AI 找货助手技术实现指南
最近阿里云千问的"点奶茶"技能很火,碾压了微信红包的 AI 玩法。这波 AI 热潮下,我们在 APP 里也做了一个 AI 找货功能。
用户搜"温润的手镯",传统搜索只认"温润"和"手镯"两个字。但用户真正想要的是和田玉——因为"温润"是和田玉的特征。
这篇讲讲怎么用向量搜索 + AI 对话,让系统理解用户真正想要什么。淘宝、京东、美团、携程都有类似功能,我们这个还比较粗浅,讲个大概,体验看起来还有待优化,还请包涵。
需求预览
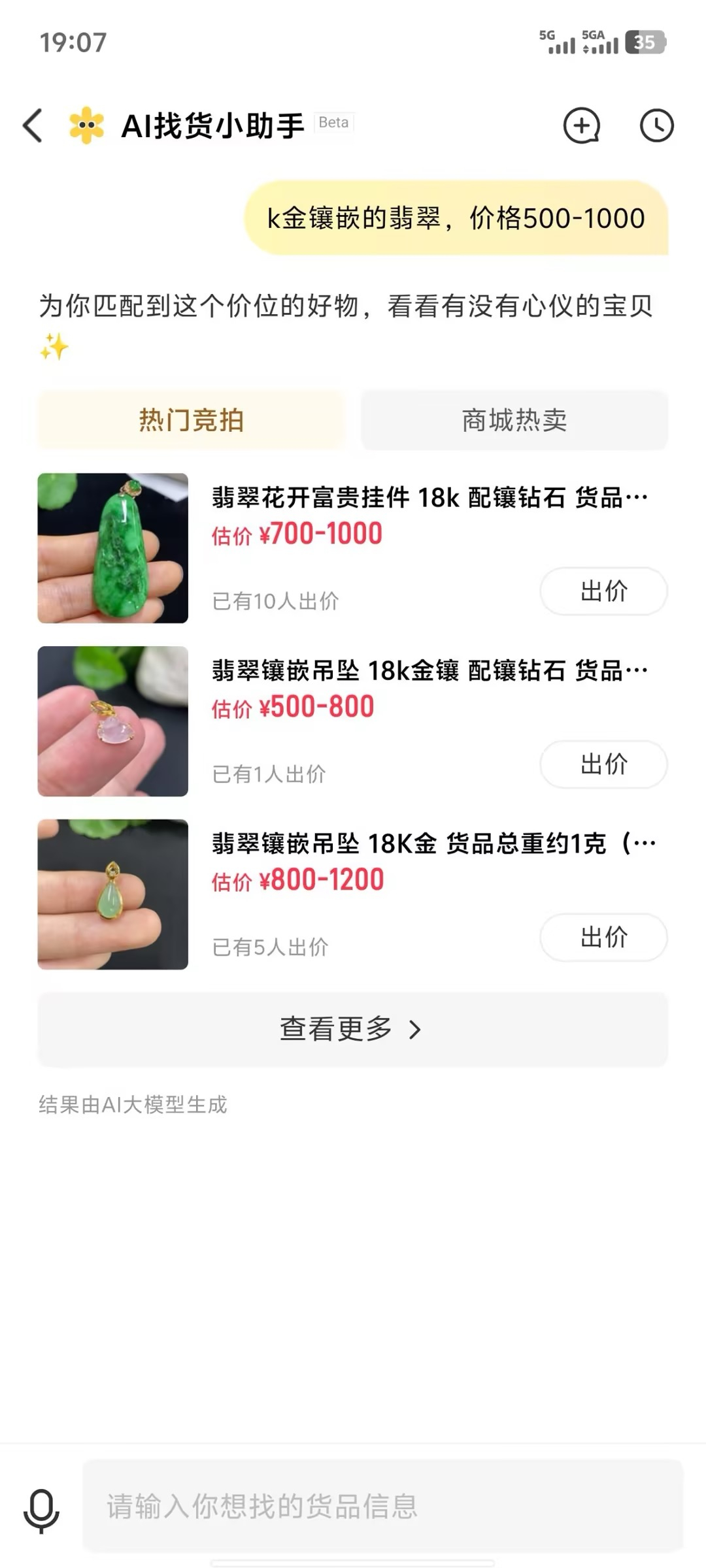
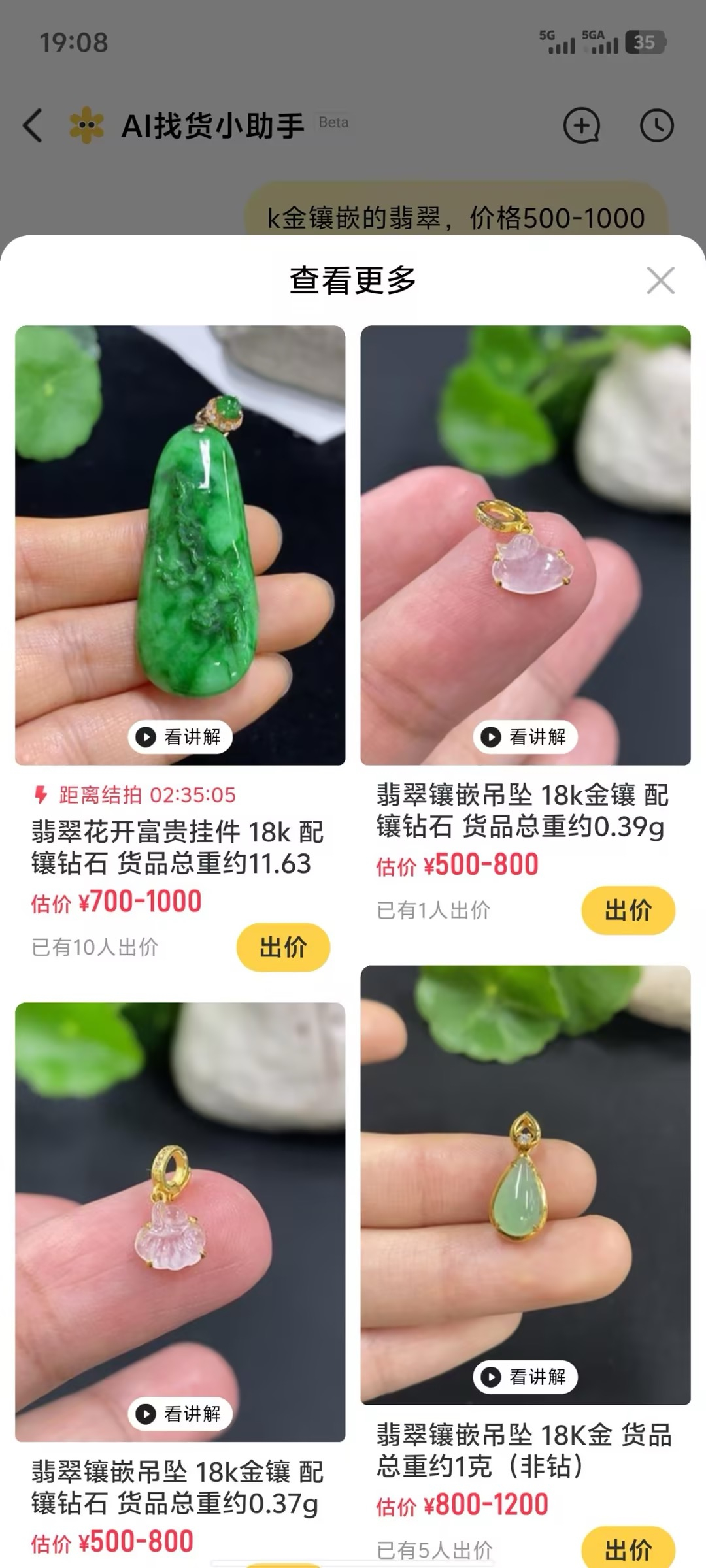
目录
核心概念
| 概念 | 说明 |
|---|---|
| Dify | 开源 LLM 应用开发平台,我们用它做工作流编排。Dify 部署成独立服务,Rails 后端通过 HTTP API 调用。 |
| SSE | Server-Sent Events,服务器主动推送数据给前端,比 WebSocket 简单,适合这种单向实时推送的场景。 |
| 向量搜索 | 把文本转成 1024 维向量,算向量相似度来找商品。比如"温润的手镯"能匹配到"和田玉手镯"。 |
| KNN | K 最近邻算法,在向量空间里找最相似的 K 个商品。K 越大结果越多,但也越慢。 |
| Embedding | 把文本转成向量的过程,语义相近的文本向量也相近。 |
| HNSW | 一种高效的向量索引算法,ES 8.x 原生支持,用来加速 KNN 搜索。 |
一、技术架构总览
1.1 整体架构图
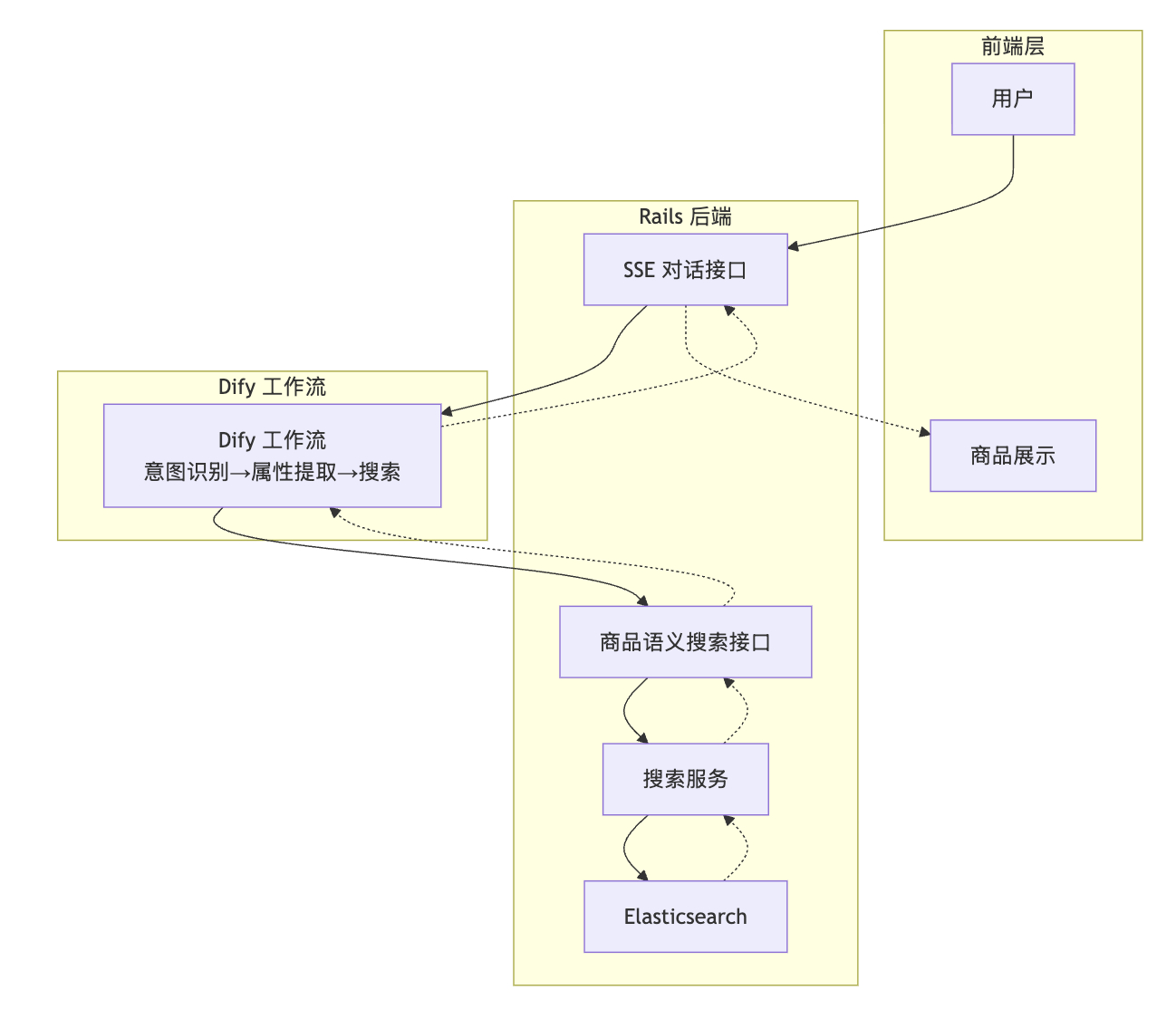
整体流程
用户在前端输入需求 → SSE 建立长连接 → Rails 把请求转给 Dify → Dify 识别意图、提取参数 → Dify 调用 Rails 的搜索接口 → Rails 生成查询向量 → ES 做 KNN 向量搜索 → 结果沿路返回 → 前端展示。
几个关键点
- 前端和 Rails 之间用 SSE,服务器主动推送,不用轮询。
- Dify 是外部服务,Rails 只负责转发和调用搜索接口。
- 搜索用的是向量搜索,不是传统的关键词匹配。
核心配置
| 配置项 | 环境变量 | 作用 |
|---|---|---|
| Dify API 地址 | DIFY_API_BASE_URL |
Dify 服务的 URL |
| Dify API Key | DIFY_CHATFLOW_API_KEY |
调用工作流的认证密钥 |
核心接口
| 接口 | 路径 | 谁调用 |
|---|---|---|
| SSE 对话接口 | POST /api/v1/chat/stream |
前端 |
| 商品语义搜索接口 | POST /api/v1/products/ai_search |
Dify 工作流 |
1.2 商品列表接口
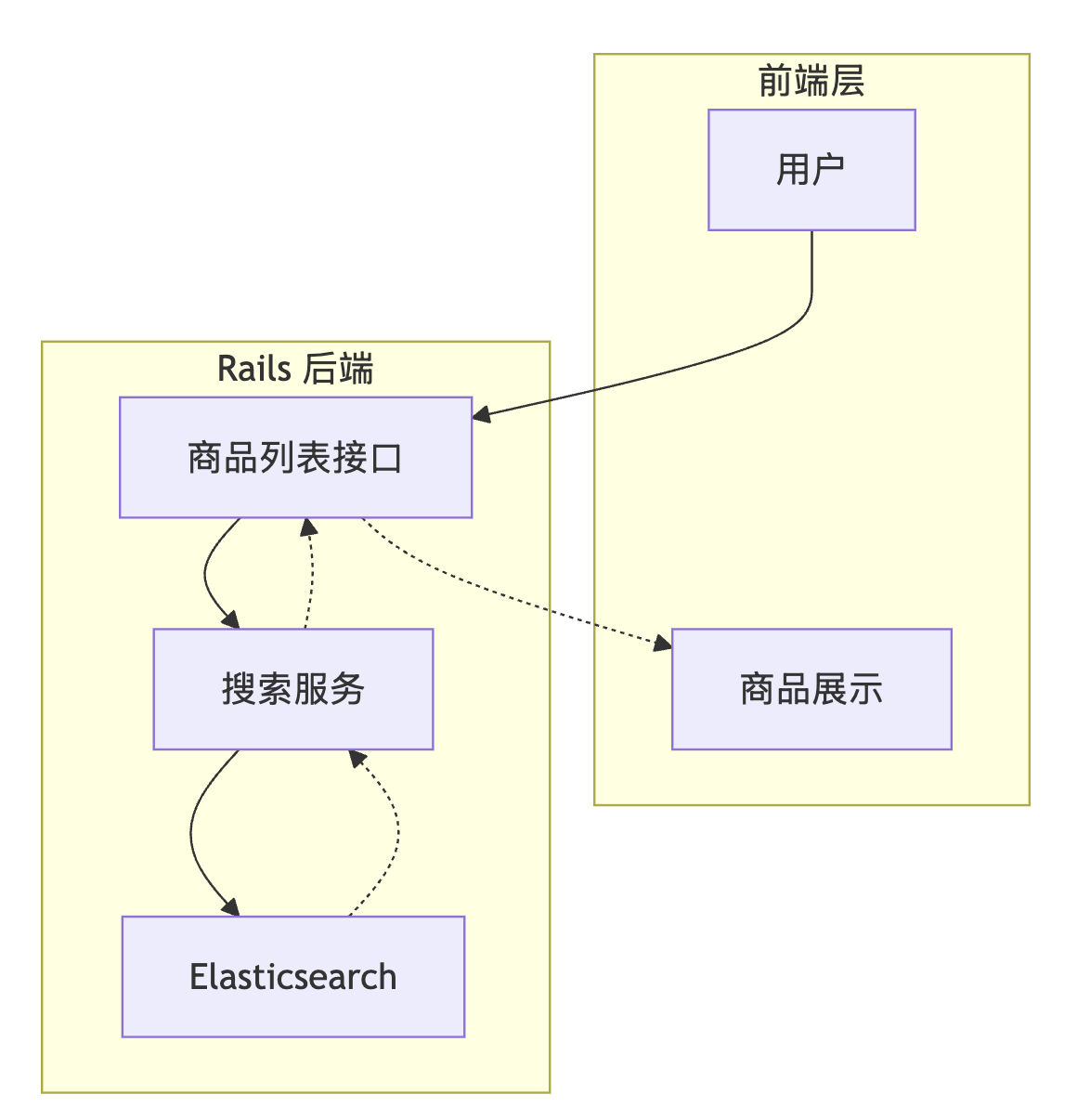
GET /api/v1/products 这个接口支持两种搜索方式:普通搜索(传 q、category_id、price_min/max 等参数),和 ai_search_id 搜索(传之前搜索的 ID,复用搜索参数)。
