分享 OpenClacky 1.0 正式发布 —— Ruby 圈第一个通用 Agent 来了
前段时间社区里一直有人在问:Python 那边 agent 框架一个接一个,Ruby 圈怎么就没一个拿得出手的通用 Agent?
我们憋了两年,今天它来了。
OpenClacky 1.0.0 正式发布,MIT 开源,纯 Ruby 写的。
本文分两部分:先说是什么、怎么用;然后讲讲我们是怎么把 Token 成本打下来的 —— 后半段才是干货,欢迎直接跳到第三节。
一、这是个什么东西
一句话:最省 Token 的开源通用 AI Agent。
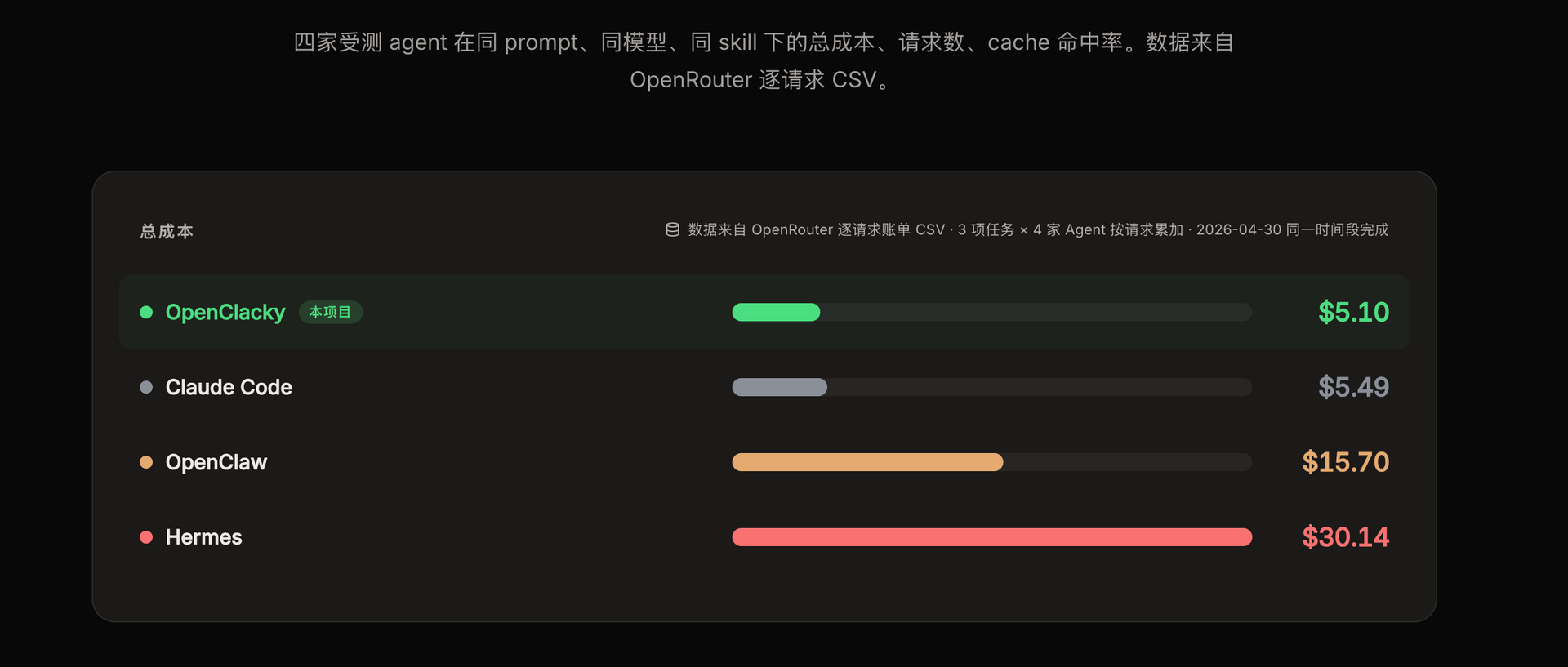
能力上对齐 Claude Code,成本打到它的 0.8~1.2×;相比其它开源 agent(如 OpenClaw、Hermes),大约便宜 50% ~ 3 倍。
两种用法,30 秒就能跑起来:
# 安装
gem install openclacky
# 命令行
openclacky
# 或者跑 Web UI(多会话并行)
openclacky server # 默认 http://localhost:7070
BYOK,任意 OpenAI 兼容模型都支持:Claude / GPT / DeepSeek / Kimi / MiniMax / OpenRouter,或者任何自定义 endpoint。进去 /config 填 API Key、Model、Base URL 就完事了。
二、为什么我们又要再写一个
用过 Claude Code 的朋友应该都很惊艳,但三个问题一直没解:
- 闭源 + 订阅制,拿不到内部细节,也没办法定制
- 只能用 Anthropic 自家模型,不能 BYOK
- 对中国开发者来说,付费通路不顺畅
我们也试过 OpenClaw、Hermes 这些开源方案,能力是有的,但实测下来 Token 成本是 Claude Code 的 1.5× ~ 3×。
这是什么概念?一个中等规模的项目,一天下来 token 费可能就是几十到几百块,差 2~3 倍就是实打实的 RMB 差 2~3 倍。对个人开发者和小团队太贵了。
所以我们自己做了一个。目标很明确:能力不输,成本打到最低。
三、怎么把 Token 成本打下来的(干货)
先看对比表:
| Agent | 相对成本 | 工具数 | 开源 | BYOK | IM 集成 |
|---|---|---|---|---|---|
| Claude Code | 1.0×(基准) | 40+ | ❌ 闭源 | ❌ | ❌ |
| OpenClaw | ~1.5× | 23 | ✅ | ✅ | ✅ |
| Hermes | ~3× | 52 | ✅ | ✅ | ✅ |
| OpenClacky | ~0.8 | 16 | ✅ MIT | ✅ | ✅ |
