Gem 写了一个中文分词的 gem——nlpir
nlpir gem 封装自中科院中文分词 ICTCLAS2014
ICTCLAS 是由中国科学院计算技术研究所研发。功能包括中文分词;词性标注;命名实体识别;新词识别;同时支持用户词典。目前性能最好的中文分词工具。
nlpir 使用 ruby2.0 fiddle 模块封装,最新版本 1.0.0 封装自 ICTCLAS2014 最新版本,完美支持 linux x86 x64,之前反应的用户词典 bug 已经修复。新版的 gem 提供了 ruby 风格的函数。
gem install nlpir
usage:
require 'nlpir'
include Nlpir
s="坚定不移沿着中国特色社会主义道路前进 为全面建成小康社会而奋斗"
#在当前文件夹路径下初始化
nlpir_init(File.expand_path("../", __FILE__),UTF8_CODE)
#处理字符串
text_proc(s)
#处理文件
file_proc("example.txt","result.txt")
#导入用户词典
import_userdict("./userdict.txt")
text_proc(s)
nlpir_exit()
欢迎各位继续丰富 ruby 在自然语言处理领域的包
用法 和 test 中的用法 [email protected] nlpir@github
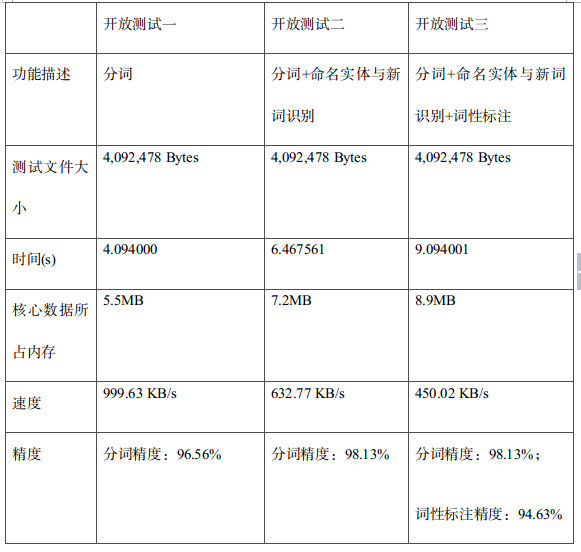
有人问性能,官方文档里其实有测试数据,ICTCLAS 测试:

看了一下 README 上面的使用方法,好复杂啊,不能简单一点么,另外
NLPIR_AddUserWord
NLPIR_ParagraphProcess
NLPIR_ImportUserDict
...
这里方法命名一点也不 Ruby,用起来很奇怪
进去就看到这个例子, require 'nlpir' include Nlpir
s = "坚定不移沿着中国特色社会主义道路前进 为全面建成小康社会而奋斗"
#32 楼 @wujian_hit 一般会继承org.apache.lucene.analysis.Tokenizer这个抽象类写一个 Tokenizer,然后写一个类继承org.elasticsearch.index.analysis.AbstractTokenizerFactory,做个工厂类,这个可以通过 elasticsearch 的 index 配置,传入一些特定参数,然后传给你的 Tokenizer,再写一个类继承AnalysisModule.AnalysisBinderProcessor用来在 elasticsearch 启动时,注册你的 TokenizerFactory。
这是基本流程。。。伟大的爪哇
/home/changwu/.rvm/gems/ruby-2.0.0-p0/gems/nlpir-0.0.3-x86-linux/lib/nlpir.rb:177:in to_s': NULL pointer given (ArgumentError)
from /home/changwu/.rvm/gems/ruby-2.0.0-p0/gems/nlpir-0.0.3-x86-linux/lib/nlpir.rb:177:inNLPIR_ParagraphProcess'
from split_words.rb:11:in `
代码如下:
#encoding : utf-8
require 'nlpir'
include Nlpir
s = "坚定不移沿着中国特色社会主义道路前进 为全面建成小康社会而奋斗"
#first of all : Call the NLPIR API NLPIR_Init
NLPIR_Init(nil, UTF8_CODE , File.expand_path("../", __FILE__))
#example1: Process a paragraph, and return the result text with POS or not
puts puts NLPIR_ParagraphProcess("1989年春夏之交的政治风波1989年政治风波24小时降
雪量24小时降雨量863计划ABC防护训练APEC会议BB机BP机C2系统C3I系统C3系统C4ISR系统C4I系统CCITT建议")
@wujian_hit when I tried to install with my Ruby 2,0 got below error: any suggestion on this? Could not find nlpir-0.0.3 in any of the sources
这个 gem 还不能支持 x64 系统吗?mac 下安装出现:
gem install nlpir
ERROR: Could not find a valid gem 'nlpir' (>= 0), here is why:
Found nlpir (1.0.0), but was for platforms x86_64-linux ,x86-linux ,x86-mingw32
欲哭无泪,最近毕设可能需要处理分词。