信息架构设计是对信息进行结构、组织方式以及归类的设计,好让使用者与用户容易使用与理解的一项艺术与科学。信息架构是内容性网站的基石,包括组织系统,标签系统,导航系统,搜索系统,推荐系统等。下面来谈谈标签系统的信息架构设计。
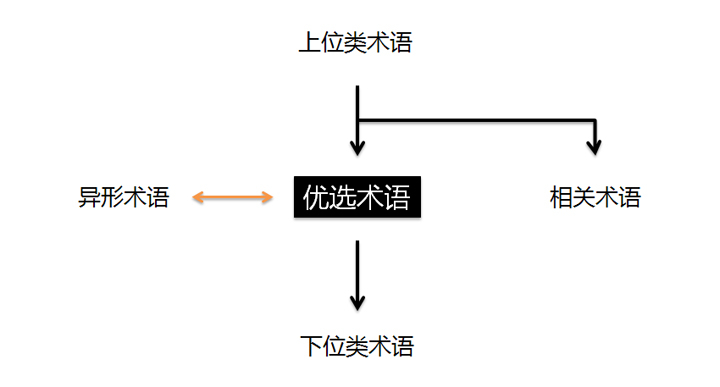
优选术语和同义词环
举个简单的例子,一个大众标签网站,任何人可以对网页打标签,任何人可以搜索和通过标签过滤网页。这个问题看似很简单,但实现起来并不容易,因为不同用户对标签术语的选择并不相同,比如拿「开源软件」这个标签来说,可选术语包括:opensource、Open Source、OSS、开源、开源项目、开源软件、open source software等。
而我们的需求是,即使不同人使用的术语不同,用户在使用标签过滤或搜索的时候,使用其中任意一个术语,就可以找到相关的网页。
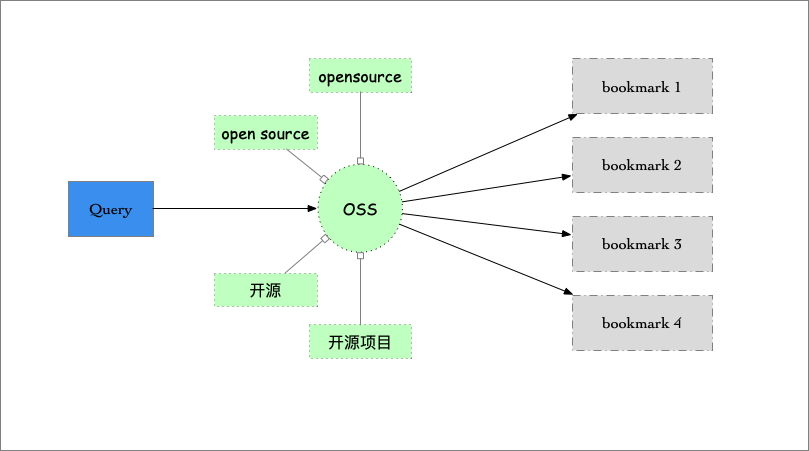
这类需求就要引入信息架构里的同义词环圈(synonym ring)和优选术语(preferred terms)的概念。
下面来简单的写一下使用 Postgres 实现这样的标签系统的方法:
表结构:
# tagging
## bookmarks
name | column_type | ext_info | ref | default | comment
----------------------------- | ----------- | ------------------------- | --- | ------- | -------
id | integer | [pk, increment, not null] | | |
url | integer | [null] | | |
title | integer | [null] | | |
user_id | integer | [null] | | |
cached_tag_names | varchar | [null] | | |
cached_tag_ids | int[] | [not null] | | {} |
cached_tag_with_aliases_ids | int[] | [not null] | | |
cached_tag_with_aliases_names | varchar | [null] | | |
## tags
name | column_type | ext_info | ref | default | comment
