-
UCloud 已经不是 UCloud,而你大爷还是你大爷 [2017/12/25 更新] at 2017年12月25日
- 谈谈 TiDB
正如我 23 号讨论时所说,我们团队也在学习 TiDB 代码,在我们看来,TiDB 代码是一个优秀的实现。我于今年 5 月份开始,跟 TiDB 的核心骨干,如黄东旭,mengjie、刘寅、邓佺等,都有很好的沟通。UCloud 也和 PingCap 一起,推出了 UCloud TiDB 这款产品。UDDB 团队,和 TiDB 团队,合作也是非常愉快的。比如,我们为 UCloud TiDB 推荐了 2 位客户,而 UCloud TiDB 为我们推荐了 1 位客户。在我们看来,一切以客户价值为皈依。假如客户的业务,更贴合 TiDB,我们则会推荐 TiDB 产品,加入客户业务更贴合 UDDB,则我们向客户推荐 UDDB(其实客户也很聪明,在充分了解两款产品差异性后,自己也知道哪款产品最合适)。
这是我们实际的情况,需要的话我们可以提供信息进行证明。
-
UCloud 已经不是 UCloud,而你大爷还是你大爷 [2017/12/25 更新] at 2017年12月25日
1.OLTP 的问题(续)
TiDB 的设计目标是 100% 的 OLTP 场景和 80% 的 OLAP 场景。
我认为这是 TiDB 一个非常好的产品宣传策略。但是这不影响我的观点:
我的理解是在讨论一个概念时,需要结合实际的应用场景才有意义。HTAP 从概念上理解,是 OLTP+OLAP,但技术需要结合具体的产品讨论才有意义。正如我当时举得一个阿里云 Hybrid MySQL 的例子,阿里云 Hybrid MySQL 也称之为 HTAP,但假如你看过阿里 Hybrid MySQL 的产品文档,你就会发现,他们文档里面写得很清楚,针对的场景就是物联网、大数据分析等领域,并不是涵盖 OLTP+OLAP(所以我当时反问过你:如果 Hybrid MySQL 能涵盖 OLTP+OLAP,那就是阿里下一代产品了,又为何定位在物联网和大数据分析领域?)。假如你对分布式数据库产品多去了解一点,这个结论是不难得出的。
-
UCloud 已经不是 UCloud,而你大爷还是你大爷 [2017/12/25 更新] at 2017年12月25日
- OLTP 的问题
我先不说别的,阿里云的 Hybrid for HTAP 在 Sharding 上还做了分区键。要是阿里云的 Hybrid for HTAP 连 OLTP 都做不到,你个中间件做 reduce 的玩意也敢说自己能做到 OLTP?阿里云怕杀鸡用牛刀说「针对的场景就是物联网、大数据分析等领域」,到你嘴里就变成除了这个就干不了别的了,我也是佩服得不行。
