Ruby 为 Ruby 3 Fiber 调度器设计事件库 Evt
Ruby 3 Fiber 调度器
我在 2020 年 7 月写过一篇文章 《Ruby 3 Fiber 变化前瞻》,以及后来 8 月 又写过一篇文章 《尝试使用 Ruby 3 调度器》,简单介绍了 Fiber 调度器。Ruby 3 在这几个月中更新了数个版本,包括 ruby-3.0.0-preview1 ruby-3.0.0-preview2 和 ruby-3.0.0-rc1,其对于 Fiber 调度器的 API 做了更多的改进。
不过正如我之前所说,Ruby 3 调度器实现的只有接口,如果没有配套的接口实现,默认是不会启动的。最近四个月工作实在很忙,抽出了点时间来跟上 API 更新的脚步。这个项目得以进一步更新。
项目地址:Evt
Fiber 调度器的使用
我们假设我们现在有一对 IO.pipe,我们往一个里写入 Hello World,然后从另一个里读出来。我们可能会写这样一份代码:
rd, wr = IO.pipe
wr.write("Hello World")
wr.close
message = rd.read(20)
puts message
rd.close
不过这个程序有很多限制,比如写入不能超过 buffer,否则另一端由于没有异步读取,会卡死。以及必须要先写再读,否则也会卡死。当然我们可以使用多线程来解决这个问题:
require 'thread'
rd, wr = IO.pipe
t1 = Thread.new do
message = rd.read(20)
puts message
rd.close
end
t2 = Thread.new do
wr.write("Hello World")
wr.close
end
t1.join
t2.join
但我们知道,使用线程来实现 I/O 的多路复用是效率极低的。操作系统的线程切换代价非常大,甚至对于线程之间调度的公平性,至今都是操作系统研究领域的噩梦。然而对于一个 I/O 问题,并不是 CPU-bound 的,只是需要调度器提供合适的睡眠和回调。这时,你只需要调用 Ruby 3 的调度器接口来替代线程就可以了。
require 'evt'
rd, wr = IO.pipe
scheduler = Evt::Scheduler.new
Fiber.set_scheduler scheduler
Fiber.schedule do
message = rd.read(20)
puts message
rd.close
end
Fiber.schedule do
wr.write("Hello World")
wr.close
end
scheduler.run
一般来说异步代码需要写 callback 或者引入 async await 的关键字。但是在 Ruby 3 中这是不必要的。Ruby 3 列举了所有常见的需要进行上下文切换调度的场景:I/O 多路复用、等待进程退出、内核睡眠、自旋锁。把这些接口暴露出来,让开发者可以通过自行开发调度器来进行处理,从而无需引入任何额外的关键字。而我这几个月写的 Evt 就是这样一个调度器。
比起上面这个简单的例子,下面这个例子是一个 HTTP/1.1 的服务器
require 'evt'
@scheduler = Evt::Scheduler.new
Fiber.set_scheduler @scheduler
@server = Socket.new Socket::AF_INET, Socket::SOCK_STREAM
@server.bind Addrinfo.tcp '127.0.0.1', 3002
@server.listen Socket::SOMAXCONN
def handle_socket(socket)
until socket.closed?
line = socket.gets
until line == "\r\n" || line.nil?
