显而易见这完全是句胡话:这样的编码规定不仅难以置信的荒诞,而且还多少有点故弄玄虚。 我甚至可以想象出设计师和资方的一系列可笑对白:"不...<输入>字段的大小应该是 23...24!太长了!" 或者 "我们需要对用户解释他们的标题行应当小于 23 个字母..." 或者 "Twitter 完全搞错了...140 字的限制应该是 23 个字!"

为啥我会提出这样一个在现实中显得傻兮兮的编码规则呢?这确实有背后的缘由:构造短一些的 Ruby 字符串确实比构建长字符串更快。来看这一行 Ruby 代码:
str = "1234567890123456789012" + "x"
在 MRI 1.9.3 Ruby 解释器中它的执行速度几乎是下面这一行的两倍:
str = "12345678901234567890123" + "x"
啊?有啥不同啊?这两行看起来一模一样啊!好吧,不同之处在于第一行代码构建了一个包含 23 个字符的新字符串,而第二个行代码包含了 24 个字符。如此可见,MRI Ruby 1.9 解释器对创建 23 个字符的字符串进行了优化,至少说比构建长字符串要快。Ruby 1.8 里可不是这么回事。
我会细究一下 MRI Ruby 1.9 解释器,来了解它是怎么处理字符串的,并搞清楚这到底是怎么回事。
不是所有字符串创建都是一样的
节前 (译注:根据原文的发布时间推测是 2011 的圣诞) 我决定通读一下Ruby Hacking Guide。要是你还没听过这篇文章的话,它是一篇对 Ruby 解释器内部工作进行阐述的佳作。不幸的时这实际是日语写就的,但是一部分章节已经被翻译成为英语了。比如第二章,从这一章开始阐述了所有基本 Ruby 数据类型,包括字符串。
通读之后,我决定潜入 MRI 1.9.3 C 源码中,更深入地学习 Ruby 是如何操纵字符串的。由于我使用 RVM,对我而言 Ruby 源代码在~/.rvm/src/ruby-1.9.3-preview1 目录下。我从 include/ruby/ruby.h 文件开始了源码漫游,这个头文件中定义了额所有的 Ruby 基本数据类型,对于 Ruby 字符串对象的实现在 string.c 中。
通过阅读 C 代码我发现其实 Ruby 实际上用到了三种不同的字符串值,我把它们称为:
- 堆字符串
- 共享型字符串
- 嵌入字符串
我被迷住了!多年来我早已假定所有的 Ruby 字符串对象都是一样的。但结果这并不正确!我们凑近了看一下吧....
堆字符串
对 Ruby 而言标准做法也是最常见的方式是:字符串数据被存储到"堆"中。在 C 语言中堆是个核心概念:堆是一个大内存池,C 程序可以通过 malloc 方法分配和使用它。举例来说,下面的 C 代码从堆中分配了 100 字节的内存块 (chunk),并将其内存地址保存在一个指针中:
char *ptr = malloc(100);
之后,当 C 程序用完那段内存,她可以通过free方法将其释放,将它还给系统使用:
free(ptr)
使用像Ruby、Java、C#这些高级语言,最大的好处之一就是避免了显示的手动内存管理。当你在Ruby代码中构造一个字符串值,就像这样:
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit"
Ruby 解释器构造了一个称为"RString"的结构,类似下图所示:
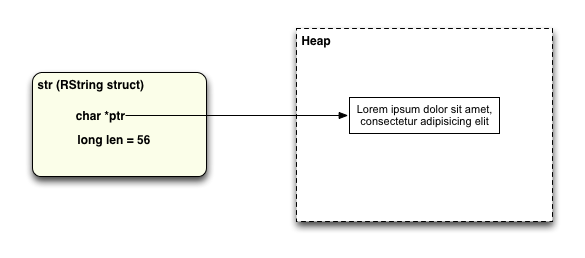
如你所见 RString 结构包含了两个值:ptr 和 len,但并不包含字符串本身的数据。Ruby 实际上将字符串的字符值本身存在从堆中分配的内存空间中,之后将 ptr 设置为那段堆内存的地址,len 为字符串的长度。
这里有一个 RString 结构体的简易版:
struct RString {
long len;
char *ptr;
};
我简略了很多,在这个 C 结构体中实际上包含了不少其他值。我会迟点讨论一些值,另一些则跳过不说。如果你对 C 不是很熟,你可以把结构(简称结构)看做一个包含一组实例变量的对象,C 语言中其实根本没有对象的概念,结构就是一段含有一些值的内存块。
我把这样的 Ruby 字符串称为"堆字符串",因为这种字符串数据实际保存在堆中。
共享型字符串
另一类 Ruby 解释器用到的字符串值在 C 源码中称为"共享型字符串"。每当写下将一个字符串复制到另一个变量上时就会创建共享型字符串,类似这样:
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit"
str2 = str
这时 Ruby 解释器意识到你正将同一个字符串值赋值给两个变量:str 和 str2。于是事实上没有必要对字符串数据创建两个副本,相反 Ruby 创建了两个 RString 值,共享一个字符串数据副本。方法是使两个 RString 结构包含相同的 ptr 值 ... 这意味着两个字符串包含相同的值。在第二个 RString 结构中还有一个值 shared 指向第一个 RString 结构。有些细节我在这里没有展示,像一些位掩码标识 (bit mask flags) 用来跟踪 RString 是否是共享的。
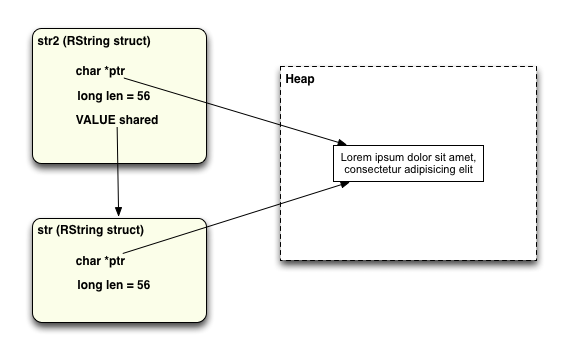
除了可以节省内存,这一做法也显著提高了 Ruby 程序的执行速度,避免再次调用 malloc 从堆分配内存。malloc 确实是一项代价不菲的操作:它得花时间在堆中追查适当大小的可用内存,还得持续跟踪它之后的释放情况。
下面是一个更接近事实版本的 C RString 结构,包含了 shared 值:
struct RString {
long len;
char *ptr;
VALUE shared;
};
如此,从一个变量复制到另一个变量的字符串,我称其为"共享型字符串"。
嵌入式字符串
第三种也是最后一种 MRI Ruby 1.9 保存字符串数据的方式是:将字符数据嵌入 RString 结构体自身,就像:
str3 = "Lorem ipsum dolor"

这个 RString 结构体包含了一个字符数组 ary 但没有 ptr,len 和 shared 值,就像上图中我们看到的。下面同样是一个简化了的 RString 结构体定义,只是这次包含了 ary 字符数组:
RString {
char ary[RSTRING_EMBED_LEN_MAX + 1];
}
要是你是对 C 代码不熟,语法 char ary[100] 创建了一个长度为 100 字符的字节 的数组。不像 Ruby,C 语言里的数组不是对象,而只是一个字节集合。在 C 语言里必须在数组创建之初就指定其长度。
内嵌式字符串是如何起效的?好吧,关键在于 ary 数组的大小,它被设为 RSTRING_EMBED_LEN_MAX+1。如果运行在 64 位机器上,Ruby 的RSTRING_EMBED_LEN_MAX被设为 24。所以像下面这样的短字符串可以被放到 RString 的ary数组中:
str = "Lorem ipsum dolor"
相对的长字符串就不行了:
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit"
Ruby 是如何构建一个新字符串值的
无论何时 Ruby 1.9 解释器通过类似这样的算法来构建一个字符串:
是新的字符串值?还一个已存在字符串的副本?如果是副本的话,Ruby 就创建一个共享型字符串。这是最快的选项,因为 Ruby 只需要新建一个 RString 结构体,不需要复制一个已经存在的字符串数据。
是长字符串吗?还是短的?如果新字符串的值小于等于 23 个字符,Ruby 会创建一个嵌入式字符串。尽管这不会像共享型字符串那么快,但还是蛮快的,因为 23 个字符被简单地复制到了 RString 结构体内,并且不需要调用 malloc。
最后,来解决长字符串,24 个字符以上的那些,Ruby 创建堆字符串:调用 malloc 从堆中获取新的内存空间,将字符串值复制进去。这是最慢的一种。
真实的 RSting 结构体
Ruby 1.9 中 RString 的真实定义如下:
struct RString {
struct RBasic basic;
union {
struct {
long len;
char *ptr;
union {
long capa;
VALUE shared;
} aux;
} heap;
char ary[RSTRING_EMBED_LEN_MAX + 1];
} as;
};
我在此不打算阐述所有细节,但是从这个定义中有几个值得了解的重点:
RBasic 结构体跟踪关于这个字符串的许多重要信息位,像区分是共享型还是嵌入式的标识,还有一个指针指向 Ruby 中 String 对象的结构体。