使用场景是这样的:用户在对话里看到商品列表,想看更多,点"查看更多"按钮,前端把之前的 ai_search_id 传过来,后端直接从数据库捞出之前的搜索参数,做分页查询。
1.3 数据流转
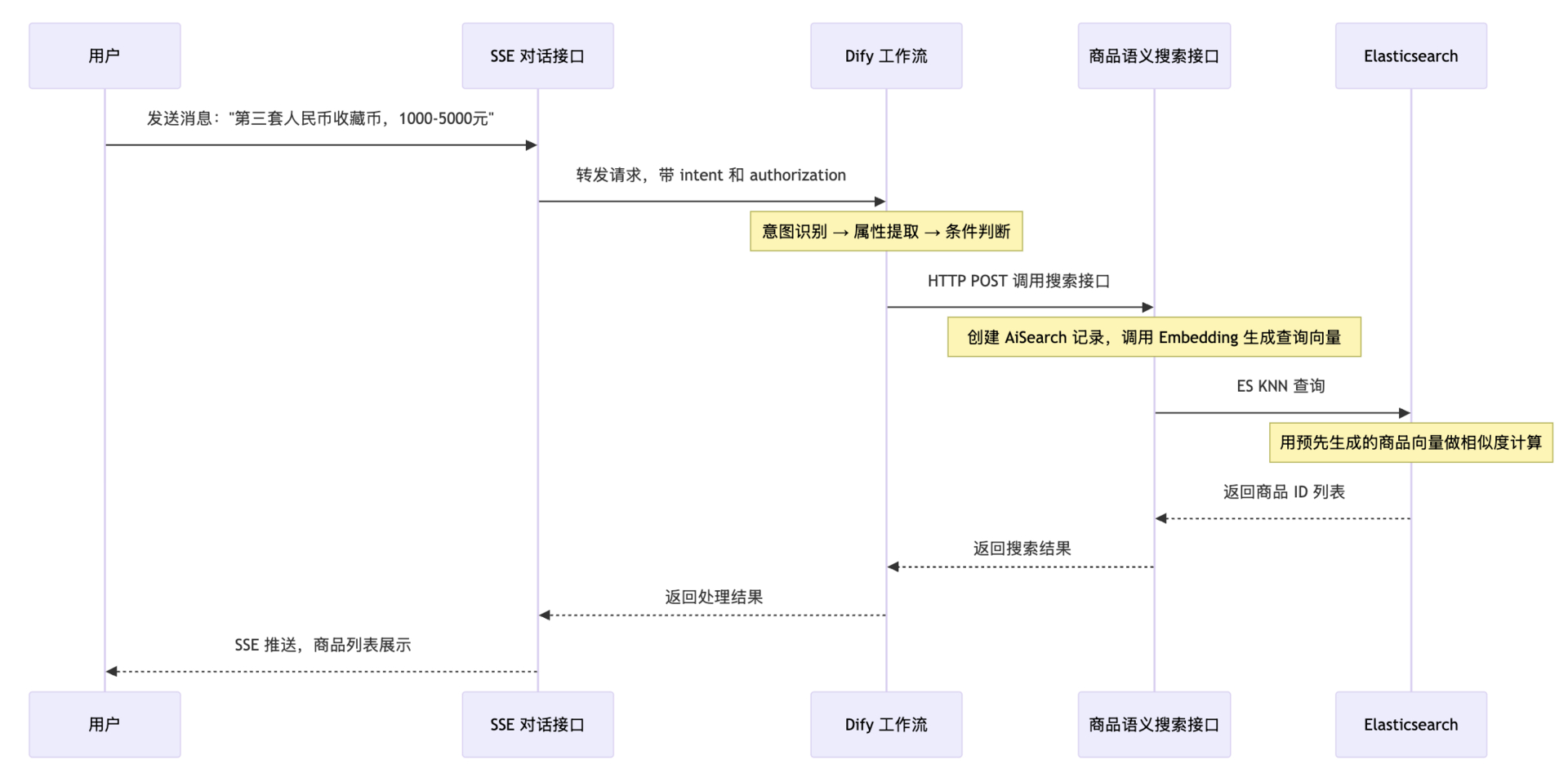
两个关键点
- 商品向量是上架时生成的,存在 ES 里;查询向量是每次搜索实时生成的。
- 向量生成失败了怎么办?降级处理,返回空结果或者转关键词搜索。
1.4 技术栈
| 组件 | 选型 | 说明 |
|---|---|---|
| 工作流引擎 | Dify | 最新版,做 AI 流程编排 |
| LLM | 通义千问 qwen-plus-latest | 意图理解、参数提取 |
| 搜索引擎 | Elasticsearch 8.x | 商品索引 + KNN 向量搜索 |
| 后端框架 | Ruby on Rails 8.x | 业务逻辑 |
二、SSE 事件设计
2.1 事件流程图
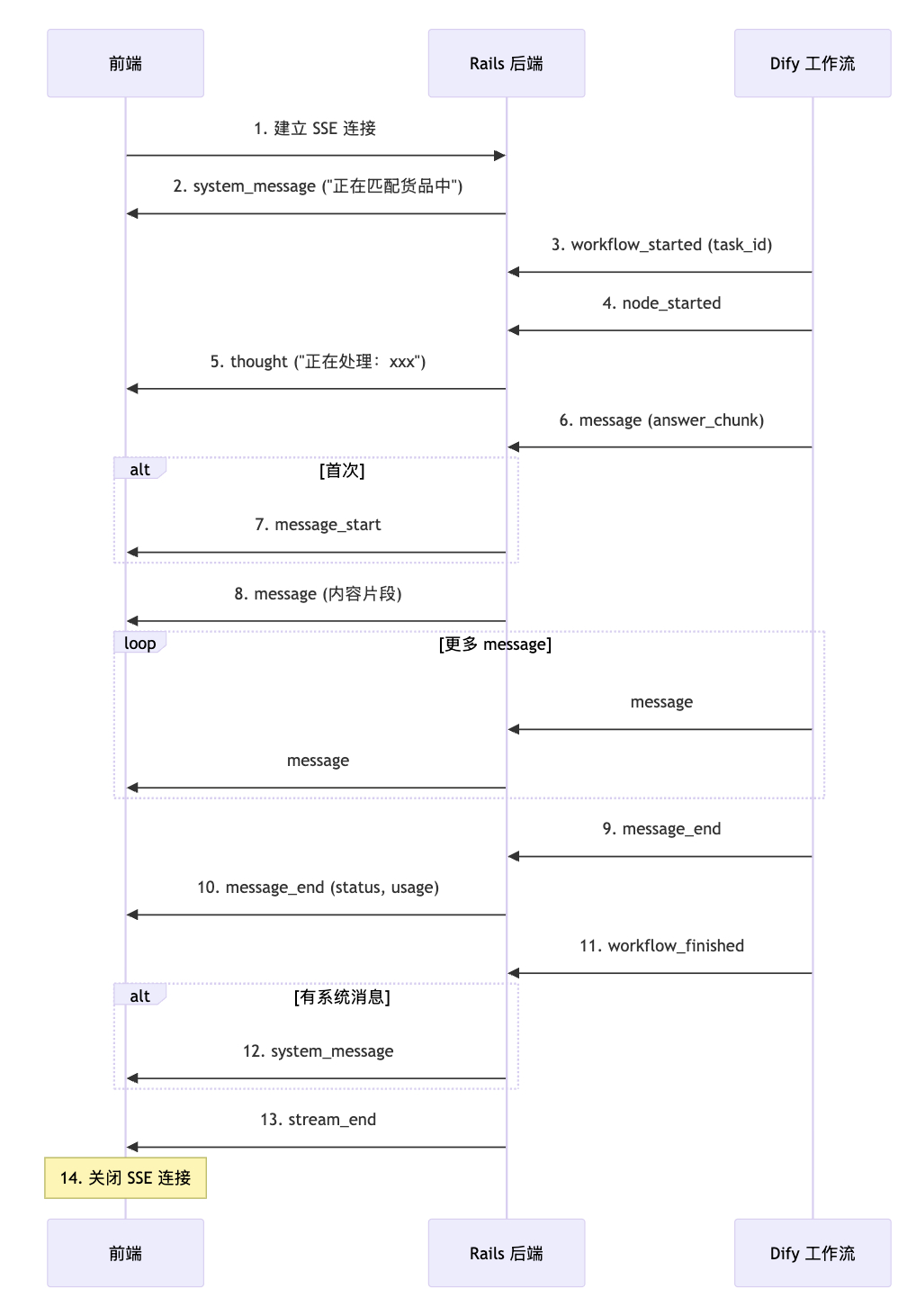
2.2 事件类型
| 事件类型 | 触发时机 | 作用 |
|---|---|---|
system_message |
连接建立后、stream_end 前 | 系统提示,比如"正在匹配货品中",或者错误提示 |
message_start |
第一次收到 Dify 的 message | 告诉前端准备接收消息 |
message |
收到 Dify 的 message | 真正推送内容,可能拆成多个片段 |
thought |
Dify 节点开始处理 | 显示"正在处理:xxx",让用户知道进度 |
message_end |
收到 Dify 的 message_end | 一条消息发送完成 |
stream_end |
整个流程结束 | 前端可以关闭连接了 |
msg_type 的取值
message_start 和 message 的 msg_type:
- Dify 返回
PRODUCT_CARD→product_card(商品卡片) - Dify 返回
CLARIFY_CARD→clarify_card(追问卡片) - Dify 返回
TEXT→text(普通文本) - 其他情况默认
text,结构化内容可能是blocks
system_message 的 msg_type:
-
show_thinking:显示思考过程 -
hide_thinking:隐藏思考过程 -
text:普通系统文本 -
retry:可重试的错误
2.3 事件数据格式
message_start
{
"event": "message_start",
"data": {
"msg_id": "uuid",
"msg_type": "text",
"role": "assistant",
"task_id": "uuid"
}
}
message
{
"event": "message",
"data": {
"msg_id": "uuid",
"content": "这是消息内容",
"task_id": "uuid"
}
}
