对于内容类网站或者 APP,搜索和推荐已经是标配。搜索相对容易,使用 Elasticsearch 简单配置一下就可以做出一个性能还不错效果也还可以的搜索引擎,然而,推荐系统的话,没有专门的团队实践起来还挺困难的。
网上推荐系统相关的理论非常多,但可用的实践却少见,要么是介绍相似度算法的 demo,要么是讲高大上架构的文章,看懂这些离真正实现一个推荐系统还差着十万八千里。本文的重点不是介绍原理,也不是探讨算法优劣,侧重点在于如何基于 Postgres 快速落地一个性能还不错的推荐系统。
准备工作
通过movielens.sql创建一个 movielens 数据库
createdb movielens
curl https://raw.githubusercontent.com/ankane/movielens.sql/master/movielens.sql | psql -d movielens
主要包含以下关系表,其中 ratings 表大概 10w 左右的数据:
\d ratings
Table "public.ratings"
Column | Type | Modifiers
----------+-----------------------------+-----------
id | integer | not null
user_id | integer |
movie_id | integer |
rating | integer |
rated_at | timestamp without time zone |
\d movies
Table "public.movies"
Column | Type | Modifiers
---------------+------------------------+-------------------------
id | integer | not null
title | character varying(255) |
release_date | date |
\d users;
Table "public.users"
Column | Type | Modifiers
---------------+------------------------+-----------
id | integer | not null
age | integer |
gender | character(1) |
occupation_id | integer |
zip_code | character varying(255) |
另外还需要一个 Rails 项目:https://github.com/hooopo/movielens-rails-app
相似度算法
“推荐系统中,推荐算法分为两个门派,一个是机器学习派,另一个就是相似度门派。机器学习派是后起之秀,而相似度派则是泰山北斗,以致撑起来推荐系统的半壁江山。”
相似度的算法非常多,下面来介绍一下常用的相似度算法以及 Ruby 代码实现。
Jaccard Similarity
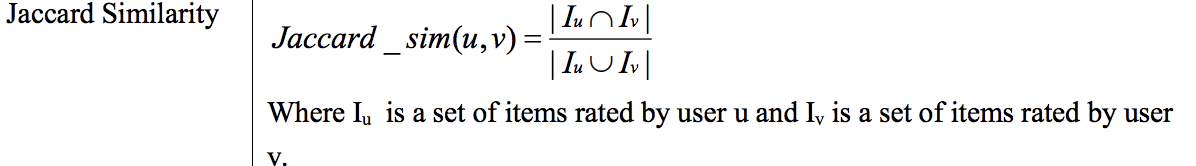
Jaccard 相似度,是两个集合的交集元素个数在并集中所占的比例。由于集合非常适用于布尔向量表示,所以 Jaccard 相似度简直就是为布尔值向量私人定做的,即 Jaccard 相似度非常适合做隐式反馈数据,比如收藏行为、加购物车行为、点击行为等。
def jaccard_sim(other_movie)
# 假设评分大于等于3的为喜欢
other_user_ids = other_movie.ratings.where("rating >= 3").pluck(:user_id)
user_ids = self.ratings.where("rating >= 3").pluck(:user_id)
# 交集数量
intersection = (other_user_ids & user_ids).count
# 并集数量
union = (other_user_ids | user_ids).count
return 0 if union.zero?
