/redis-37221509
-
SQL 的问题,活动的列表里面需要获取当前用户的是否喜欢了某一条活动 at August 19, 2015
这种需求正是 redis 的应用场景
-
Rails 如何动态定义表结构?已上传了我的方法。 at July 22, 2015
我觉得还是再分析一下需求,是不是真的需要做动态表列,如果增加表列,老的数据如何处理?如果是删除列,老的数据是否也要删除列? 按我的理解,这种动态属性的表结构可以转换成一对多的从属关系分两张表保存,且这两张表都是固定列的,这样每条记录的属性都可以不一样,顶多再加一个表列的描述表,就能满足需求。只是需要在代码层面做额外的数据校验。
-
Rails 如何动态定义表结构?已上传了我的方法。 at July 21, 2015
需求一定是要在 sql 数据库上做动态表列吗?就不能用 nosql 的 mongo 这些?
-
RubyConf China 2015 赞助征集 at July 21, 2015
-
RubyConf China 2015 赞助征集 at July 21, 2015
 错别字太多,不能忍啊
错别字太多,不能忍啊 -
rails 写 txt 文件的回车为啥在 windows 下是乱码? at July 20, 2015
linux 下面回车是\r,windows 下面是\r\n
-
做一个管理系统,用 mongodb 还是 pg? at July 14, 2015
ip 表,端口表,再做一个关联表关联 ip 和端口,不需要用不定列
-
发送邮件 100 封,想要每 10 封做一个线程或者 Process at July 14, 2015
sidekiq,100 封邮件分成 10 组,调用 10 次 perform,每个任务 10 个邮件 id 不过这么搞的话一般会被 smtp 服务器那边封 ip 的吧
-
Nginx 负载均衡配置怎么实现不同主机上的数据同步的 at July 14, 2015
会话数据一般是在 loadbalance 上设置会话保持,这样同一用户的访问会转到同一台主机上,这样就不存在会话数据共享的问题,否则要考虑 session 同步 应用数据可以采用共享连接同一个数据库实现,这种方式在初期是完全 ok 的,除非到了数据库有瓶颈的时候要分库
-
怎么改 devise 中默认的 email 登录为 username? at July 07, 2015
您的 这个 说话 方式 好 累
-
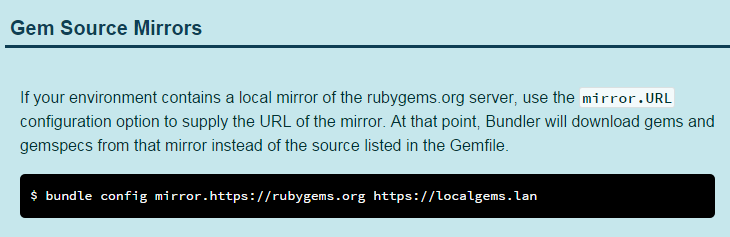
无需更改 Gemfile,让 bundle 使用淘宝源 at July 03, 2015
-
怎么继续某个 Rake Task? at June 25, 2015
是否可以考虑改成独立的任务去跑,比如放到 sidekiq 里去,每个 article 一个 sidekiq 任务,这样单个任务失败可以重试,不影响其他任务结果
-
Rails 和 Grape 返回的 JSON 中存在<null> at June 12, 2015
expose :doctor_name do |model, opts| model.doctor.try(:name) || "" end -
关于 rails_admin 的看法。 at June 12, 2015
有什么问题?我加了 rails_admin,不过只做基本的辅助查询修改,没做定制开发,貌似也没什么问题
-
求一些 Rails 常用的 Gem at June 03, 2015
-
Mark 一下,Ubuntu 15.04 里编译安装 Ruby 2.2.2 at May 14, 2015
为啥不用 rvm?
-
Cookpad - 可能是世界上最大的 Rails 单一应用 at March 06, 2015
介绍了不少工具,可以研究一下开拓思路
-
[已解决] 你们真的会用 DigitalOcean5 美元的方案吗? at January 21, 2015
-
Redmine 的编码问题 at January 08, 2015
是不是数据库编码问题?改成 utf-8 编码试试
-
多个 Rails 项目,共用一个库,一般怎么操作 at December 28, 2014
考虑 git 的 submodule?
-
Sublime 插件站点挂掉了? at December 28, 2014