了解我的小伙伴都知道我最近自己在做一个社区的小程序,希望能帮助大家能无代码创建一个社区小程序。社区里内容是很重要的一块,但往往很多时候会有人来发一些开车(麻烦前面右拐 P 站,谢谢)内容,所以最基本的防控还是要有的。
作者本人独立开发者,接各种前后端外包、兼职工作。无论是工作、技术交流、项目讨论,都欢迎加我进行交流
词库的准备
首先我们可以从网上下载词库,不过我下载的词库有些时候了,谁有新版的词库也可以告知我一下,我好更新下。
DFA 算法
一般想到的是遍历匹配,但这样效率太差了。另外一种是正则表达式,直观上感觉也很差。
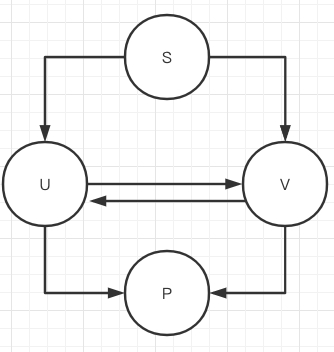
查了下资料,比较简单容易实现的是 DFA 算法。DFA(Deterministic Finite Automaton,即确定有穷自动机。其原理为:有一个有限状态集合和一些从一个状态通向另一个状态的边,每条边上标记有一个符号,其中一个状态是初态,某些状态是终态。但不同于不确定的有限自动机,DFA 中不会有从同一状态出发的两条边标志有相同的符号。
因为只有状态的变化,没任何运算,在效率上还是相对比较可观,要说唯一的缺点嘛,那应该就是比较吃内存,因为相当于你需要把一整棵树都存在内存上。
就上图来说,通过查找,一步步从 S 查找到 P。
例子
假设我们词库里有以下 2 个敏感词:成人论坛、成人电影,首先我们要建立一个这样的结构。
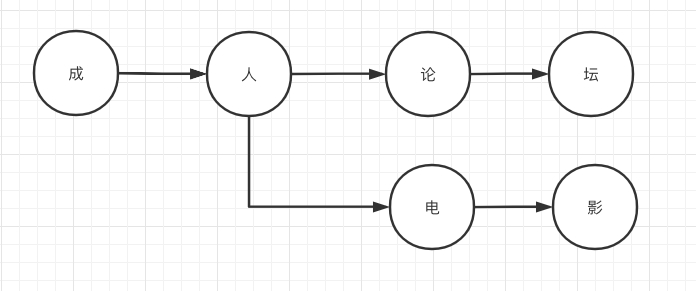
这样就能大幅度的减少我们检索的范围了。那我们怎么判断一个敏感词的检测已经结束了呢,那就需要加一个标志位来确认。
具体流程
1.清洗数据
假设我们有一段 如下内容
*-`J情成&^人电影在**$#线观看
这个时候我们第一步是对内容做清洗,把特殊的标点符号去除,变成纯文字
J情成人电影在线观看
2.字符穷举
首页我们对上面的文字进行穷举,列出我们需要检测的所有的可能性
J
J情
J情成
J情成人
J情成人电
J情成人电影
J情成人电影在
J情成人电影在线
J情成人电影在线观
J情成人电影在线观看
检测
前两次检测不出来,在第三次,字符”成“命中了上图的关键字。
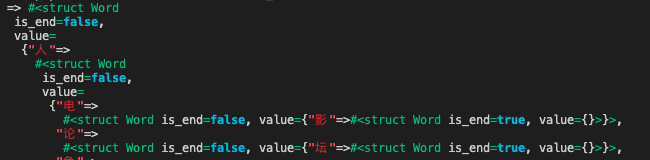
那我们就再次把当前检测的节点从”成“换成了”人“这个节点,以此类推。

下面附上源码的实现
源码
require “set"
require “pry”
require ‘active_support/core_ext’
Word = Struct.new(:is_end, :value)
class FilterSensitiveWord
attr_accessor :words
MIN_MATCH_TYPE = 1
MAX_MATCH_TYPE = 2
def initialize()
@hash = Hash.new
end
def load(file_path)
@words = Set[]
f = File.open(file_path, “r”)
f.each_line do |line|
@words.add(line)
end
f.close
to_hash(@words)
end
def to_hash(words)
words.map do |word|
word_hash = @hash
word.strip.chars.to_a.map.with_index do |c,index|
if word_hash[c].blank?
if word.strip.length - 1 == index
word_hash[c] = Word.new(true,Hash.new)
else
word_hash[c] = Word.new(false,Hash.new)
word_hash = word_hash[c].value
end
else
word_hash = word_hash[c].value
end
end
end
@hash
end
def check_sensitive_word(txt, index, match_tpye)
match_flag = 0
word_hash = @hash
flag = false
txt.each do |w|
if word_hash[w].blank?
break
else
match_flag = match_flag + 1
if word_hash[w].is_end
flag = true
if match_tpye == MIN_MATCH_TYPE
break
end
else
word_hash = word_hash[w].value
end
end
end
unless flag
match_flag = 0
end
match_flag
end
def check(text,match_tpye)
words = []
skip_len = 0
text = text.strip.gsub(/[`~!@#$^&*()=|{}':;',\\\[\]\.<>\/?~!@#¥……&*()——|{}【】';:""'。,、?]/,'')
if text.present?
text.chars.each_with_index do |c, i|
if skip_len > i
next
end
len = check_sensitive_word(text.chars.drop(i), i, match_tpye)
if len > 0
words.push text[i, len]
skip_len = i + len - 1
end
end
end
words
end
end
$filter_sensitive_word = FilterSensitiveWord.new()
$filter_sensitive_word.load("./words/广告.txt")
$filter_sensitive_word.load("./words/政治类.txt")
$filter_sensitive_word.load("./words/涉枪涉爆违法信息关键词.txt")
$filter_sensitive_word.load("./words/色情类.txt")
puts $filter_sensitive_word.check("*-`J情成&^人电影在**$#线观看",1)
总结
总的来说,除了内存的问题,性能上没任何问题。
在 2020 年,这种检测方式显然很落后,但如果作为第一层过滤,效果还是蛮可观的。进来的内容,最好的方式肯定是基于深度学习和 NLP 自然语义分析,这些可以去调各大厂云平台的接口。最后一层还是人工,前端举报和后端抽查和内容审核。
参考资料
- java 敏感词之 DFA 算法 (Tire Tree 算法)
- java 实现敏感词过滤(DFA 算法)