message_end
{
"event": "message_end",
"data": {
"msg_id": "uuid",
"status": "success",
"usage": {
"prompt_tokens": 100,
"completion_tokens": 50,
"total_tokens": 150
}
}
}
stream_end
{
"event": "stream_end",
"data": {
"conversation_id": "uuid",
"status": "success"
}
}
system_message
{
"event": "system_message",
"data": {
"id": "uuid",
"msg_type": "text",
"role": "system",
"content": "正在匹配货品中",
"user_message_id": 123
}
}
thought
{
"event": "thought",
"data": {
"msg_id": "uuid",
"content": "正在处理:属性提取",
"task_id": "uuid"
}
}
2.4 事件顺序和处理规范
标准顺序
- 连接建立后,先发
system_message(show_thinking)告诉用户"正在匹配" - 收到 Dify 的 message,第一次发
message_start,然后发message(可能多次) - 收到
node_started时可以发thought - 收到
message_end时发message_end - 有系统消息(错误或提示)发
system_message - 最后发
stream_end
错误处理
- 错误不走单独的 error 事件,统一用
system_message -
msg_type是retry表示可重试的错误 - 不管成功失败,最后都会发
stream_end
前端注意事项
-
message是流式的,前端要累积内容直到收到message_end - 根据
msg_type决定怎么渲染 - 收到
stream_end就关闭连接
三、Dify 对话流设计详解
3.1 工作流核心结构
我们用 Dify 的节点式编排来做对话流,核心节点如下:
| 节点类型 | 作用 |
|---|---|
| Start | 接收用户输入和认证信息 |
| Question Classifier | 意图识别,分成 4 种意图 |
| LLM | 属性提取,把用户输入转成结构化参数 |
| If-Else | 判断要不要追问用户 |
| LLM | 生成追问话术和选项按钮 |
| HTTP Request | 调用后端搜索接口 |
| Code | 结果合并,各分支互斥,只返回其中一个结果 |
工作流里的变量:环境变量 HTTP_DOMAIN 存 API 域名。
3.2 Start 节点
起点,接收前端传来的变量:
| 变量 | 类型 | 说明 |
|---|---|---|
| intent | string | 用户意图标识 |
| authorization | string | Bearer Token |
