Sneaker是基于 Ruby 的高性能 RabbitMQ 消费者,可以便捷地嵌入 Rails 应用,以常驻进程的方式处理 RabbitMQ 消息,运行模式类似 Sidekiq。本文简单介绍下 Sneaker 背后的工作方式,内容大概包含以下几个方面:
- Sneaker 的工作模型
- Bunny 如何接收、分发消息
Sneaker 的工作方式
Sneaker 借助ServerEngine实现进程模型搭建,可以有多进程、多线程等四种工作方式,都大同小异。本文只介绍默认的多进程方式,类似 Unicorn 的Master-Workers进程模型:
- Master 创建 (fork)Worker 进程,只接收外部命令,可控制 Worker 进程的工作状态
- Workers 进程处理 MQ 消息,各自独立,工作内容完全一样
- Master 和 Workers 通过 pipe 通信
- Worker 进程可以有多个
这是一个 sneaker 的业务worker,通过它来进行业务逻辑处理,每个业务 worker 会去消费一个特定queue的消息。
# 业务worker
# app/workers/comsumer_worker.rb
class ComsumerWorker
include Sneakers::Worker
from_queue 'downloads',
:prefetch => 50,
:exchange => 'dummy',
:heartbeat => 5,
:amqp_heartbeat => 10
def work(msg) # 处理业务逻辑
ack!
end
end
# rake任务
WORKERS=ComsumerWorker rake sneakers:run
Sneaker 可以通过上面的 rake 任务来启动,如果不通过 WORKERS 环境变量指定要运行的业务 worker,则会默认运行所有的业务worker任务。
启动的流程为以下几个阶段:
- 通过 ServerEngine 来fork 出子进程,其中 子进程的数量由配置决定
- 子进程遍历对应的业务 worker,通过
Bunny注册queue与绑定关系,并 注册回调函数处理业务逻辑,订阅消息 - Bunny 订阅消息时,会创建
消费者, 并在 RabbitMQ 注册消费者,消费者会指定消费某一个 queue 中的消息,上一步的回调函数也会传递给消费者,每个消费者有唯一标示 (tag)
执行结果是:
- 有一个或多个子进程,彼此相互隔离,工作内容一样,会同时运行所有
业务worker - 子进程中,每个业务 worker 会默认有独自的网络连接,也可以在子进程中共用用同一个连接
- 子进程中,每个业务 worker 默认有一个
Concurrent::FixedThreadPool线程池 (大小可配置),被回调的业务逻辑代码会被丢到线程池中并发运行,子进程中也可以共用同一个线程池 - 每个 queue 的消费者会将 MQ 过来的消息通过回调函数往上层传递,并触发业务逻辑回调,业务逻辑会被丢到线程池中
- 线程池一直不停地执行池中的任务
Sneaker 就是不断地把消费者传递过来的消息和业务逻辑打包在一起,丢到对应的线程池中,等待被执行。一图胜千言:
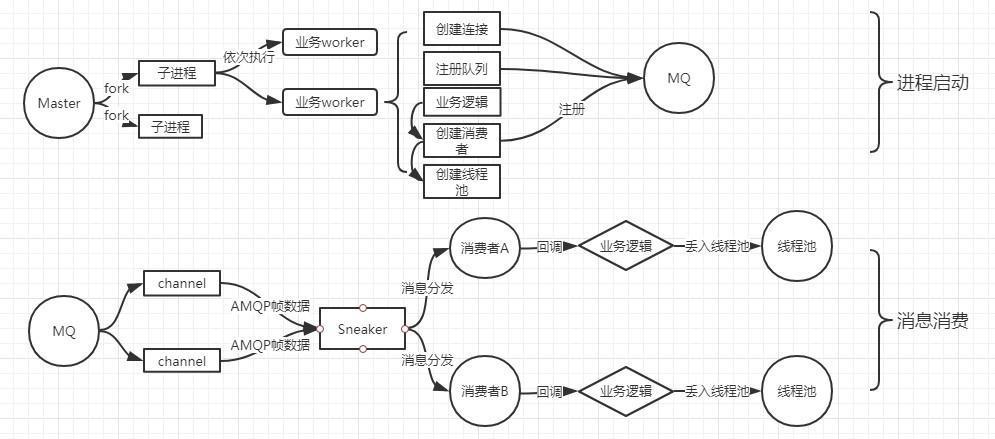
总结一下要点:
- 消息是由消费者通过回调函数传递回应用,丢入线程池,达到高性能、解耦的作用
- 实际的业务逻辑是在线程池中被执行的,线程池一直被动等待任务
应用端的执行逻辑入上图,相对简单。接下来,将注意力放到下面几个问题:
- MQ 中的消息是如何到达消费者的?
