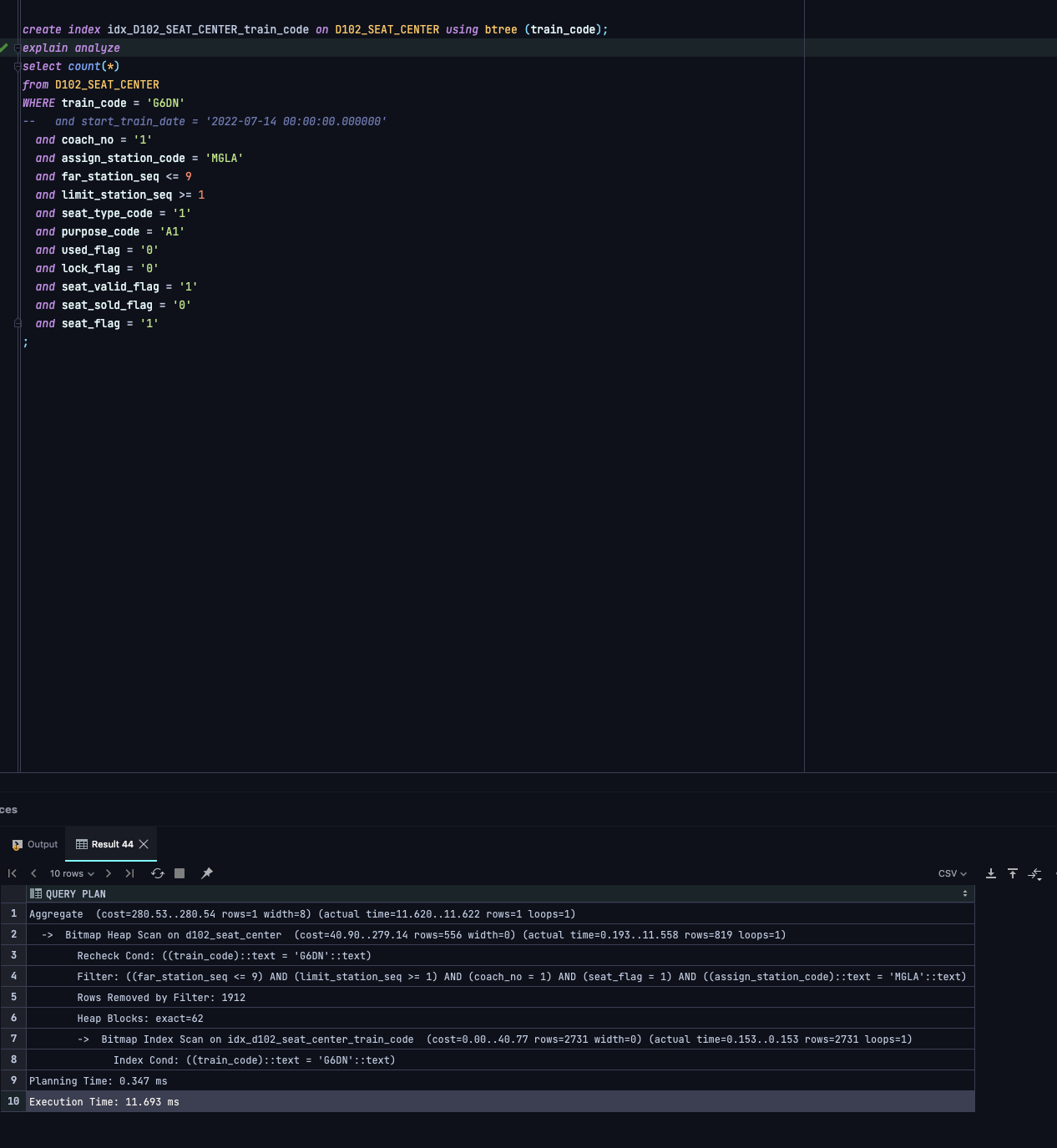
数据库 PostgreSQL 的执行计划,我想怎么看是否有回表
测试环境
| 环境 | 版本 |
|---|---|
| Postgres | v14 |
| DataGrip | 2022.1.5 |
测试脚本
https://chengsukai.oss-cn-hangzhou.aliyuncs.com/blog/d102_seat_center.sql
测试结果
| 环境 | 版本 |
|---|---|
| Postgres | v14 |
| DataGrip | 2022.1.5 |
https://chengsukai.oss-cn-hangzhou.aliyuncs.com/blog/d102_seat_center.sql