| version_date | string | 版本日期(可选) |
3.3 意图识别
用 Dify 的 Question Classifier 节点,把用户请求分成 4 类:
| 分类 ID | 名称 | 例子 |
|---|---|---|
| 1 | 找货意图 | "找翡翠手镯"、"想买和田玉" |
| 2 | 知识问答 | "怎么鉴别翡翠 A 货"、"如何保养和田玉" |
| 3 | App 问答 | "怎么注册账号"、"如何发布商品" |
| 4 | 闲聊 | "你好"、"谢谢"、"再见"、"今天天气怎么样" |
模型配置:通义千问 qwen-plus-latest,Temperature 设 0.3 保证分类稳定,对话记忆保留最近 10 轮。
3.4 属性提取
从用户输入里提取搜索参数,用 LLM 节点,模型也是通义千问,Temperature 0.3。
q 字段(核心搜索描述)
- 要包含明确的商品品类词
- 50-100 字的自然语言描述
- 有些默认规则:用户说"玉石"没具体说是和田玉还是翡翠,默认当和田玉处理;说"高货"默认当翡翠处理。
价格范围
price_min 只有满足"品类 + 高价值信号 + 高价值形态 + 无瑕疵"时才推断。比如用户说"高品质玻璃种翡翠手镯,无纹无裂",才可能推断最低价。
price_max 按用户字面描述来,用户说"5000 元左右"就设 5000。
分类映射
1=>翡翠,2=>玉石,3=>钻石,4=>彩宝,39=>书画,40=>黄金,107=>黄金饰品,109=>文玩古玩,110=>钱币邮票
输出字段
| 字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
| q | string | 是 | 核心搜索描述 |
| price_min/max | number/null | 否 | 价格范围(元) |
| category_id | number/null | 否 | 商品分类 ID |
| inner_circle_size_min/max | number/null | 否 | 圈口尺寸(mm) |
| heat_min/max | number/null | 否 | 参与热度范围 |
| is_uncertain | boolean | 否 | 是否模糊需追问 |
| has_discount | boolean | 否 | 是否要优惠商品 |
| negative_filters | array[string] | 否 | 排除关键词 |
3.5 条件判断
检查 is_uncertain 字段,true 就进入追问分支,false 直接搜索。
触发追问的例子
- "想买个手镯" → 缺少价格、材质,追问
- "5000 元的" → 缺少商品类型,追问
- "翡翠手镯,5000-8000 元" → 信息完整,直接搜
3.6 生成追问
当需要追问时,用 LLM 生成话术和选项。Temperature 设 0.7 高一点,让回答更有创造性。
生成规则:message 字段要共情 + 归因 + 引导,suggested_questions 至少 3 个肯定式选项。
{
"message": "追问话术",