- 回调逻辑是如何触发的?
Bunny 如何工作
Bunny 是协议库,用来处理和 MQ 之间的网络连接、AMQP 对象的抽象、解析并发送 AMQP 消息,有以下几个核心对象:
- session,网络连接,是一个 TCP 长连接
- channel,基于 session,可创建多个,每个 channel 有一个 id
- 消费者,基于 channel,可有多个,消费对应 queue 的消息,有自己的 tag
- queue,对应 MQ 的 queue
- exchange,对应 MQ 的 exchange
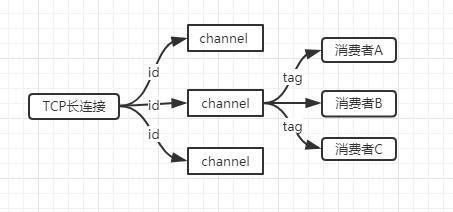
一个 session 中可以存在多个 channel,由 id 来区分彼此;一个 channel 中可以存在多个消费者,以 tag 来区分彼此。这样一方面通过复用 TCP 连接,很好地提升了网络传输的性能,另一方面也有很清晰的层级关系。
AMQP 的消息体比较复杂,大概分为三部分:
- headers (类比 HTTP 协议的 headers)
- payload (类比 HTTP 协议的消息体)
- end (类比 HTTP 协议的换行符)
headers 中有 method(类似 HTTP),content-type,length 等等属性。同一个 TCP 通道,可以传输多个 channel、多个消费者的消息。因为 method 为basic.delivery的 AMQP 帧数据中包含了:
- channel ID,区分信道
- cusumer TAG,区分消费者
- queue_name,区分队列
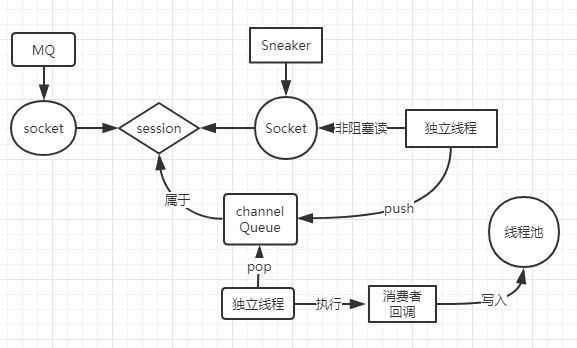
通过解析这些参数,就可以将帧数据转发给对应的 channel,channel 再将数据转发给消费者,消费者就会向前面说的那样触发回调。
帧数据是通过 session 而来,也就是从 TCP 长连接的 socket 中读出来的。session 会创建一个线程,不停地通过非阻塞的方式读取 socket 中的数据:
#https://github.com/ruby-amqp/bunny/blob/master/lib/bunny/cruby/socket.rb#L49
def read_fully(count, timeout = nil)
# 有删减
value = ''
begin
loop do
value << read_nonblock(count - value.bytesize) # 非阻塞读
break if value.bytesize >= count
end
rescue EOFError
end
value
end # read_fully
顺带介绍一下,Bunny 如何读取完整的一帧数据:
#https://github.com/ruby-amqp/bunny/blob/master/lib/bunny/transport.rb#L241
def read_next_frame(opts = {}) # 有删减
header = read_fully(7) # 先读前七个字节,header
type, channel, size = AMQ::Protocol::Frame.decode_header(header) # 解析header,得到数据长度size
payload = if size > 0
read_fully(size) # 读取完整的数据,payload
else
''
end
frame_end = read_fully(1) # 读取结尾
AMQ::Protocol::Frame.new(type, payload, channel)
end
上面的线程把从 socket 中读到的数据,打包成一个代码块,写入对应 channel的一个队列中,这个代码块中包含了对应消费者的业务逻辑回调。
每个 channel 除了有上面所说的队列之外,还会有一个线程,这个线程不断地从队列中pop出代码块来执行,也就是这样触发了消费者的回调。这里也是一个解耦合的设计,通过一个队列作为中转站,将代码逻辑很巧妙地做了分层。
以一张图结束本文:
国庆快乐!