”你个中间件做 reduce 的玩意“:你可能不知道,阿里云 Hybrid MySQL,就是基于一个中间件发展起来的。你可以去找今年云栖大会上,Hybrid MySQL 负责人的 ppt 和视频。他全面介绍了 Hybrid MySQL 的演进路程。而 UDDB 也是基于一个中间件,在演进。
-
UCloud 已经不是 UCloud,而你大爷还是你大爷 [2017/12/25 更新] at 2017年12月25日
- 形式化验证的问题
首选必须要指出的是,你回帖的内容:
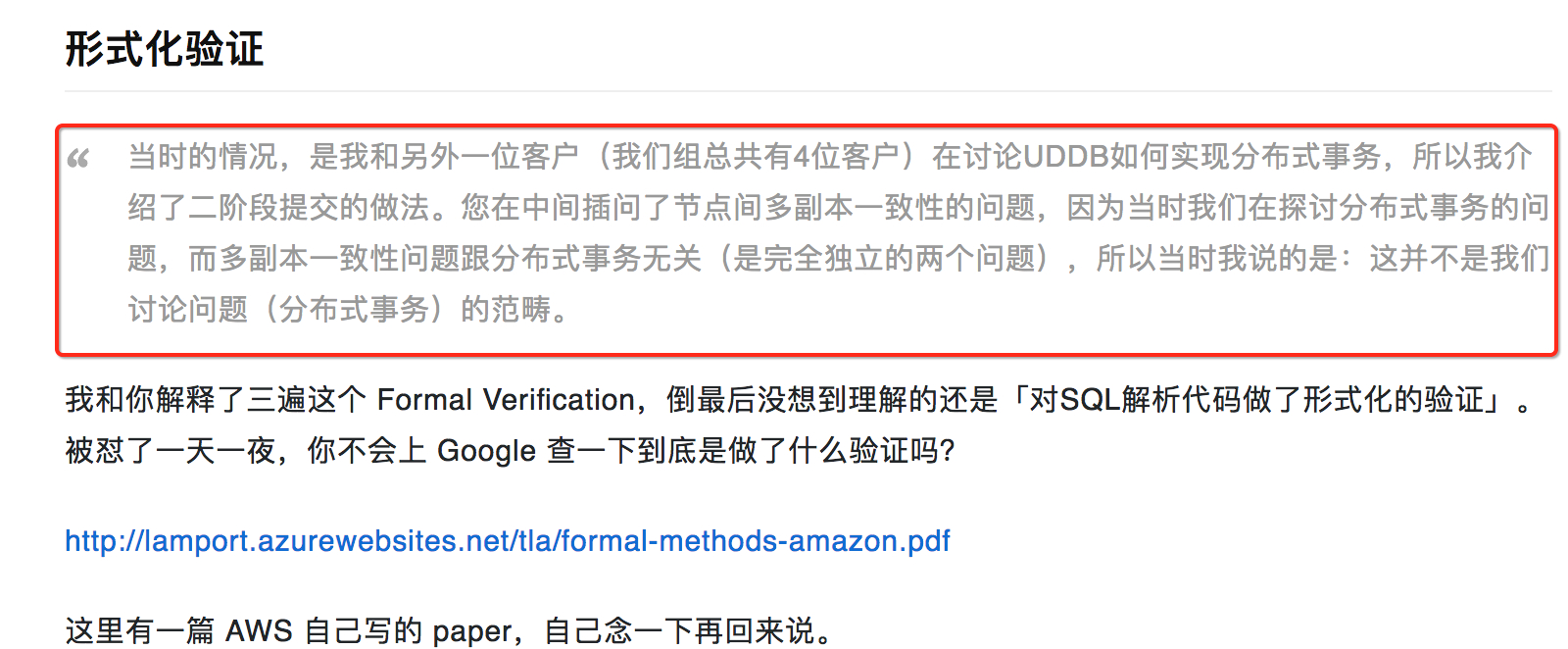
这里面有一个明显的细节错误。红框中的内容(分布式事务有关的),跟形式化验证没有关系,但是你在这里贴出来了。
个人而言,我认为这是一个不注重细节的表现。
回到 23 号关于形式化验证的讨论。当时我在给另外一为客户,讲解 UDDB 架构的问题。旁边的你突然插问测试的问题。我当时问:是不是指 SQL 覆盖性测试。然后你说是,并说 TiDB 做了形式化(确切地说,你当时用的是 Formal Verification,我翻译成形式化验证是不会有错的)。我当时表达了这不可能。 因为如果能够对 SQL 解析和执行的代码做形式化验证,那么大部分公司都应该不需要测试人员了。
-
UCloud 已经不是 UCloud,而你大爷还是你大爷 [2017/12/25 更新] at 2017年12月25日
- 首先,你把分片内多副本一致性,和 ACID 一致性混为一谈。ACID 是 Jim Gray 提出来的。我们先来看一下 Jim Gray 在其著作《事务处理:概念和技术》是怎么定义 ACID 中的一致性的:

ACID 中的 C,是指在操作语义上,所有操作的结果对数据库数据造成的影响,必须是一致的。而分片内多副本一致性,是指在分布式系统里(出于容灾或读性能提升考虑,需要多副本),需要多副本部署。这就产生的多副本一致性的问题。
两种办法各有其解决方案。多副本一致性的解决,一般采用 Paxos、Raft 算法,而分布式事务中 C 的保证,目前主流的方法也是采用二阶段提交。如果要细究的话,两阶段提交的方法,对分布式事务中 C 的保证,也是存在局限的。但我相信上面的信息,已经足够解释清楚,为什么分片内多副本一致性,和 ACID 中的一致性,是两个完全不同的概念了。
-
UCloud 已经不是 UCloud,而你大爷还是你大爷 [2017/12/25 更新] at 2017年12月24日
您好,我就是当天分享的 ucloud 研发工程师,有十年多的技术工作经历,目前负责 uddb 的研发。帖子所描述的发生于演讲结束后的 4-5 人小范围的技术讨论,您所谈到的技术点我想有必要说明清楚。
1、首先,是几点我觉得细节上描述的不够清楚的地方
