我一直是做 Java 开发的,去年用 Ruby 做过一个完整的项目,最头疼的事情是做一些后台任务。比如批量导入数据,Ruby 不支持线程,做这种事情就只能用另外一个 Ruby 来执行,这样就需要保存和读取程序的状态。而且调试起来非常麻烦。您在这方面有什么经验可以分享吗?
#1 楼 @ryvius Ruby 不支持线程?? 你确定? http://ruby-doc.org/core-1.9.3/Thread.html
Ruby 从 1.9 开始就支持 Native 线程了。1.9 以前是绿色线程。
#5 楼 @ryvius Ruby 的线程是 Native 线程,线程的调度是 OS 来实现的。但是呢,由于 GIL 的存在,同一时间只有获取了这个锁的线程在跑,也限制了有 GIL 的语言利用多核的能力。
有 GIL 的限制并不代表你不能进行一些异步(通常意义上的异步)的操作。因为 GIL 不会被某个线程一直持有,所以其他的线程都有运行的机会。只是利用不上多核的能力。就像以前,我们用单核 CPU 跑多线程程序类似。
再往下说,就和其他多线程编程一样了,Java 虽然没有 GIL,但是如果写的程序中,几个 Java 线程都对某个公共资源进行访问和修改,如果加锁进行保护,那么这几个线程也不能真正达到多核的利用。
补充一下:有很多 gem 并没有考虑多线程的问题,尤其是一些 Native Gem。 《Unix 编程艺术》中,并不很提倡多线程编程,多进程 + 管道 是被推荐的。
#7 楼 @skandhas #3 楼 @Rei #1 楼 @ryvius
Ruby1.9 开启了 Native Thread, 但有 GIL 全局锁。与 python 类似,依然不能同时两个 Native Thread 并发。但有一点好处,IO 现在是异步的。
缺点:在用户级看来,依然与 Ruby1.8 的 Green Thread 一样,在内核阻塞的线程会导致挂死 Ruby.
解决的办法 7 楼 说的很对,多进程 + 一种通信。例如现在的 chrome 就是这种方式的典型运用。可见效率没有问题,但这种方式比一般的多线程难度大许多。所以与其让 Ruby 解决后台并发问题,不如换一种语言,如 Erlang 等。
我大概了解了,我在 187 的时候就是用的多进程来做的,不能共享内存使得程序变得很复杂,非常难调试。同时用两种语言一样需要加入通信机制,并不能提高太大的开发效率。另外,如果用 Ruby 的 Thread,可以实现定时任务吗?我现在用的是一个第三方的叫做 dealy_job 的 gem,就是多进程模式。
#8 楼 @lyfi2003 Ruby1.9 的线程和 1.8 差异大,在用户级的行为也不一样。GIL 的主要限制并不是在“在内核阻塞的线程会导致挂死 Ruby.”。比如说,1.9 下,你创建几个线程,让其中几个线程通过 Lock(当然,1.8 和 1.9 的 Mutex 实现也不一样)等手段来堵塞,其他线程依然可以被 OS 调度。1.8 和 1.9 的差异在线程是由 Ruby 来调度,1.9 是由 OS 来调度,而 GIL 影响 OS 对 Ruby 线程的调度。
虽然可被调度,但是由于 GIL 的存在,致使 Ruby 线程真正的不能并发执行(是指真正的并发)。
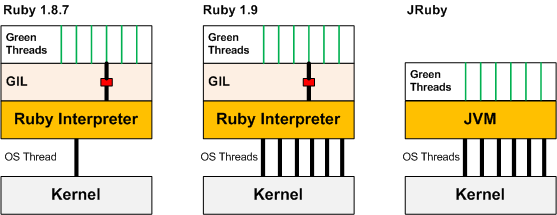
1.8 下,所有的 Ruby 线程 对应一个 OS 线程,所以任意一个 Ruby 线程被堵塞住,都会把 OS 线程堵塞住。
1.9 下,每个 Ruby 线程 分别对应不同的 OS 线程,一个 Ruby 线程被堵塞住(这里的堵塞不是指被 GIL 堵塞,而是指被其他堵塞,如其他的资源锁,或是同步 IO 等),只堵塞住其对应的 OS 线程。 但是,GIL 可以看作是一个竞争资源的锁,这就使得 Ruby 线程 在获取这个 GIL 上变成了串行化。
不太靠谱的比喻: 就像一队人去上厕所,就一个茅坑,只能排队了。上完厕所之后的人,可以去打球,唱歌,灌酒..., 他们就各自活动了,其中有个人睡着了,其他人还继续玩自己的。然后又排队上厕所...