intersection.to_f / union.to_f
end
Cosine Similarity
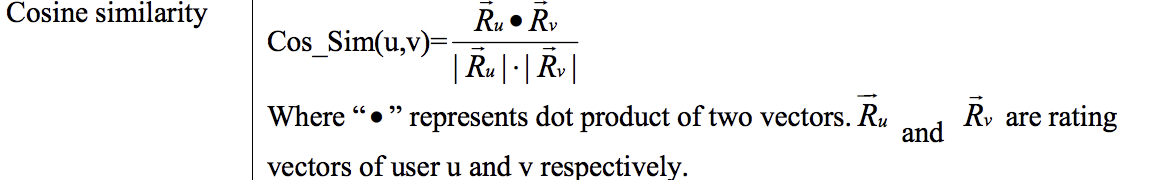
余弦相似度在度量文本相似度、用户相似度、物品相似度的时候都较为常用,它与向量的长度无关。
def cosine_sim(other_movie)
other_user_ratings = other_movie.ratings.map { |r| [r.user_id, r.rating] }.to_h
user_ratings = self.ratings.map { |r| [r.user_id, r.rating] }.to_h
# 有共同评价的用户
union_user_ids = other_user_ratings.keys & user_ratings.keys
return 0 if union_user_ids.count == 0
u = other_user_ratings.values_at(*union_user_ids)
v = user_ratings.values_at(*union_user_ids)
dot_product = u.zip(v).map { |a, b| a*b }.sum
magnitude_u = Math.sqrt(u.map { |x| x*x }.sum)
magnitude_v = Math.sqrt(v.map { |x| x*x }.sum)
cosine_similarity = dot_product.to_f / (magnitude_v * magnitude_u)
end
Pearson Correlation

皮尔逊相关度,实际上也是一种余弦相似度,不过先对向量做了中心化,向量 p 和 q 各自减去向量的均值后,再计算余弦相似度。皮尔逊相关度和修正后的余弦相似度很像,但其实是有差别的,主要区别是均值的定义不同。
def pearson_sim(other_movie)
other_user_ratings = other_movie.ratings.map { |r| [r.user_id, r.rating] }.to_h
user_ratings = self.ratings.map { |r| [r.user_id, r.rating] }.to_h
# 有共同评价的用户
union_user_ids = other_user_ratings.keys & user_ratings.keys
n = union_user_ids.count
return 0 if n == 0
u = other_user_ratings.values_at(*union_user_ids)
v = user_ratings.values_at(*union_user_ids)
sum_u = u.sum
sum_v = v.sum
sum_u_sq = u.map { |x| x*x }.sum
sum_v_sq = v.map { |x| x*x }.sum
prod_sum = u.zip(v).map { |x, y| x*y }.sum
num = prod_sum - ((sum_u * sum_v) / n.to_f)
den = Math.sqrt((sum_u_sq - (sum_u * sum_u) / n.to_f) * (sum_v_sq - (sum_v * sum_v) / n.to_f))
return 0 if den == 0
[num / den, 1].min
end
最后,做下演示:
movie = Movie.first
movie.recommendation_movies(limit: 10, using: :jaccard_sim)
基于 Postgres 的推荐系统
上面代码的目的是为了学习三种算法的实现,所以没有复用,也没有性能方面的优化。纯 Ruby 来做推荐基本不靠谱,所以我们来试一下基于 Posgres 和 Jaccard 相似度来实现一个推荐系统。
首先上面 Ruby 代码里假设 rating 大于 3 就是喜欢,这并不十分准确,有些人评分可能非常严格,他只打 1-3 分,那么对于他来说,其实 3 分就算喜欢了。
为了应对这种情况,我们用用户均值来推断他是否喜欢一部电影。另外我们要便于以后计算方便,把计算结果先缓存到 movies 的 like_user_ids 字段上。
# 增加缓存字段like_user_ids,存储喜欢这部电影的用户ID
def change
add_column :movies, :like_user_ids, :integer, :array => true, :default => '{}'
end
# 使用PG内置扩展intarray:https://www.postgresql.org/docs/current/static/intarray.html
# 对intarray的求交集操作可以利用gin or gist索引
def change
enable_extension :intarray
end
def change
execute <<-SQL
CREATE INDEX like_user_ids_idx_2 ON movies USING gin(like_user_ids gin__int_ops);
SQL
end
第一次,批量初始化 like_user_ids 字段,单条记录更新可以实时计算出来填充进去。
WITH avg_rating_per_user AS (
SELECT movie_id,
user_id,
rating,
AVG(rating) OVER (PARTITION BY user_id) AS avg_rating
FROM ratings
),
rating_per_movie AS (
SELECT movie_id,
array_agg(user_id) AS like_user_ids
FROM avg_rating_per_user
WHERE rating > avg_rating