------------ | ----------- | ------------------------- | ---------------- | ------- | -------
id | integer | [pk, increment, not null] | | |
name | varchar | [null] | | |
preferred_id | integer | [null] | [tags.id](#tags) | |
auto_extract | boolean | [not null] | | |
## taggings
name | column_type | ext_info | ref | default | comment
----------- | ----------- | -------- | -------------------------- | ------- | -------
id | integer | [null] | | |
tag_id | integer | [null] | [tags.id](#tags) | |
bookmark_id | integer | [null] | [bookmarks.id](#bookmarks) | |
ERD:

Ruby:
def sync_cached_tag_ids
last_tags = tags.preload(:aliases).reload
update(
cached_tag_with_aliases_ids: last_tags.map { |t| [t, t.aliases.to_a] }.flatten.map(&:id).uniq,
cached_tag_with_aliases_names: last_tags.map { |t| [t, t.aliases.to_a] }.flatten.map(&:name).uniq.join(", "),
cached_tag_ids: last_tags.map(&:id),
cached_tag_names: last_tags.map(&:name).join(", ")
)
end
原理就是每次 tagging model 有更新的时候,把 aliases ids 和 names 一起同步到缓存字段里。过滤的时候使用 Postgres 的数组&&操作符:
def self.tag_filter(scope, tag_name)
tag = Tag.find_by!(name: tag_name)
tag_ids = tag.self_with_aliases_ids
scope.where("cached_tag_with_aliases_ids && ?", Util.to_pg_array(tag_ids))
