安全 API 设计:你们是用 UUID 还是 HEX?
通常大家设计 Restful API 时,会直接返回资源的数字 id 给前端。比如以下一个关于账单的 API,返回当前绑定的信用卡,它的资源 id 是一个数字。
GET /v1/credit_cards.json
{
id: 13232,
number: "61333313333000",
...
}
为了安全,大家都会加上过滤条件 where(company_id: current_company.id) 。
CreditCardsController
def index
render CreditCard.credit_cards.where(company_id: current_company.id)
end
end
这样公司 A 的员工就不能访问公司 B 的数据了。但是如果万一有程序员忘记加 where(company_id: current_company.id) 这个 filter,就会导致数据泄露。
我看到有些公司的做法是,返回十六进制的 id。
比如 checkr
https://docs.checkr.com/#operation/getCandidate
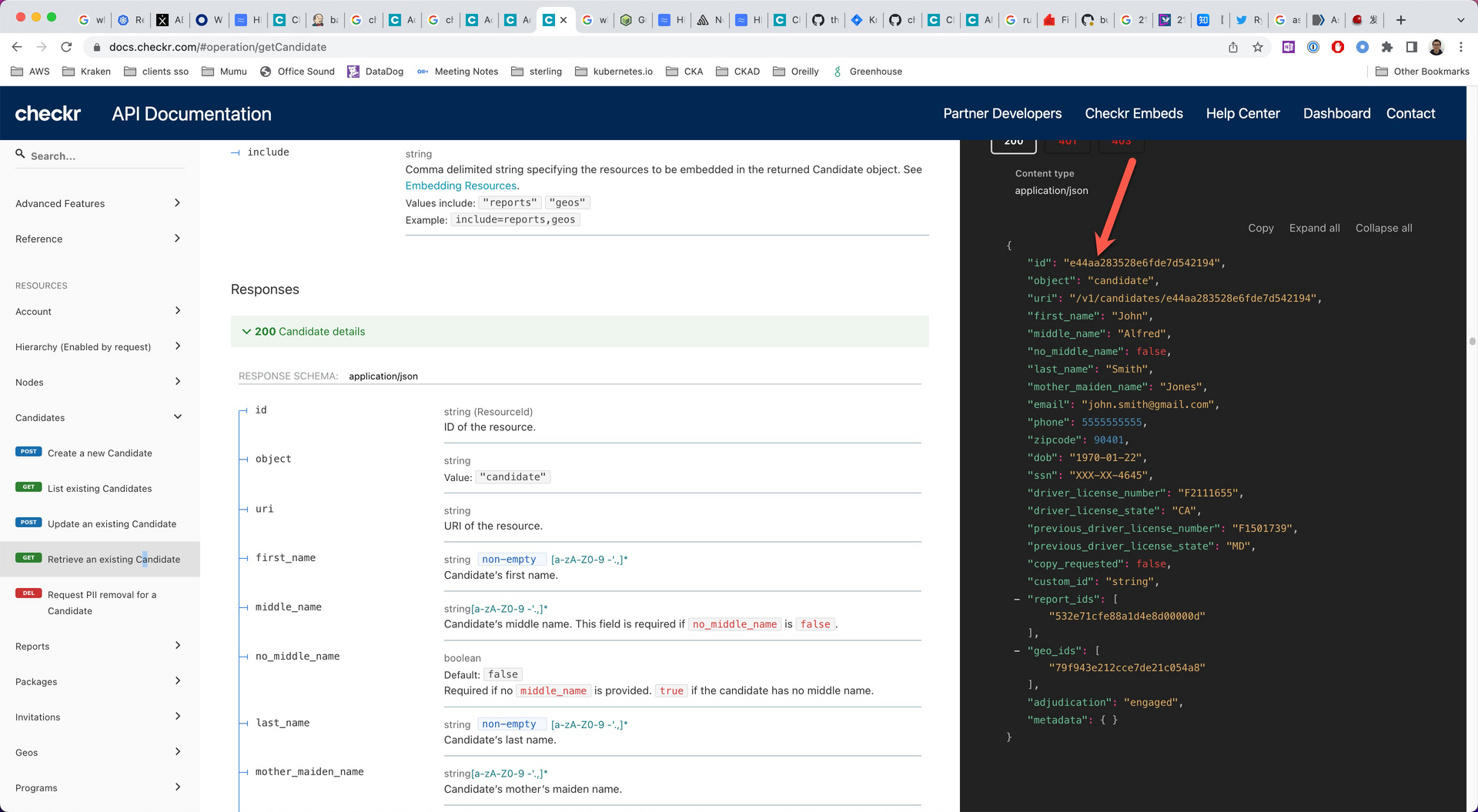
第一个问题:为什么大家不在 API 中用 uuid 呢?
创建方法
SecureRandom.uuid
- 如果用 uuid,黑客更不容易拼出完整 URL。
- 万一某个 API 有安全漏洞,也不容易导致大规模的数据泄露。
比如 API response 范例
{
uuid: "6c8aa96e-4293-408c-baf7-01980faec5bc",
number: "61333313333000",
}
第二个问题:大家在设计企业应用时,返回给前端(合作伙伴)的是 uuid 还是十六进制的 id?
感觉十六进制的 id 还是比较容易猜的。
SecureRandom.hex