1.1 您说的我没听到过客户用 migration 这种东西,没有把 ruby china 当回事: 当时在和您讨论时您提到的 ruby schema-migration,这个知识点我确实不了解。在您给出解释后,我当时所说是:这个插件的作用是动态做 DDL,但一般而言,DDL 都是由 DBA 在初始化阶段和维护阶段手工做的,所以业务里面直接 DDL 的场景较少。 正所谓闻道有先后,术业有专攻。我们和客户的探讨都是双向的。相互之间会传递各自擅长的技术点给到对方,和客户的讨论过程也是学习的过程。这次了解了 ruby schema-migration,对我来说是一次学习。
1.2 您说的保证分布式一致性的质疑
当时的情况,是我和另外一位客户(我们组总共有 4 位客户)在讨论 UDDB 如何实现分布式事务,所以我介绍了二阶段提交的做法。您在中间插问了节点间多副本一致性的问题,因为当时我们在探讨分布式事务的问题,而多副本一致性问题跟分布式事务无关(是完全独立的两个问题),所以当时我说的是:这并不是我们讨论问题(分布式事务)的范畴。
1.3 针对 TiDB 的几点质疑
您提到 TiDB 对 SQL 解析代码做了形式化的验证,然后发现了几个 bug,同时提到 aws 也有这样的方法。 我认为的是,对 SQL 解析的代码做形式化验证,这是一个不可能有解的问题。UDDB 只是收集了很多 SQL 测试用例来做测试,而 TiDB 这块也是这么做的。
- 另外澄清跟技术有关的几个点:
2.1 关于这个产品的完成度非常低的问题,包括 Sharding 需要手动设计
Sharding 手动设计,具体而言是需要在 Create Table 语句里面,指定分区信息。这是很多分布式数据库的特点。比如,OceanBase、腾讯云 TDSQL 等。而 TiDB,最近也在支持分区。我们认为,Sharding 手动设计是一种给客户更加灵活度的策略,而不是技术上的妥协。
2.2 关于 OLTP 和 HTAP 之争:
我的理解是在讨论一个概念时,需要结合实际的应用场景才有意义。HTAP 从概念上理解,是 OLTP+OLAP,但技术需要结合具体的产品讨论才有意义。正如我当时举得一个阿里云 Hybrid MySQL 的例子,阿里云 Hybrid MySQL 也称之为 HTAP,但假如你看过阿里 Hybrid MySQL 的产品文档,你就会发现,他们文档里面写得很清楚,针对的场景就是物联网、大数据分析等领域,并不是涵盖 OLTP+OLAP(所以我当时反问过你:如果 Hybrid MySQL 能涵盖 OLTP+OLAP,那就是阿里下一代产品了,又为何定位在物联网和大数据分析领域?)。假如你对分布式数据库产品多去了解一点,这个结论是不难得出的。
总结:
本来我觉得这次会议是 4-5 人的一次技术上的小规模的探讨,大家可以放开谈技术的看法和观点,但是引起这些风波是我意料不到的。不过我们还是挺欢迎这种技术上的探讨,客户对我们的批评也是对我们的鞭策和成长,也希望我们后边能针对分布数据领域的技术点有更多更深入的探讨。