"suggested_questions": [
{ "title": "问题标题", "intent": "find_item" }
]
}
3.7 HTTP 请求节点
真正调用 Rails 搜索接口的地方:
- POST 请求
- URL:
{{#env.HTTP_DOMAIN#}}/api/v1/products/ai_search - 请求头带
X-Authorization(从 Start 节点取)
超时和重试:连接/读取/写入都设 10 秒,失败自动重试 1 次。
3.8 结果合并
根据条件判断走不同的分支,各分支互斥,只返回其中一个:追问分支返回追问话术,搜索分支返回商品列表结果,无结果时返回默认话术。
四、向量搜索技术详解
4.1 为什么用向量搜索
传统搜索的局限:
| 搜索方式 | 问题 |
|---|---|
| 关键词搜索 | 无法理解语义,"温润的手镯"匹配不到和田玉 |
| 短语匹配 | 要求太精确,用户不会打完整短语 |
| 布尔搜索 | AND/OR/NOT 组合太复杂,用户不会用 |
向量搜索能理解语义:
| 搜什么 | 关键词搜索 | 向量搜索 |
|---|---|---|
| "温润的手镯" | 匹配含"温润"和"手镯"的商品 | 匹配和田玉手镯 |
| "高货" | 匹配含"高货"的商品 | 匹配翡翠高品 |
| "送妈妈的礼物" | 几乎没结果 | 匹配适合送长辈的手镯 |
4.2 向量搜索原理
流程:文本 → Embedding 模型 → 1024 维向量 → KNN 搜索 → 返回结果。
步骤:1) 把用户输入转成向量;2) 在 ES 里用余弦相似度找最相似的 20 个商品;3) 用 min_score 阈值过滤。
4.3 EmbeddingService 实现
我们用阿里云百炼的 Embedding 接口。一次请求把文本转成 1024 维向量,耗时大概 100-200ms。
缓存策略:相同文本 10 分钟内重复查询直接返回缓存。
错误处理:向量生成失败了返回空数组,后面的 ES 查询就不做了,避免浪费资源。
vector = EmbeddingService.encode("翡翠手镯,种水细腻,色泽温润")
# => [0.023, -0.156, 0.089, ..., 0.012] (1024个浮点数)
4.4 商品向量同步 Job
商品上架后,AI 总结生成完成时自动触发向量生成。流程:
- 取商品的 AI 总结(必须是已生成的)
- 组合文本:商品标题 + AI 总结内容
- 调用 EmbeddingService 生成 1024 维向量
- 验证向量维度
- 同步到 ES 的
ai_summary_vector字段 - 标记生成时间
vector_generated_at
注意事项:版本冲突自动重试 3 次,失败了要报警。向量是预先生成的,搜索时直接用,不用实时生成。
4.5 ES KNN 查询构建
核心方法:
| 方法 | 作用 |
|---|---|
build_ai_knn_search_body |
构建 KNN 查询 Body |
extract_knn_filters |
提取过滤条件(排除关键词、圈口尺寸等) |
apply_filters_to_knn_query |
