-
FQ 赚外快获得的收益属于"非法所得"吗 at 2023年09月27日
加班违反劳动法,应该没收加班所得
-
大家在开发 rails api 的时候是否遵循 jsonapi 规范 at 2023年09月24日
确实,这种单独调试接口会比较难受
-
大家在开发 rails api 的时候是否遵循 jsonapi 规范 at 2023年09月23日
这算不算另外一种 jsonapi 规范,哈哈
-
大家在开发 rails api 的时候是否遵循 jsonapi 规范 at 2023年09月23日
感谢分享,前端这个库还是第一次知道,先去了解一下
-
v2ex 经常挂么?那么当他挂了 我们该用什么扯淡?不如我建个 discord 如何? at 2023年09月15日
支持 discord
-
想请教一下,大家是怎么开发 Ruby 的呢 at 2023年09月10日
-
关于单表继承删除 super record 的问题 at 2022年04月04日
是的,我删除 type 字段只是用来排查代码问题的一个方法,最后 type 还是会留着的,I like magic ..
-
关于单表继承删除 super record 的问题 at 2022年04月04日
我刚刚试了一下,在 db 层做级联删除,rails 日志里面也会体现删除连结表记录的 我的 rails 版本是:6.1.4.4
[1] [backend][development] pry(main)> People.first.destroy Question Load (0.7ms) SELECT "peoples".* FROM "peoples" ORDER BY "people"."id" ASC LIMIT $1 [["LIMIT", 1]] TRANSACTION (0.2ms) BEGIN Teachers::HABTM_Courses Destroy (0.8ms) DELETE FROM "teachers_courses" WHERE "teachers_courses"."teacher_id" = $1 [["teacher_id", 12]] Teacher Destroy (1.0ms) DELETE FROM "peoples" WHERE "peoples"."id" = $1 [["id", 12]] TRANSACTION (0.6ms) COMMIT不过我另外尝试将 people 的 type 字段去掉的话,就不显示删除连结表记录了,但实际上连结表记录还是会删除的。所以我有个猜测是 rails 层做模型删除是不是和 type 字段有关系。
-
关于单表继承删除 super record 的问题 at 2022年04月04日
哈哈,可以的老哥

-
关于单表继承删除 super record 的问题 at 2022年04月04日
检查了一下,确实是配置问题,当时建 courses_teachers 表用的是 create_table 方法,并且没加 foreign_key。 这样就好了
add_foreign_key :courses_teachers, :courses, on_delete: :cascade add_foreign_key :courses_teachers, :peoples, column: :teacher_id, on_delete: :cascade感谢感谢。
-
关于单表继承删除 super record 的问题 at 2022年04月04日
这个能解决的现在的问题,不过我还有个比较刁钻的问题,假如还有个 student 类,同样继承了 people。student 和 teacher 都有自己外部的关联关系。
但有一个需求,一个 people 即可以是 student,同时也可以是 teacher,这个时候 type 貌似就失效了。。。
而删除了个 people 的时候它本身作为 teacher 和 student 的关联也都要删除,额。。。
-
关于单表继承删除 super record 的问题 at 2022年04月04日
nice

-
关于单表继承删除 super record 的问题 at 2022年04月04日
我只是想让代码更语义一些,毕竟 people 和 course 没有关联,而语义上 teacher 和 course 才有关联。 同理如果还有 driver 也继承了 people,把关系放在 people 上 driver 也会继承到 course 的关系,这种没有理由的。 能兼容语义最好,实在没办法了再全部堆到 people 上。当然再妥协之前想尝试着找找有没有一种优雅的解决方案。 一楼的老哥给的就是一种相对合理的方案了。
-
问一个关于在 rails scope 中 join 表查询设置时 where 条件的问题 at 2022年03月18日
这里在设计的时候 setting 和 user 时一对多的关系,setting 只是配置了 user 激活限制的时间。
比如 user1 关联的 setting1,那 user1 就需要在 attended_at 后 80 minutes 内激活账号。
如果 user1 改变了 setting 为 setting2,那 user1 就可以在 attended_at 后 90 minutes 内激活账号。
换言之就是 user 的 setting 是可控的,不过按找老哥的思路倒是可以在 user 上加一个 activate_end_at,当换 setting 的时候更新 user.activate_end_at,这样可以将原本需要逻辑计算的直接映射成数据存下来,查询的时候也不要 join 了。。。
scope :can_activates, -> { where(':activate_end_at > ?', Time.now() ) } -
ActiveRecord 中如何将两个 scope 通过 or 条件合并成一个 scope at 2022年03月18日
是的,两个 scope 都比较简单的情况下二楼的方式比较合适,但是如果遇到稍微复杂一点的 scope,合并起来就容易代码重复。
不过我刚刚测试了下,如果 scope 中有 join 的情况,三楼的写法在运行的时候也容易报错。例如
# 离线 scope : onlines, -> { where(:state => 'online') } # 忙碌, 只有正在写代码才算真的busy scope :real_busys, lambda { joins(:doings) .where(:state => 'busy') .and(where('doings.thing == coding')) }如果直接合并为
scope :onlines_or_real_busy, -> { onlines.or(real_busys) }在执行的时候会报错:
ArgumentError: Relation passed to #or must be structurally compatible. Incompatible values: [:joins]需要将有 join 提前,写为:
scope :onlines_or_real_busys, -> { real_busys.or(onlines) }运行的时候就没问题了。
但是是这么写的话当修改过前面的 scope,比如在 onlines 上 join 其它的 table 时,需要连带修改测试合并的 onlines_or_real_busys,这样代码维护起来就不太好了。
真是 Egg pain ....
-
问一个关于在 rails scope 中 join 表查询设置时 where 条件的问题 at 2022年03月18日
搞定了,谢谢老哥,不过貌似这种情况只能用 sql 字符串,用 Active Record Query Interface 好像就没法实现了。
-
如何使用 rubyXL 给 excel 添加批注 at 2020年05月14日
谢谢,我按照这个 issue 上提供的方式尝试了,但是打开 excel 后没有显示批注,目前 rubyXL 好像还没有合适的方式添加批注,删除批注倒是可以。
-
如何使用 fetch 发送 delete 请求 at 2019年07月11日
解决方法
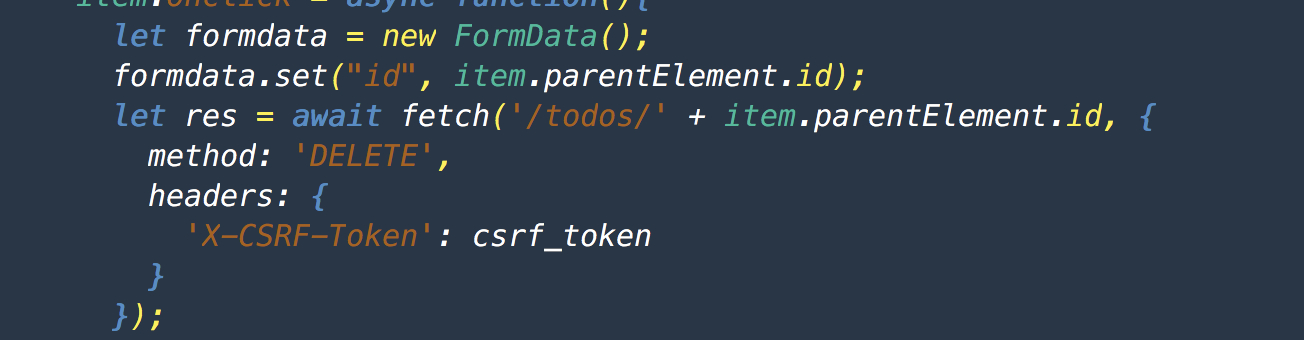
-
如何使用 fetch 发送 delete 请求 at 2019年07月11日
谢谢提醒,找到问题了,Can't verify CSRF token authenticity。
-
如何单独使用 active_support 中的 autoload at 2019年05月11日
感谢你的传送门,学了一遍历史,对 bundle 的认识更丰满了,哈哈
-
如何单独使用 active_support 中的 autoload at 2019年05月11日
@kayakjiang 感谢你的回答,设置了$LOAD_PATH 运行成功了,现在还有一点疑惑的地方就是原先我以为 ActiveSupport::Dependencies.autoload_paths 会自动维护$LOAD_PATH,目前来看我的理解还是有偏差,所以 autoload_paths 和 $LOAD_PATH 之间是什么关系,各自负责的内容是什么,按照上面的解决方式,其实 autoload_paths 这个数组好像没有什么作用。
-
如何单独使用 active_support 中的 autoload at 2019年05月10日
试试@kayakjiang,解惑答疑时间
-
还有多少同学在做 Ruby 相关工作? at 2019年03月16日
1
-
求书,Ruby 元编程第二版中文电子版,最好 PDF,不要扫描版,我愿意购买!!!!!!! at 2018年09月06日
买本纸质书也不要多少钱啊,看着还舒服