注:数据是内部常见 agent 任务的平均值,以 Claude Code 为基准。完整 benchmark 后续会放到 GitHub。
不是靠砍功能,是靠每一层都做对选择,复利叠加下来的。下面讲四个关键决策。
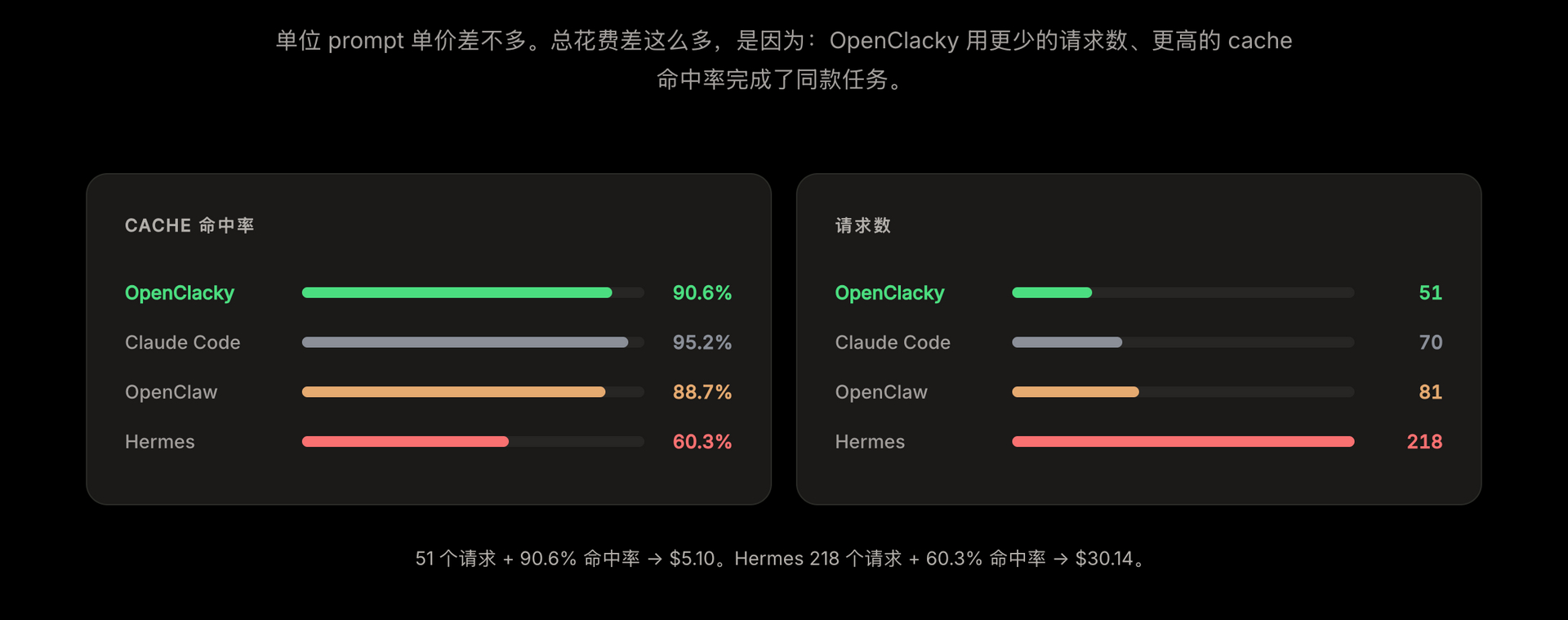
3.1 缓存命中率接近 100%
这是最大的一块。Agent 类应用的对话上下文非常长,API 侧的 prompt caching 是省钱的核心。做对了,成本直接砍一半以上;做错了,基本等于没开。
我们做了三件事:
Session 不重启。 很多 agent 每次启动或切换任务都会重建上下文,前缀一变 cache 全丢。OpenClacky 的 session 生命周期贯穿整个进程,工具调用、子 agent 调度、Skill 执行都挂在同一条上下文上。
双 cache marker。 OpenAI / Anthropic 家的 caching 都是按前缀对齐。我们在 system prompt 尾部和对话中段各打一个 marker,确保即使中段有动态插入,前半段仍然完整命中。
Insert-then-Compress。 这是关键。传统做法是上下文满了就"压缩 + 重写 system prompt",一旦 system prompt 变了,前缀 cache 全失效,下一条消息变成冷启动。
我们反过来:system prompt 永远不变,压缩发生在对话区,用"插入一条总结 + 裁剪被总结的内容"的方式。system prompt 那段前缀的 cache 永远是热的。
实测下来 cache 命中率接近 100%。
3.2 最小工具集:只有 16 个
这点反直觉,我们反复测过 —— 工具不是越多越好,是越精越好。
| OpenClacky | Claude Code | OpenClaw | Hermes |
|---|---|---|---|
| 16 | 40+ | 23 | 52 |
为什么?因为工具的 schema 是要塞进每一次请求的 system prompt 的。52 个工具意味着 schema 膨胀 3~4 倍,每次对话都要多烧这么多 token。更糟的是 schema 越大,模型选工具的准确率反而下降(这点我们跑过对照实验)。
我们的做法是把所有非核心能力下沉到 Skill 体系,主工具只保留一个 invoke_skill 元工具。需要 PPT?有 skill。需要 SQL 调优?有 skill。需要内部规范?有 skill。
工具数量不是指标,任务完成率才是。
3.3 空闲时间自动压缩
这个功能用起来很爽。你去开会、喝咖啡、吃饭,agent 并不是闲着 —— 它在后台做两件事:
- 把长上下文做渐进式压缩
- 预热压缩后的 cache
等你回来发第一条消息,直接命中热 cache。冷启动首 token 成本降低 50%+。
3.4 BYOK + 子任务路由