应用过滤条件 |
关键参数
-
k:返回多少条结果。翡翠设 30,玉石 25,钻石和彩宝设 20。翡翠商品多,设大一点有足够候选。 -
min_score:相似度阈值。翡翠设 0.85,玉石 0.8。翡翠商品描述比较标准化,设高一点不容易跑偏。
核心词加权:如果提取到核心词(如"翡翠"),生成向量时重复 3 次,让这个词权重更高。"翡翠手镯" → "翡翠 翡翠 翡翠 手镯" → 生成向量。
4.6 召回、排序、重排
召回流程
- 生成查询向量
- 用 HNSW 在向量空间里找最近的 k 个
- 应用
knn.filter过滤条件 - 计算余弦相似度,过滤低于
min_score的 - 返回商品 ID 列表
排序:目前只用 _score(相似度分数)降序,简单的做法,后续可以加其他排序维度。
重排:没有额外的重排逻辑,ES 返回什么顺序就是什么顺序。
4.7 完整 ES KNN 查询示例
{
"knn": {
"field": "ai_summary_vector",
"query_vector": [0.023, -0.156, 0.089, 0.234, -0.067, 0.178, ..., 0.012],
"k": 20,
"filter": {
"bool": {
"filter": [
{ "term": { "category_id": 1 } },
{ "term": { "status": "onsale" } },
{ "term": { "hide_in_miniprogram": false } },
{ "range": { "confirmed_price": { "gte": 5000, "lte": 7000 } } },
{ "range": { "inner_circle_size": { "gte": 55, "lte": 58 } } },
{ "exists": { "field": "ai_summary_vector" } }
],
"must_not": [
{ "match_phrase": { "goods_description_text": { "query": "镶嵌", "analyzer": "ik_max_word" } } }
]
}
}
},
"min_score": 0.8,
"from": 0,
"size": 10,
"sort": [
{ "_score": { "order": "desc" } },
{ "updated_at": { "order": "desc" } }
]
}
说明:过滤条件都在 knn.filter 里处理,在向量搜索阶段就过滤,减少计算量。
五、商品语义搜索模块详解
5.1 AiSearch 数据模型
AiSearch 表记录每次搜索的完整参数,搜索条件用 JSONB 存。为什么要冗余存一份 keywords_text?因为运营同学要统计数据,JSONB 查起来麻烦。每条记录关联 ai_chat_id 和 ai_chat_message_id,方便回溯"这条搜索结果是谁发的"。
主要字段
| 字段名 | 类型 | 说明 |
|---|---|---|
| msg_id | string | 消息 ID(唯一索引) |