end
再加个 GIN index:
add_index :bookmarks, :cached_tag_with_aliases_ids, using: :gin
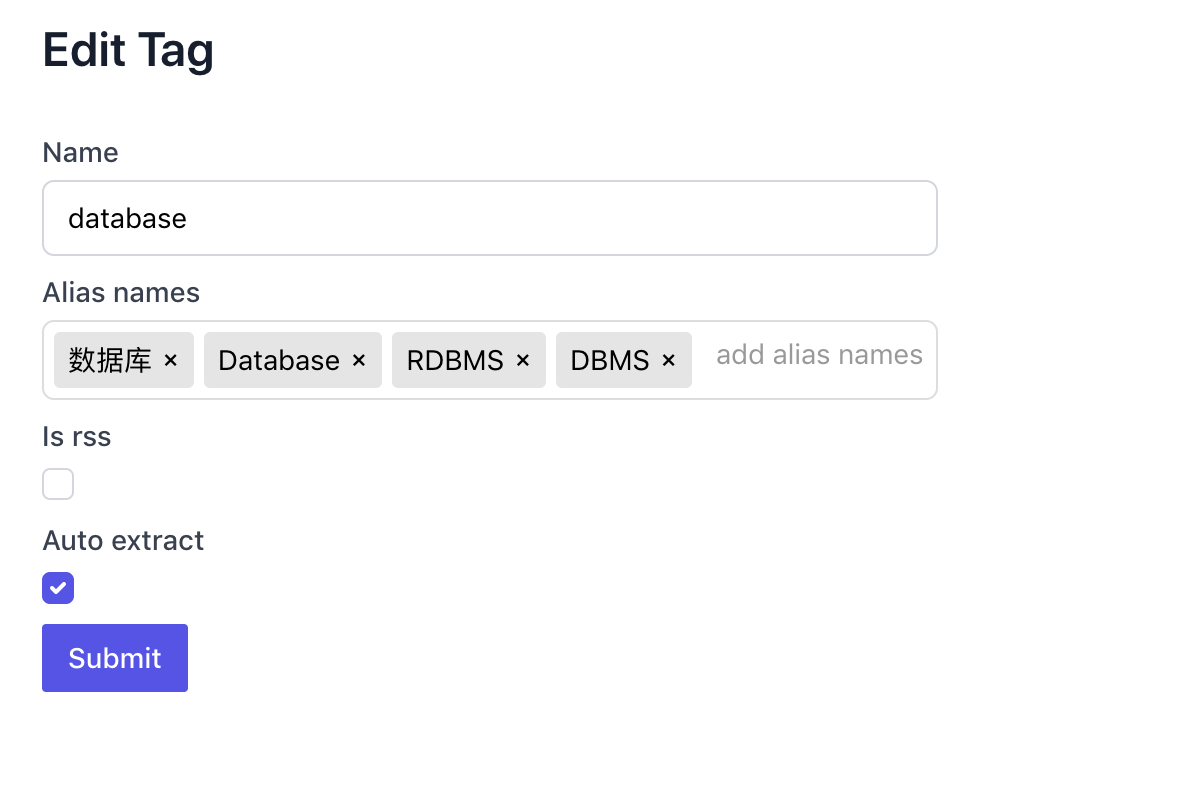
后台管理优选术语和同义词环
后台 Admin 管理同义词标签:
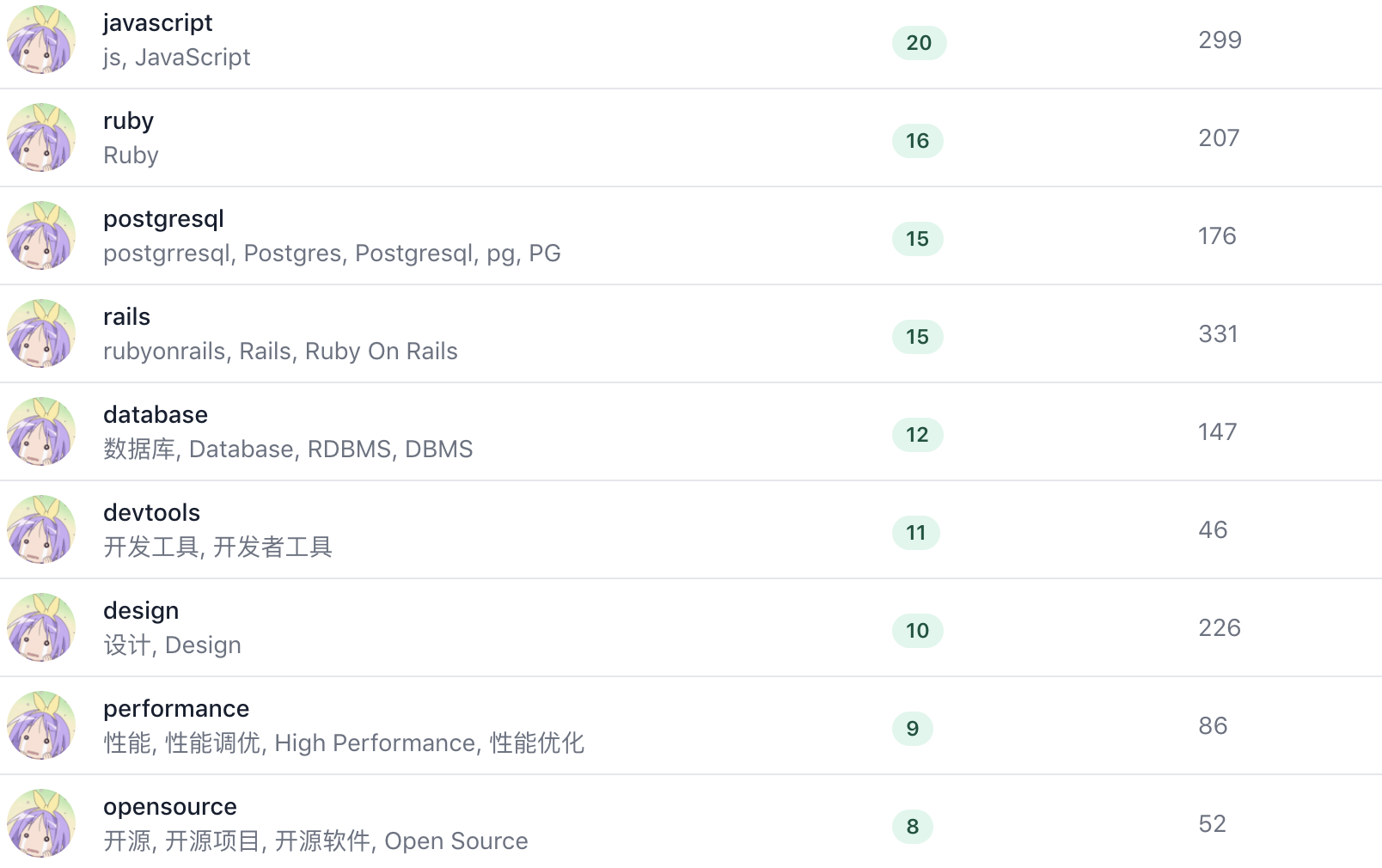
还可以增强的一个功能是,可以基于文本相似和协同过滤的方式,把可能是同义词的标签列出来,便于管理员管理。
标签自动提取
标签自动提取非常有意思,目前使用基于白名单的方案,如果网页上有和已有标签匹配上的内容,我们就打上标签。不过也需要参考词频和权重,还有黑名单。比如像 HTML,HTTP,HTTPS 这些常见的词,打上标签没有任何意义。 这个过程和全文检索是一个相反的过程,拿文档去匹配关键词,然后按相关度打分取 TopN。
class ExtractTag
prepend SimpleCommand
include ActiveModel::Validations
attr_reader :bookmark
def initialize(bookmark)
@bookmark = bookmark
end
def call
tags = Tag.find_by_sql(<<~SQL)
SELECT DISTINCT
tags.*,
bookmarks.tsv <=> plainto_tsquery('zh', name) AS rev_score
FROM bookmarks, tags
WHERE bookmarks.id = #{bookmark.id}
AND plainto_tsquery('zh', tags.name) @@ bookmarks.tsv
AND tags.name not IN (#{Util.stop_words_for_where})
AND length(tags.name) >= 3
AND tags.auto_extract = 't'
ORDER BY rev_score ASC
LIMIT 10
SQL
tags = tags.map(&:preferred_or_self)
tags = tags.group_by do |tag|
tag.name.downcase.gsub(/-\s/, "")
end.map { |name, records| records.sort_by { |record| record.preferred_id || 0 }[0] }
