我们都知道,消息队列有三好:异步、解耦、消峰。解耦和消峰的话,要访问量比较大的应用才需要,但异步几乎所有规模的应用都有需求,即使是一个小论坛,注册发邮件一般都是异步处理的。
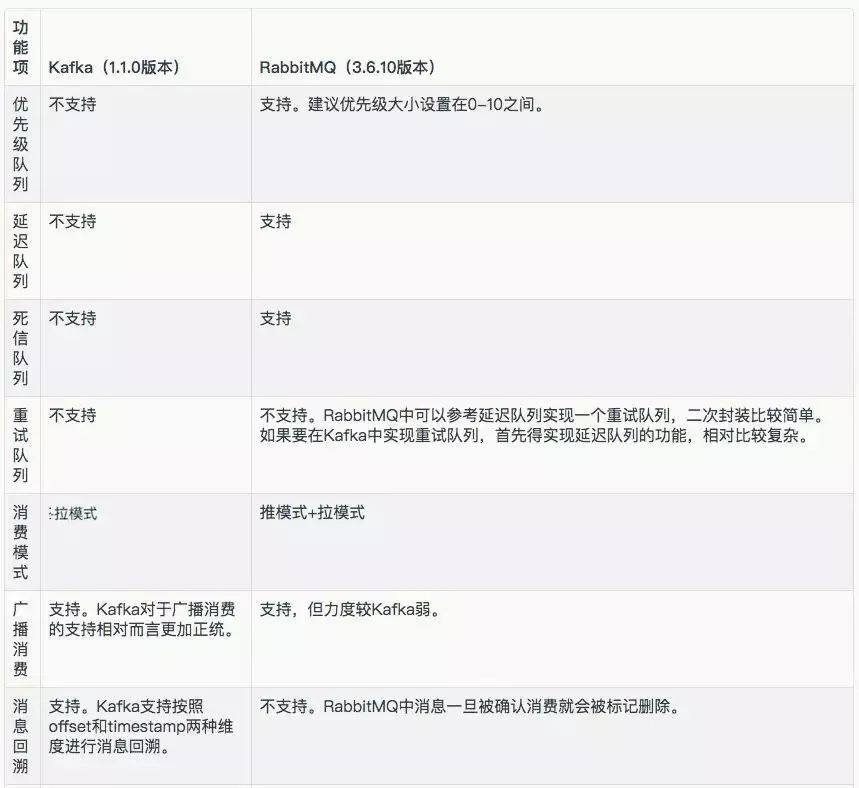
市面上的的流行消息队列方向更多侧重于性能和吞吐量,但一些需求上的特性都不重视,比如 kafka 和 rabbitmq 都不支持“定时消息”,即,如果想实现“五分钟之后做某事”这样的需求,用 kafka 和 rabbitmq 是不容易实现的。
Rails 社区流行的消息队列主要是 sidekiq,局限于 Ruby。Sidekiq 由于使用 Redis 做存储,速度还算不错,但由于和 redis 绑定紧密,带来一些功能上的限制,比如持久化消息不容易做,所以 sidekiq 的消息是用完即失。对于一些场景,持久化消息其实是非常有必要的,比如审计、追踪、重新消费等。
最近产生了用 postgres 实现一个消息队列的想法,结合之前使用的需求,大概列了一下功能点,感觉用 postgres 实现起来性能也不会太差。
- [x] multiple named queues
- [x] exactly once
- [x] priorities
- [x] delayed jobs
- [x] persistent jobs
- [x] retries with backoff
- [ ] cron job
- [ ] broadcast msg to multiple queues
- [ ] job dependencies
- [ ] rate limiting
- [ ] unique jobs
- [ ] expire jobs
- [ ] concurrent num & priority by tenant for SaaS
- [ ] statistics & web ui
- [ ] fast re-queue
- [ ] distributed workers
- [ ] batch processing
于是就有了这个 pgmq:https://github.com/hooopo/pgmq
worker 是基于 faktory 魔改的,faktory 已经把多线程调度之类做好了,没必要再费事。Broker 是基于 Postgres,不依赖 Redis or Faktory server,如果你现有的应用就是 pg 可以使用同一个库,也可以使用独立的库。
本机测试了一下,一分钟可以处理 10w+,还有一些优化空间。
由于是基于 Postgres 的,上面的这些需求实现起来非常简单,并且非常透明,因为数据都在 table 里,不像 sidekiq 和 faktory 还有自己的协议。
pgmq 不限制语言,所以看一下表结构就可以用其他语言撸客户端和 web UI 了。
PS. 目前只是把 demo 跑起来了,super alpha,不要生产用,如有需要请留言。