line = socket.gets
end
socket.write("HTTP/1.1 200 OK\r\nContent-Length: 0\r\n\r\n")
end
end
Fiber.schedule do
loop do
socket, addr = @server.accept
Fiber.schedule do
handle_socket(socket)
end
end
end
@scheduler.run
可以看出来,开发的过程基本上和同步阻塞的线程开发没有任何区别,只需要 Fiber.set_scheduler 来设置你的调度器,然后在每个原先需要多线程来处理的 I/O 阻塞场景用 Fiber.scheduler 来替代。最后触发 scheduler.run 来启动调度器即可。
后端支持情况
io_uring 支持
这几个月不止 Ruby API 进行了很多优化,我的调度器也做了很多优化,比如做了许多 I/O 多路复用后端的优化。一个是 Linux 5.4 开始引入的 io_uring 多路复用的支持。由于 io_uring 可以减少 syscall 调用次数以及直接的 iov 调用理论上能比 epoll 达到更好的性能。直接的 iov 调用需要 Ruby Fiber 调度器接口上的额外支持。在和 ioquatix 讨论后,Ruby 3.0.0-preview2 开始引入了相关的接口。于是整个 io_uring 的实现需要两个部分,一个是和 epoll 模式兼容的 one-shot polling 相关的代码:
#include <liburing.h>
#define URING_ENTRIES 64
#define URING_MAX_EVENTS 64
struct uring_data {
bool is_poll;
short poll_mask;
VALUE io;
};
void uring_payload_free(void* data);
size_t uring_payload_size(const void* data);
static const rb_data_type_t type_uring_payload = {
.wrap_struct_name = "uring_payload",
.function = {
.dmark = NULL,
.dfree = uring_payload_free,
.dsize = uring_payload_size,
},
.data = NULL,
.flags = RUBY_TYPED_FREE_IMMEDIATELY,
};
void uring_payload_free(void* data) {
io_uring_queue_exit((struct io_uring*) data);
xfree(data);
}
size_t uring_payload_size(const void* data) {
return sizeof(struct io_uring);
}
VALUE method_scheduler_init(VALUE self) {
int ret;
struct io_uring* ring;
ring = xmalloc(sizeof(struct io_uring));
ret = io_uring_queue_init(URING_ENTRIES, ring, 0);
if (ret < 0) {
rb_raise(rb_eIOError, "unable to initalize io_uring");
}
rb_iv_set(self, "@ring", TypedData_Wrap_Struct(Payload, &type_uring_payload, ring));
return Qnil;
}
VALUE method_scheduler_register(VALUE self, VALUE io, VALUE interest) {
VALUE ring_obj;
struct io_uring* ring;
struct io_uring_sqe *sqe;
struct uring_data *data;
short poll_mask = 0;
ID id_fileno = rb_intern("fileno");
ring_obj = rb_iv_get(self, "@ring");
TypedData_Get_Struct(ring_obj, struct io_uring, &type_uring_payload, ring);
sqe = io_uring_get_sqe(ring);
int fd = NUM2INT(rb_funcall(io, id_fileno, 0));
int ruby_interest = NUM2INT(interest);
int readable = NUM2INT(rb_const_get(rb_cIO, rb_intern("READABLE")));
int writable = NUM2INT(rb_const_get(rb_cIO, rb_intern("WRITABLE")));
if (ruby_interest & readable) {
poll_mask |= POLL_IN;
}
if (ruby_interest & writable) {
poll_mask |= POLL_OUT;
}
data = (struct uring_data*) xmalloc(sizeof(struct uring_data));
data->is_poll = true;
data->io = io;
data->poll_mask = poll_mask;
io_uring_prep_poll_add(sqe, fd, poll_mask);
io_uring_sqe_set_data(sqe, data);
io_uring_submit(ring);
return Qnil;
}
VALUE method_scheduler_deregister(VALUE self, VALUE io) {
// io_uring runs under oneshot mode. No need to deregister.
return Qnil;
}
另一部分则是直接的 iov 支持:
VALUE method_scheduler_io_read(VALUE self, VALUE io, VALUE buffer, VALUE offset, VALUE length) {
struct io_uring* ring;
struct uring_data *data;
char* read_buffer;
ID id_fileno = rb_intern("fileno");
// @iov[io] = Fiber.current
VALUE iovs = rb_iv_get(self, "@iovs");
rb_hash_aset(iovs, io, rb_funcall(Fiber, rb_intern("current"), 0));
// register
VALUE ring_obj = rb_iv_get(self, "@ring");
TypedData_Get_Struct(ring_obj, struct io_uring, &type_uring_payload, ring);
struct io_uring_sqe *sqe = io_uring_get_sqe(ring);
int fd = NUM2INT(rb_funcall(io, id_fileno, 0));
read_buffer = (char*) xmalloc(NUM2SIZET(length));
struct iovec iov = {
.iov_base = read_buffer,
.iov_len = NUM2SIZET(length),
};
data = (struct uring_data*) xmalloc(sizeof(struct uring_data));
data->is_poll = false;
data->io = io;
data->poll_mask = 0;
io_uring_prep_readv(sqe, fd, &iov, 1, NUM2SIZET(offset));
io_uring_sqe_set_data(sqe, data);
io_uring_submit(ring);
VALUE result = rb_str_new(read_buffer, strlen(read_buffer));
if (buffer != Qnil) {
rb_str_append(buffer, result);
}
rb_funcall(Fiber, rb_intern("yield"), 0); // Fiber.yield
return result;
}
VALUE method_scheduler_io_write(VALUE self, VALUE io, VALUE buffer, VALUE offset, VALUE length) {
struct io_uring* ring;
struct uring_data *data;
char* write_buffer;
ID id_fileno = rb_intern("fileno");
// @iov[io] = Fiber.current