tags.flatten.uniq[0, 3]
end
end
基于标签的推荐
如果标签打的很准确,基于标签的相似效果其实也会很好,效果并不一定比协同过滤或文本相似度差。下面实现一个基于标签的相似推荐,使用 RUM 索引:
CREATE INDEX idx_similar_by_tag ON bookmarks USING rum (cached_tag_with_aliases_ids rum_anyarray_ops)
测试一下效率还是非常高的,对于没有标签的网页,使用文本相似度,即:使用标题去做全文检索,不过是 OR 规则的匹配。
class SimilarByTag
prepend SimpleCommand
include ActiveModel::Validations
attr_reader :bookmark, :limit
def initialize(bookmark, limit = 6)
@bookmark = bookmark
@limit = limit
end
def call
pg_ids = Util.to_pg_array(bookmark.cached_tag_with_aliases_ids)
return Bookmark
.original
.where("cached_tag_with_aliases_ids && ?", pg_ids)
.where.not(id: bookmark.id)
.order("cached_tag_with_aliases_ids <=> '#{pg_ids}'")
.limit(limit) if bookmark.cached_tag_with_aliases_ids.present?
return Bookmark
.original
.where("bookmarks.tsv @@ replace(plainto_tsquery('zh', E'#{Util.escape_quote bookmark.title}')::text, '&', '|')::tsquery")
.where.not(id: bookmark.id)
.select("bookmarks.*, bookmarks.tsv <=> replace(plainto_tsquery('zh', E'#{Util.escape_quote bookmark.title}')::text, '&', '|')::tsquery AS relevance")
.order("relevance ASC")
.limit(limit) if bookmark.title.present?
[]
end
end