| search_params | jsonb | 完整搜索参数 |
| keywords_text | string | 搜索关键词文本(冗余字段) |
| category | string | 商品分类(冗余字段) |
| price_min/max | decimal | 价格范围(冗余字段) |
| ai_chat_id | bigint | 关联的对话 ID |
| ai_chat_message_id | bigint | 关联的消息 ID |
使用场景:记录搜索参数支持"再次搜索",通过 ai_search_id 复用参数实现"查看更多",也支持搜索行为分析和统计。
5.2 API Controller 实现
POST /api/v1/products/ai_search
处理流程
- 参数校验:q 或 category_id 至少一个不为空
- 创建 AiSearch 记录,生成 ai_search_id
- 执行搜索:生成查询向量 → 构建 KNN 查询 → ES 查询
- 数据组装:从数据库捞商品详情,用 Presenter 格式化
- 返回结果:带 ai_search_id、total、products
成功返回
{
"success": true,
"data": {
"ai_search_id": "uuid",
"total": 15,
"products": [
{ "id": 12345, "title": "翡翠手镯", "price": 6000, ... }
]
}
}
错误返回
{
"success": false,
"error": "参数错误:q 或 category_id 不能为空"
}
curl 调用示例
curl -X POST "https://api.example.com/api/v1/products/ai_search" \
-H "X-Authorization: Bearer token" \
-H "Content-Type: application/json" \
-d '{"is_ai_search": true, "q": "翡翠手镯,5000-8000元", "category_id": 1, "price_min": 5000, "price_max": 8000}'
错误处理
| 错误类型 | 处理方式 |
|---|---|
| 参数校验失败 | 返回 400,提示具体错误信息 |
| 向量生成失败 | 记录日志,返回空结果 |
| ES 查询失败 | 返回 500,提示"搜索失败,请稍后重试" |
六、KNN 按分类配置
配置表:ai_search_knn_category_config
| 分类 ID | 分类名称 | k | min_score |
|---|---|---|---|
| 1 | 翡翠 | 30 | 0.85 |
| 2 | 玉石(和田玉等) | 25 | 0.8 |
| 3 | 钻石 | 20 | 0.82 |
| 4 | 彩宝 | 20 | 0.8 |
k:返回多少条结果。翡翠商品多,设 30;其他品类设 20-25。
min_score:相似度阈值。翡翠设 0.85 因为商品描述标准化,不容易跑偏;其他品类设 0.8。