VALUE iovs = rb_iv_get(self, "@iovs");
rb_hash_aset(iovs, io, rb_funcall(Fiber, rb_intern("current"), 0));
// register
VALUE ring_obj = rb_iv_get(self, "@ring");
TypedData_Get_Struct(ring_obj, struct io_uring, &type_uring_payload, ring);
struct io_uring_sqe *sqe = io_uring_get_sqe(ring);
int fd = NUM2INT(rb_funcall(io, id_fileno, 0));
write_buffer = StringValueCStr(buffer);
struct iovec iov = {
.iov_base = write_buffer,
.iov_len = NUM2SIZET(length),
};
data = (struct uring_data*) xmalloc(sizeof(struct uring_data));
data->is_poll = false;
data->io = io;
data->poll_mask = 0;
io_uring_prep_writev(sqe, fd, &iov, 1, NUM2SIZET(offset));
io_uring_sqe_set_data(sqe, data);
io_uring_submit(ring);
rb_funcall(Fiber, rb_intern("yield"), 0); // Fiber.yield
return length;
}
不过目前不知道为什么 iov 调用没有被 Ruby Scheduler 识别到,目前还在修复相关的问题。不过好消息是至少达到了接近 epoll 的性能了。
IOCP 支持
另一个麻烦的地方是 Windows IOCP 支持。我试图写了一个 IOCP 的调度器:
VALUE method_scheduler_init(VALUE self) {
HANDLE iocp = CreateIoCompletionPort(INVALID_HANDLE_VALUE, NULL, 0, 0);
rb_iv_set(self, "@iocp", TypedData_Wrap_Struct(Payload, &type_iocp_payload, iocp));
return Qnil;
}
VALUE method_scheduler_register(VALUE self, VALUE io, VALUE interest) {
HANDLE iocp;
VALUE iocp_obj = rb_iv_get(self, "@iocp");
struct iocp_data* data;
TypedData_Get_Struct(iocp_obj, HANDLE, &type_iocp_payload, iocp);
int fd = NUM2INT(rb_funcallv(io, rb_intern("fileno"), 0, 0));
HANDLE io_handler = (HANDLE)rb_w32_get_osfhandle(fd);
int ruby_interest = NUM2INT(interest);
int readable = NUM2INT(rb_const_get(rb_cIO, rb_intern("READABLE")));
int writable = NUM2INT(rb_const_get(rb_cIO, rb_intern("WRITABLE")));
data = (struct iocp_data*) xmalloc(sizeof(struct iocp_data));
data->io = io;
data->is_poll = true;
data->interest = 0;
if (ruby_interest & readable) {
interest |= readable;
}
if (ruby_interest & writable) {
interest |= writable;
}
HANDLE res = CreateIoCompletionPort(io_handler, iocp, (ULONG_PTR) data, 0);
printf("IO at address: 0x%08x\n", (void *)data);
return Qnil;
}
VALUE method_scheduler_wait(VALUE self) {
ID id_next_timeout = rb_intern("next_timeout");
ID id_push = rb_intern("push");
VALUE iocp_obj = rb_iv_get(self, "@iocp");
VALUE next_timeout = rb_funcall(self, id_next_timeout, 0);
int readable = NUM2INT(rb_const_get(rb_cIO, rb_intern("READABLE")));
int writable = NUM2INT(rb_const_get(rb_cIO, rb_intern("WRITABLE")));
HANDLE iocp;
OVERLAPPED_ENTRY lpCompletionPortEntries[IOCP_MAX_EVENTS];
ULONG ulNumEntriesRemoved;
TypedData_Get_Struct(iocp_obj, HANDLE, &type_iocp_payload, iocp);
DWORD timeout;
if (next_timeout == Qnil) {
timeout = 0x5000;
} else {
timeout = NUM2INT(next_timeout) * 1000; // seconds to milliseconds
}
DWORD NumberOfBytesTransferred;
LPOVERLAPPED pOverlapped;
ULONG_PTR CompletionKey;
BOOL res = GetQueuedCompletionStatus(iocp, &NumberOfBytesTransferred, &CompletionKey, &pOverlapped, timeout);
// BOOL res = GetQueuedCompletionStatusEx(
// iocp, lpCompletionPortEntries, IOCP_MAX_EVENTS, &ulNumEntriesRemoved, timeout, TRUE);
VALUE result = rb_ary_new2(2);
VALUE readables = rb_ary_new();
VALUE writables = rb_ary_new();
rb_ary_store(result, 0, readables);
rb_ary_store(result, 1, writables);
if (!result) {
return result;
}
printf("--------- Received! ---------\n");
printf("Received IO at address: 0x%08x\n", (void *)CompletionKey);
printf("dwNumberOfBytesTransferred: %lld\n", NumberOfBytesTransferred);
// if (ulNumEntriesRemoved > 0) {
// printf("Entries: %ld\n", ulNumEntriesRemoved);
// }
// for (ULONG i = 0; i < ulNumEntriesRemoved; i++) {
// OVERLAPPED_ENTRY entry = lpCompletionPortEntries[i];
// struct iocp_data *data = (struct iocp_data*) entry.lpCompletionKey;
// int interest = data->interest;
// VALUE obj_io = data->io;
// if (interest & readable) {
// rb_funcall(readables, id_push, 1, obj_io);
// } else if (interest & writable) {
// rb_funcall(writables, id_push, 1, obj_io);
// }
// xfree(data);
// }
return result;
}
但实际发现收到的 I/O 全部都是错误的指针。一番研究后发现,如果要让 IOCP 调度对应的 I/O,该 I/O 在初始化时就要有 FILE_FLAG_OVERLAPPED Flag 的支持。这意味着还需要 Ruby 的 win32/win32.c 中做出一些改进,才能在调度器中正确调度 IOCP。不过 Windows 上的 fallback IO.select 调度器还是能正常使用的,这问题就不大,毕竟谁在乎 Windows 的生产性能呢...