BYOK 大家都有,但我们多走了一步:主任务用 Claude,子 agent 的子任务可以路由到 DeepSeek / Kimi 这种便宜模型。能力不损失太多,成本再砍一大块。
这四条叠起来,才是那个 0.8 的数字。
四、Skill —— Agent 的灵魂
Skill 是我们认为 Agent 下一个阶段的关键。简单讲就是可插拔的"领域技能包"。
-
/直接召唤:即时浏览、模糊搜索、直接调用,上百个 Skill 随手可用 -
自然语言创建:你描述想要什么,agent 自己起草
SKILL.md、拆步骤、跑验证,不用写代码 - 自我进化:每次执行完,agent 根据执行过程和结果回写更新。下一次调用更稳、更准
- 开放兼容:支持 Claude Skills / Markdown Pack / 自定义格式
- 可变现:打磨好的 Skill 可以打包加密分发、License 管理、自定价格
现在已经有用户在上面做垂直专家 Skill 了 —— 法律、医疗、理财规划,都有人跑起来。创作者计划的细节可以看官网。
五、用例示范
今天 agent 能"问个项目问题"已经是及格线了,真正拉开差距的是能不能端到端交付一件事。下面几个是我们自己和早期用户每天在跑的真实场景。
用例一:从零交付一个 SaaS 原型(多 session 并行)
$ openclacky server
开三个 session 并行:
- Session A:
/new生成 Rails 7 + Tailwind 项目,建好 User / Subscription 模型,接 Stripe 订阅 - Session B:写落地页文案、SEO meta、FAQ,同时用 Skill 调 PPT 生成器出一份投资人 deck
- Session C:跑用户访谈资料分析,输出 PMF 判断报告
三个 session 共享同一份 workspace 上下文,改完 A 的定价策略,B 的落地页文案自动跟上。以前这是三个人半天的活。
用例二:给一个 20 万行的老项目加功能,并让它自己跑完回归
> 我要在订单模块加"部分退款"能力,退款后要同步更新财务对账表、
触发用户邮件、并在 admin 后台补一个退款审核流程。
跑完 rake test 确保所有测试通过再交付。
它会自己:读相关模块 → 列修改计划 → 写代码 → 跑测试 → 测试挂了自己修 → 再跑 → 通过后给你一份变更摘要。
整个过程基本不用盯,空闲时它还在后台做 context 压缩,你去吃个饭回来直接看结果。
用例三:自己造一个垂直 Skill,让它永久变强
> 我经常要做"Rails 项目性能体检",固定看 7 个指标:
N+1、慢查询、索引缺失、Puma 配置、内存占用、cache 命中、日志异常。
帮我做成一个 Skill。