调参建议:搜索结果太少就降 min_score 或增 k;结果不相关就提高 min_score。如果某个分类经常没结果,可以把 min_score 降 0.05-0.1。
七、常见问题与故障排查
7.1 SSE 连接问题
现象:SSE 连接建立失败或频繁断开
排查步骤
- 检查请求头:
Accept: text/event-stream - 检查 token:
X-Authorization: Bearer <token> - 检查网络和代理设置
- 看 Rails 日志里的错误信息
常见原因:token 过期或无效、网络超时(默认 60 秒)、服务器主动关闭连接。
7.2 向量生成失败
现象:搜索返回空结果
排查步骤
- 检查 Embedding 服务 API 是否可访问
- 检查 API 密钥是否有效
- 看 Rails 日志的错误信息
- 检查缓存是否正常(失败的请求也可能被缓存)
解决:向量失败会降级为返回空结果,检查 Embedding 服务配置和网络,清理缓存后重试。
7.3 Dify 工作流调用失败
现象:调用超时或返回错误
排查步骤
- 检查
DIFY_API_BASE_URL环境变量 - 检查
DIFY_CHATFLOW_API_KEY是否有效 - 检查 Dify 服务是否正常
- 看 Rails 日志的详细错误
常见错误:ConnectionError(连不上 Dify)、ResponseError(Dify 返回错误)、ParseError(响应解析失败)。
7.4 ES 查询慢
现象:查询超时或延迟高
排查步骤
- 检查 ES 集群状态和负载
- 检查索引分片和副本配置
- 检查
k值是否过大(建议不超过 50) - 检查 HNSW 参数
优化:适当降低 k、缩小 knn.filter 范围、检查 ES 集群资源。
7.5 搜索结果不相关
现象:返回的商品和用户需求不匹配
排查步骤
- 检查 Dify 提取的
q字段是否正确 - 检查 ES 里的
ai_summary_vector是否正常 - 检查
min_score阈值是否合适 - 检查核心词加权是否生效
解决:提高 min_score、检查商品 AI 总结质量、优化属性提取规则。
技术架构总结
┌─────────────────────────────────────────────────────────────
│ AI 找货助手技术架构
├─────────────────────────────────────────────────────────────
│ 前端层 → SSE 对话接口 → Dify 工作流 → 商品语义搜索接口
│ ↓
│ Elasticsearch KNN 搜索
│ ↓
│ 商品向量同步 + 查询向量生成
├─────────────────────────────────────────────────────────────
│ 核心流程:Dify 对话流 → 意图识别 → 属性提取 → 追问 → 搜索
│ 核心技术:SSE 实时推送 + 向量语义搜索 + HNSW 高性能索引
└─────────────────────────────────────────────────────────────