kqueue 支持改进
另一个做出的改进是在 macOS 的 kqueue 上。kqueue 在 FreeBSD 上的性能相当好,但是在 macOS 上就比较拉跨。只能通过减少 syscall 来提高性能。这几个月的一个改进是使用了 kqueue 的 one-shot 模式,来减少一次 deregister 需要的 syscall。
VALUE method_scheduler_register(VALUE self, VALUE io, VALUE interest) {
struct kevent event;
u_short event_flags = 0;
ID id_fileno = rb_intern("fileno");
int kq = NUM2INT(rb_iv_get(self, "@kq"));
int fd = NUM2INT(rb_funcall(io, id_fileno, 0));
int ruby_interest = NUM2INT(interest);
int readable = NUM2INT(rb_const_get(rb_cIO, rb_intern("READABLE")));
int writable = NUM2INT(rb_const_get(rb_cIO, rb_intern("WRITABLE")));
if (ruby_interest & readable) {
event_flags |= EVFILT_READ;
}
if (ruby_interest & writable) {
event_flags |= EVFILT_WRITE;
}
EV_SET(&event, fd, event_flags, EV_ADD|EV_ENABLE|EV_ONESHOT, 0, 0, (void*) io);
kevent(kq, &event, 1, NULL, 0, NULL); // TODO: Check the return value
return Qnil;
}
概览
最后我们把主流的操作系统 I/O 多路复用都写了一遍集成到了我们的事件处理库中,整体情况如下:
| Linux | Windows | macOS | FreeBSD | |
|---|---|---|---|---|
| io_uring | ✅ (见 1) | ❌ | ❌ | ❌ |
| epoll | ✅ (见 2) | ❌ | ❌ | ❌ |
| kqueue | ❌ | ❌ | ✅ (⚠️见 5) | ✅ |
| IOCP | ❌ | ❌ (⚠️见 3) | ❌ | ❌ |
Ruby (IO.select) |
✅ Fallback | ✅ (⚠️见 4) | ✅ Fallback | ✅ Fallback |
- 当编译时检测到
liburing-dev已被安装 - 当 Linux 内核版本 >= 2.6.8
- 在 I/O 初始化过程中
FILE_FLAG_OVERLAPPEDflag 被引入前 无法工作。 - 一些 I/O 在 Windows 下无法变成非阻塞 I/O,详见 调度器文档.
-
kqueue在 Darwin 下的一些特殊情况性能很烂,可能会在未来被禁用。
基准测试
那么总体性能如何呢?
下面的测试是在 evt v0.2.2 和 Ruby 3.0.0-rc1 上运行的,详细的测试代码见 evt-server-benchmark。测试仅使用单线程服务器。
测试命令是 wrk -t4 -c8192 -d30s http://localhost:3001.
| 操作系统 | CPU | 内存 | 后端 | 请求/秒 |
|---|---|---|---|---|
| Linux | Ryzen 2700x | 64GB | epoll | 54680.08 |
| Linux | Ryzen 2700x | 64GB | io_uring | 50245.53 |
| Linux | Ryzen 2700x | 64GB | Ruby (使用 poll) | 44159.23 |
| macOS | i7-6820HQ | 16GB | kqueue | 37855.53 |
| macOS | i7-6820HQ | 16GB | Ruby (使用 poll) | 28293.36 |
相当惊人。这个结果有几方面因素。现在的 Falcon 等异步框架使用的都是基于 nio4r 来实现的,其背后是 libev。libev 在各个异步事件库中的性能本来就是比较一般的,再加上其为了更好的兼容性做了大量的妥协。另一方面,以前的调度库需要大量 Ruby 元编程帮助,而现在几乎都是在 C extension 间完成的,性能也有了很大的提升。
另外比起我们之前在 preview1 上做的测试,这个版本的 Fiber 调度器修复了大量的错误,而 wrk 的测试结果是非常错误敏感的,这使得我们最终的请求速度比起之前又提升了 10 倍。
与 Ractor 结合
我在 2020 年 11 月 17 日写过一篇关于 Ractor 的扫盲贴 《Ractor 下多线程 Ruby 程序指南》,Ractor 和 Fiber 的结合始终是一个有意思的话题。目前情况下 Fiber 与 Ractor 结合来实现 Web 服务器有两个可能的路径:
- 在主 Ractor 部署一个调度器,用来处理请求的 accept。将请求派发到子 Ractor 中,由子线程进行处理后将返回值传回主 Ractor 中进行请求返回。
- 利用 Linux 内核
SO_REUSEPORT特性让多个 Ractor 同时监听请求,即可直接将单线程服务器扩展成多线程服务器。
比较可惜的是,目前这两者都是无法实现的。因为目前 Fiber 的一些特性无法在 Ractor 中使用。我个人倾向认为这是误报,目前已提交了一个 patch GitHub #3971。根据我之前的测试,Ractor 的加入在实际上应该还能再提升 4 倍左右的吞吐量。不过由于 API 服务器通常是无状态的,主要矛盾也不是 CPU-bound,所以这些吞吐量也是可以由多进程来实现的,Ractor 的引入更多是比起多进程实现的内存消耗降低。
等 Ruby 3.0 更新后我们可以进一步测试。
总结
这比起 preview1 10 倍的性能提升,和比起以前阻塞 I/O 近 36 倍的性能提升足以证明 Ruby 目前服务器的性能问题的本质是 I/O 阻塞问题,而不是 Ruby CPU 执行慢的问题。而随着 I/O 调度器的引入,Ruby 3 的 I/O 性能能更上一个台阶。接下来我们要等待的就是一些使用 C 原生组件的,比如数据库驱动和 Redis 驱动的更新。然后使用一个基于 Fiber 的 Web 服务器,例如 Falcon。无需任何业务上代码的变化,就能得到数倍甚至数十倍的性能提升。
让我们继续享受 Ruby 的快乐编程。
更新
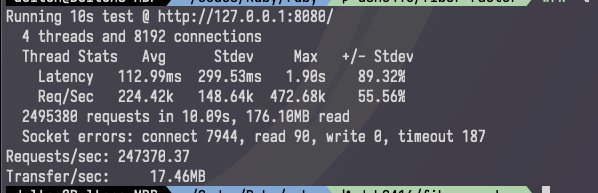
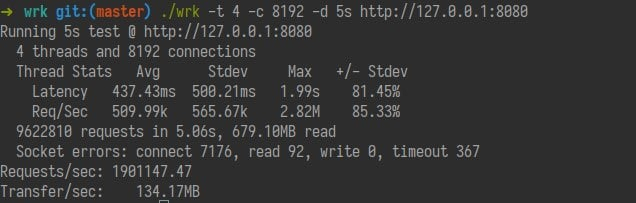
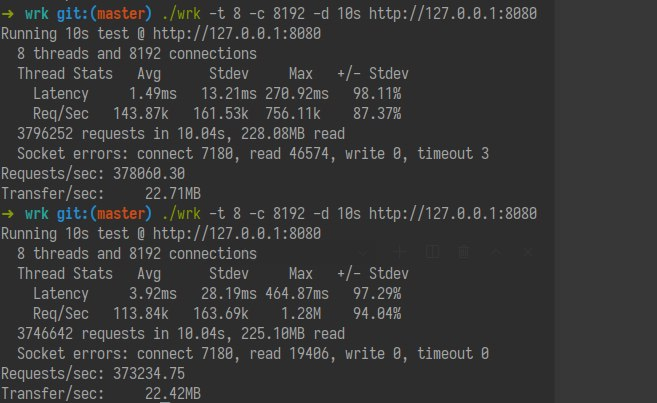
wrk 对于错误非常敏感,这个 benchmark 中的 parser 有问题,无法准确关闭 socket。把我的 Midori 重新捡起来改成了 Ruby 3 Scheduler 项目。性能在 kqueue 达到了 247k req/s 单线程!达到了上百倍的性能提升。epoll 上能达到 627k req/s!
 真 3*3
真 3*3