GROUP BY movie_id
)
UPDATE movies AS m
SET like_user_ids = r.like_user_ids
FROM rating_per_movie AS r
WHERE r.movie_id = m.id;
实时查询方案
def recommend_by_sql(limit: 10)
Movie.find_by_sql(<<~SQL)
SELECT array_length(m.like_user_ids & movies.like_user_ids, 1) / array_length(m.like_user_ids | movies.like_user_ids, 1)::float AS score,
m.*
FROM movies
INNER JOIN movies AS m ON m.id != #{self.id}
WHERE movies.id = #{self.id}
ORDER BY 1 DESC
LIMIT #{limit}
SQL
end
由于排序字段是一个动态计算值,所以这个语句无法利用索引,效率由 movies 表大小决定,但其实比 Ruby 版的已经快很多了。
预计算相似度方案
基于相似度的推荐算法的目标就是产生一个 Item-Item 或 User-User 的相似度矩阵。用关系型数据库的表示方法为:
\d item_item_matrix
Table "public.item_item_matrix"
Column | Type | Modifiers
-----------+------------------+-------------
u_id | integer |
v_id | integer |
sim_score | double precision | default 0.0
Indexes:
"index_item_item_matrix_on_u_id_and_v_id" UNIQUE, btree (u_id, v_id)
"index_item_item_matrix_on_u_id_and_sim_score_and_v_id" btree (u_id, sim_score, v_id)
假设 movies 表的数量是 N,这个矩阵的条目数最大情况是 N*N,但实际并不需要全部 Item 之间的相似度都计算一遍:
- 相同 ID 的 Item 相似度一定是 1,不需要计算和存储
- 相似度为 0 的并不需要存储
- 通过设置一个阈值 score,过滤掉相似度很小的,比如 score 小于 0.2 的就丢弃
- 通过设置一个阈值 limit,过滤掉相关度排在后面的部分,比如一个 Item 最多存储相关度最高的 10 个 Item
经过上面的步骤,相关度矩阵的存储可以优化到 10*N 左右,即 10w 个电影的话,相似度矩阵里只需要存储 100w 条记录。
def recommend_by_matrix(limit: 10)
Movie.find_by_sql(<<~SQL)
SELECT m.*, matrix.sim_score
FROM item_item_matrix AS matrix
INNER JOIN movies AS m ON m.id = matrix.v_id
WHERE matrix.u_id = #{self.id}
ORDER BY matrix.sim_score DESC
LIMIT #{limit}
SQL
end
如果 sim_score 已经预先计算好,这个查询直接可以 index only,记录条数再多也是非常快的。不管是 TopN 推荐还是评分预测,只要相似度矩阵计算好了,之后的事情易如反掌。
下面就来预计算相似度。
WITH matrix AS (
SELECT u.id AS u_id,
v.id as v_id,
array_length(v.like_user_ids & u.like_user_ids, 1) / array_length(u.like_user_ids | v.like_user_ids, 1)::float AS sim_score
FROM movies AS u,
movies AS v
WHERE u.id > v.id AND v.like_user_ids && u.like_user_ids
), matrix_trim AS (
SELECT u_id, v_id, sim_score FROM (
SELECT u_id,
v_id,
sim_score,
row_number() OVER (partition by u_id ORDER BY sim_score desc) AS row_num
FROM matrix
WHERE sim_score > 0.01 /* 过滤掉相似度太小的值 */
) AS tmp WHERE row_num <= 10 /* 取最相近的10条记录 */
)
INSERT INTO item_item_matrix
(
SELECT u_id, v_id, sim_score FROM matrix_trim
UNION
/* u_id, v_id只需要计算一次,但存储两份,为了查询方便高效 */
SELECT v_id AS u_id, u_id AS v_id, sim_score FROM matrix_trim
)
ON CONFLICT (u_id, v_id) DO UPDATE SET sim_score = excluded.sim_score;
增量更新和离线处理
上面已经把相似度矩阵初始化完毕,对于新增数据,我们只需要把发生变化的数据重新计算一遍插入到 item item matrix 表里,这个代价非常小,可以 bulk,也可以离线。对于数量大的系统,初始化步骤也是可以分步批量插入的。由于基于 Postgres,对于超大量数据的情况,也可以平滑迁移到 greemplum 和 citus 或 redshift 这种可以并行查询计算的存储。
另外,也有一些基于 postgres 的推荐扩展,不过版本都不是很新:


