数据库 为什么 PostgreSQL 所有会话都在等待磁盘读操作,导致所有 sql 都无法响应?
问题
在生产环境遇到一个问题,在请求量非高峰期间,所有 sql 语句都很慢,响应时间平均在 7s,最慢 10s。这个现象持续了大约 10s,才慢慢恢复正常。
下图是 AWS RDS performance insight 的图,可以看到所有 pg 会话都在等待读磁盘(具体等待事件是 DataFileRead 和 buffer io)。这种问题最近一周出现一次。
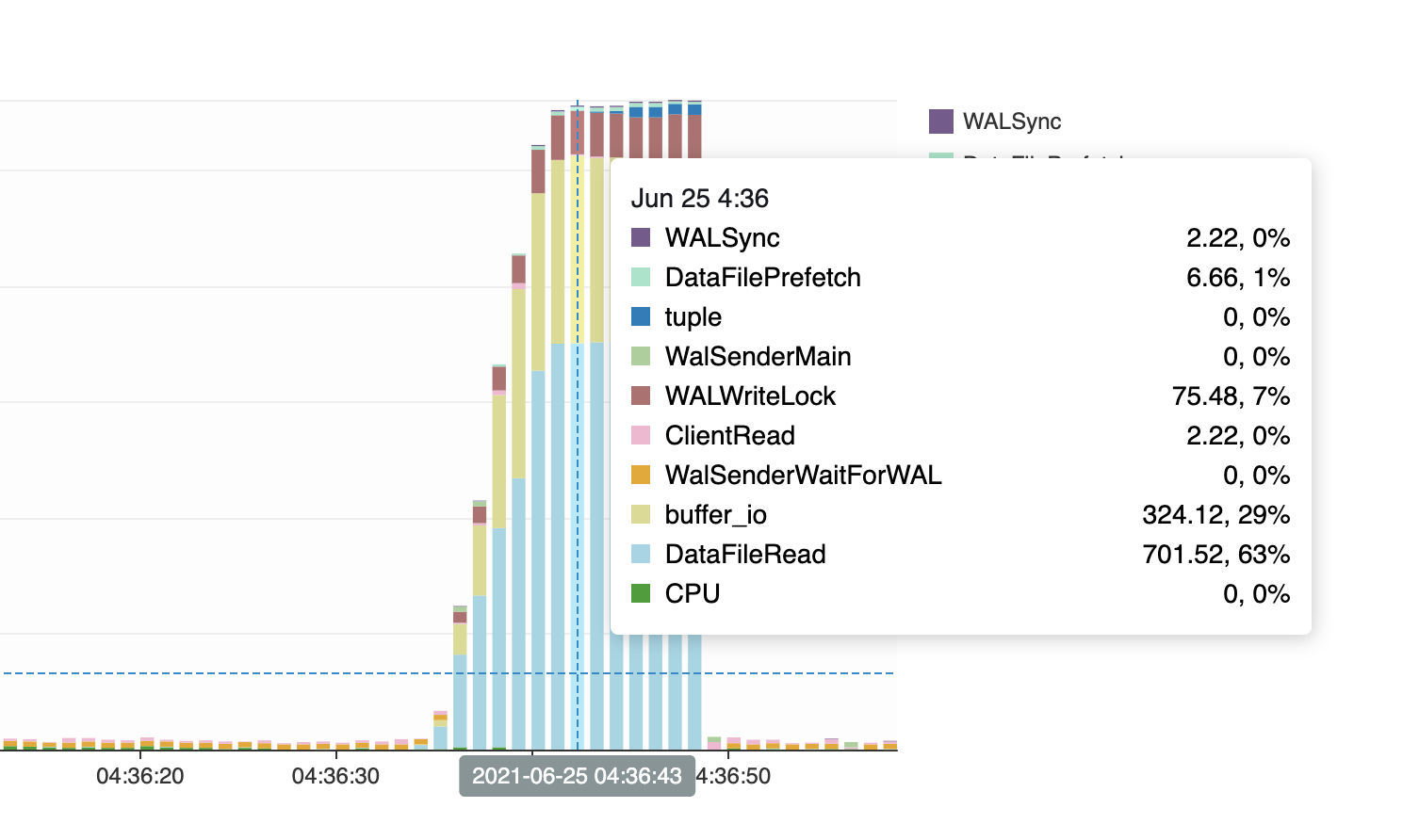
从pg 文档中,我们可以知道等待事件的具体含义
- DataFileWrite: Waiting for a write to a relation data file.
- buffer_io: Waiting for I/O on a data page.
解释
我想这表示
- pg 无法从共享内存的 shared_buffer 中找到对应的 table/index page
- 那些执行 sql 的会话就得等 pg 从磁盘中读取 page(DataFileWrite event)
- 然后写到 shared_buffer 中(buffer_io event)
- 会话此时才能继续执行
猜测
- 是不是请求量超过了数据库 IO 极限?
不是,我查了当时的 IOPS,没达到那台数据库的极限。而且当时的 IO 也比不上每日高峰,数据库的 IO 能力能满足每日高峰,所以一定也能满足当时的请求量。
- 会不会是 shared_buffer 不足?
可是每日高峰也能正常工作呀,如果 shared_buffer 不足,每日高峰应该也会遇到这个问题,所以我觉得不是内存配置问题。
- 会不会是bloat tuple?
- 可能,我们的表行数挺多,而且经常被更新,的确会产生 dead tuple。而 pg 的定期 vacuum 只会把 dead tuple 空出来,一个用户在一个表的所有 rows 在 table page 文件会比较分散,导致当我们在一个表查用户的所有 rows 时,一个 query 要在磁盘上查很多 index/table page 才能找出所有 rows。
- 如何验证?如何复现呢?🤔 通过 explain 来检查一个 query 要查多少 page?
- 如果真的是这个问题,那我们可以用pg_repack来解决它。
求助
大家觉得是什么问题呢?