capa 值维护每个堆字符串的容量 (capacity)...原来 Ruby 通常为每个堆字符串分配比其需求 (字符串数据长度) 更大的内存空间,以避免在字符串大小发生变化时额外的 malloc 调用。
使用联合体 Ruby 既可以使用 len ptr 和 capa/shared,也可以使用数组来保存字符串。
RSTRING_EMBED_LEN_MAX 被用来与 len/ptr/capa 的比较。这也是题目中 23 个字符串的由来。下面的代码摘自 ruby.h 定义了这个值。
#define RSTRING_EMBED_LEN_MAX ((int)((sizeof(VALUE)*3)/sizeof(char)-1))
在 64 位的机器上 sizeof(VALUE) 是 8,于是 23 就成为了限制。32 位机器上会更小一点。
Ruby 分配字符串基准测试
来度量一下在 Ruby 1.9.3 里短字符串比长字符串快多少吧,下面一行简单的代码通过向字符串尾部追加的方式构建了一个新字符串:
new_string = str + 'x'
new_string 的值将是堆字符串或是嵌入式字符串。这取决于 str 有多长。我使用字符串连接操作符(+ 'x')是为了迫使 Ruby 动态分配一个新的字符串。如果只是用 new_string = str,我们会得到一个共享式字符串。
现在我们要循环调用这个方法,并做一下基准测试
require 'benchmark'
ITERATIONS = 1000000
def run(str, bench)
bench.report("#{str.length + 1} chars") do
ITERATIONS.times do
new_string = str + 'x'
end
end
end
这里我使用 benchmark 库来度量此方法一百万次的执行时间。现在,用不同长度的字符串来跑一下。
Benchmark.bm do |bench|
run("12345678901234567890", bench)
run("123456789012345678901", bench)
run("1234567890123456789012", bench)
run("12345678901234567890123", bench)
run("123456789012345678901234", bench)
run("1234567890123456789012345", bench)
run("12345678901234567890123456", bench)
end
我们得到了一个有趣的结果:
user system total real
21 chars 0.250000 0.000000 0.250000 ( 0.247459)
22 chars 0.250000 0.000000 0.250000 ( 0.246954)
23 chars 0.250000 0.000000 0.250000 ( 0.248440)
24 chars 0.480000 0.000000 0.480000 ( 0.478391)
25 chars 0.480000 0.000000 0.480000 ( 0.479662)
26 chars 0.480000 0.000000 0.480000 ( 0.481211)
27 chars 0.490000 0.000000 0.490000 ( 0.490404)
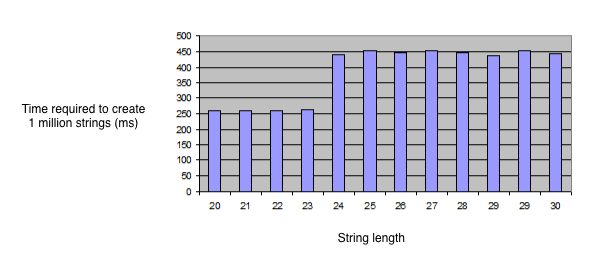
注意当字符串小于等于 23 个字符的时候,建一百万字符串差不多花了 250 毫秒。但是当我们的字符串长度大于等于 24 时,花了大约 480 毫秒,几乎两倍长。
下面的柱形图来展示了更多数据,柱形展示课给定长度的一百万个字符串的创建用时。
总结
别担心!我不认为你应该重构所有的代码确保字符串长度小于 24。这显然很荒谬。速度看起来是提升了,但是实际上即使我构建了一百个字符串,时间差距也微乎其微。试问有多少 Ruby 应用需要创建如此之多的字符串值?即使需要创建很多字符串对象,因为只能使用短字符串带来的痛苦和疑惑会抵消所有性能提升所带来的福利。
于我而言,真正理解 Ruby 解释器的工作方式充满乐趣!我乐于透过显微镜来观察这类细枝末节。我确实也怀疑:通过对 Matz(及其同事)实现语言方法的理解来提升自己的 Ruby 水平,是不是一条明智和通达的。拭目以待吧,会有更多关于 Ruby 内部实现的帖子的!