总有人不断的提起 Ruby 的线程不是原生线程的问题。
GIL 的存在,只是限制了你不可以利用计算机的多核进行并行计算,但是并不是意味着你不可以并发。事实上 Web 开发中大量使用并发,诸如 EvertMachine 之类的玩意儿利用的那个叫做 Reactor 模式的玩意儿。它其实是在多个线程之上运行纤程 (Ruby 1.9) 实现的。虽然无法像 elang 那样,真正利用多处理器的优势,不过在 Web 开发领域,足够了
我记得在那里看的 (不知道记得是否准确), 线程再可以利用多核,也不是一个好的技术,它只会让你越来越痛苦。
终极解决办法还是进程,最好是单独的虚拟机中的单独进程,然后组成庞大的计算机群,这才是硬道理。
rubyconf 2012 ruby.20 介绍 slide: https://speakerdeck.com/a_matsuda/ruby-2-dot-0-on-rails
我感觉 Keyword arguments 非常实用 Converting convention to Hash 和 a literal for symbol array 也都不错 Enumerator#lazy 我还没搞懂
翻了下,正则的地方不太清晰望能指正下
##1 Refinements 在 module 命名空间里面使用这东西,那么之下定义的方法只有在命名空间内才有效,在命名空间之外会失败
module NumberQuery
refine String do #关键字refine
def number?
match(/^[1-9][0-9]+$/) ? true : false
end
end
end
begin
"123".number?
rescue => e
p e #=> #<NoMethodError: undefined method `number?' for "123":String>
end
在 module 命名空间内则随便用,好处是不会污染到外面已存在的对象
module NumberQuery
p "123".number? #=> true
end
想在其他已存在的 module 命名空间里面用到的话,可以用 using 关键字
module MyApp
using NumberQuery#个人觉得 using这名取得一般...
p "123".number? #=> true
p "foo".number? #=> false
end
##2)Keyword Arguments
def wrap(string, before: "<", after: ">")
"#{before}#{string}#{after}" # no need to retrieve options from a hash
end
# optional
p wrap("foo") #=> "<foo>"
# one or the other,可以只设其中一个值
p wrap("foo", before: "#<") #=> "#<foo>"
p wrap("foo", after: "]") #=> "<foo]"
# order not important, 顺序可以随便放
p wrap("foo", after: "]", before: "[") #=> "[foo]"
# double splat to capture all keyword arguments, or use as hash as keyword, 两个星号表示可以把整个keyword arguments抓下来
# arguments
def capture(**opts)
opts
end
p capture(foo: "bar") #=> {:foo=>"bar"} 返回的是hash
# keys must be symbols 传进的key一定要是hash
opts = {:before => "(", :after => ")"}
p wrap("foo", **opts) #=> "(foo)" 注意这里的**opts, 代表把上面的opts当做keyword arguments
#旧的hash传参数方法继续支持,其实用起来不会有太大的不同
p wrap("foo", :before => "{", :after => "}") #=> "{foo}"
##3)Enumerator lazy 可以遍历无限大集合的新方式
require "timeout"
begin
timeout(1) {[1,2,3].cycle.map {|x| x * 10}} #cycle()函数里面不指定次数的话就是无限次完全遍历当前集合,指定次数就是遍历多少次
rescue => e
p e #=> #<Timeout::Error: execution expired>
end
p [1,2,3].lazy.cycle.map {|x| x * 10}.take(5).to_a #=> [10, 20, 30, 10, 20] 本应不断循环,但是用了lazy后会一次扒出来
#A lazy enumerable will evaluate the entire chain for each element at a time, rather than all elements at each stage of the chain, so the following will output at 1 second intervals. Without #lazy all output would come after 3 seconds
##4)Enumerator prepend
module A
def foo
"A"
end
end
class B
include A
def foo
"B"
end
end
p B.new.foo #=> "B"
以前在 class 里面写的同名方法会覆盖掉 module 里面的方法,可以用回 super 去调用复写了的 module 方法 现在用 prepend 的话
class C
prepend A
def foo
"B"
end
end
p C.new.foo #=> "A" 这种情况还是可以用super访问到class里面定义的foo方法,ruby就是要提供更多选择给我们...
##5) 新的 to_hash 方法 to_h
p({:foo => 1}.to_h) #=> {:foo=>1}
Baz = Struct.new(:foo)
baz = Baz.new(1)
p baz.to_h #=> {:foo=>1}
所以以前的写法
def foo(opts)
raise ArgumentError, "opts must be a Hash" unless opts.is_a?(Hash)
# do stuff with opts
end
可以变成这样:
def foo(options)
if options.respond_to?(:to_h)
opts = options.to_h
else
raise TypeError, "can't convert #{options.inspect} into Hash"
end
# do stuff with opts
end
##6)symbol array 的方便写法%i()
p %i{hurray huzzah whoop} #=> [:hurray, :huzzah, :whoop]
##7) 正则表达式的引擎转成 Onigmo (?(cond)yes|no) #有点像三目运算符,如果 cond 先 match 的话,就再去 match yes,否则就去 match no
例子
regexp = /^([A-Z])?[a-z]+(?(1)[A-Z]|[a-z])$/
#开头大小写字母都可以,中间要都是小写字母, 然后引用回括号1,前面的大写match到吗?match到再看看是否A-Z结尾,否则是a-z结尾
#这例子只会检测到前后都是大写或都是小写 并且中间要是小写 的例子
regexp =~ "foo" #=> 0
regexp =~ "foO" #=> nil
regexp =~ "FoO" #=> 0
# double splat to capture all keyword arguments, or use as hash as keyword, 两个星号表示可以把整个keyword arguments抓下来
# arguments
def capture(**opts)
opts
end
p capture(foo: "bar") #=> {:foo=>"bar"} 返回的是hash
# keys must be symbols 传进的key一定要是hash
opts = {:before => "(", :after => ")"}
p wrap("foo", **opts) #=> "(foo)" 注意这里的**opts, 代表把上面的opts当做keyword arguments
#旧的hash传参数方法继续支持,其实用起来不会有太大的不同
p wrap("foo", :before => "{", :after => "}") #=> "{foo}"
其实没怎么看懂,def capture(**opts) 和 def capture(opts) 的区别是什么?都可以直接接受一个 hash 啊
不要用 WINDOWS 多线程的思维去套 Unix 的多线程,因为 Unix 下一般只有多进程模式,也就是你经常听说的 fork,进程间通讯在 Unix 下被设计的非常简单,方式也很多,fork 出的进程只共享代码段,其他数据段和堆栈段都是独立的,不存在 WINDOWS 下多线程竞争资源的事情,避免了以此造成的一系列编程问题。有人说,Unix 下的多进程才类似于 windows 下的多线程,而 Unix 下的应用程序才类似于 windows 下的进程,关于这个话题已经被谈论很多年了。还有不要一想到多进程,就是效率低,这个观念也要改变,特别是 Linux/Unix 下面。