它会起草 SKILL.md、拆步骤、跑一次验证、让你确认。之后 / 搜 "体检" 直接召唤,跑一次自动进化一次,下次更准。好的 Skill 可以打包加密分发、定价出售 —— 我们已经有用户靠卖垂直 Skill 跑通商业闭环了。
用例四:跨代码库迁移 / 大重构
比如把一个 Rails 5.2 + Sprockets + jQuery 的老项目,迁到 Rails 7.2 + Importmap + Stimulus + Turbo。这种活以前外包报价 5 万起,而且没人愿意接。
现在开一个 session 挂上去,分阶段跑:依赖升级 → Asset Pipeline 切换 → 前端重写 → 测试补齐。每一阶段都让它先出计划再动手,人只做把关。
用例五:Web UI 当成"自己的研发中台"
openclacky server 起来的 Web UI 不止是聊天窗口,是一个常驻的多人 / 多项目协作平台:
- 团队内几个人共享 session,接力干活
- 跑 IM 集成(飞书 / 企微 / 微信),在群里 @ 它派任务,结果回群
- 本机跑、或者扔一台服务器上
--host 0.0.0.0团队一起用
这一条是我们自己团队现在的日常 —— OpenClacky 自己就是用 OpenClacky 开发的。
六、关于技术选型的一些闲话
很多人问我们为什么坚持用 Ruby 做这个。
其实 agent 这种场景,Rails 那套"convention over configuration"的哲学一样好使。迭代速度、元编程能力、gem 生态都是加分项。这两年我们三代架构、六个核心 harness 工程决策,反复推翻重来,Ruby 的表达力帮我们省了大量时间。
我希望 Ruby 社区也有自己拿得出手的 AI 基础设施。不只是"能用",而是"够硬、能打"。
七、最后
OpenClacky 1.0.0 正式发布了,来源 100% 开放(MIT),所有决策都可追溯。
- GitHub:https://github.com/clacky-ai/openclacky
- 官网 / 桌面安装包(macOS、Windows):https://www.openclacky.com/
欢迎 star、试用、提 issue、贡献 Skill,也欢迎直接在本帖回复交流。后续我会再写几篇详细技术博客:缓存命中率的工程细节、Skill 自进化的实现、子 agent 路由的 scheduling —— 每一篇都是这种干货。
项目背后由奇绩创坛、真格基金、红杉中国、高瓴资本支持,特此致谢。
希望本文对大家有所帮助。有问题欢迎交流。


 我正在使用本地部署的大模型进行测试,我想导入一个 SKILL,但是这个 SKILL 好像没有成功!
我正在使用本地部署的大模型进行测试,我想导入一个 SKILL,但是这个 SKILL 好像没有成功! 使用起来了,但是感觉有些复杂功能,出来效果不太好。比如电商中的商品+SKU
使用起来了,但是感觉有些复杂功能,出来效果不太好。比如电商中的商品+SKU